背景
在计算与存储一体化的情况,spark任务在调度task时会优先将其调度在数据所在的节点上或者相同的rack上,这样可以减少数据在不同节点或者不同rack上移动所带来的性能消耗;目前在Flink on yarn模式下,TaskExecutor的资源位置完全由yarn自主控制的,那么就可能会造成任务所在的节点与kafka数据所在的节点不在同一个机房,从而产生跨机房的流量消耗,在这样的一个环境背景下,需要将任务调度在数据所在机房,以减少流量消耗。(注:基于Flink-1.10.1)
Flink on Yarn调度流程
在Flink-1.9版本以前使用的调度模式是LAZY_FROM_SOURCES即以source-vertex为起始节点开始调度,当有数据输出到下游节点时开始调度下游的vertex,以这种方式部署所有的vertex;在1.9及1.9版本以后使用EAGER调度模式即会立刻调度所有的vertex。下面看一下具体的调度流程图:
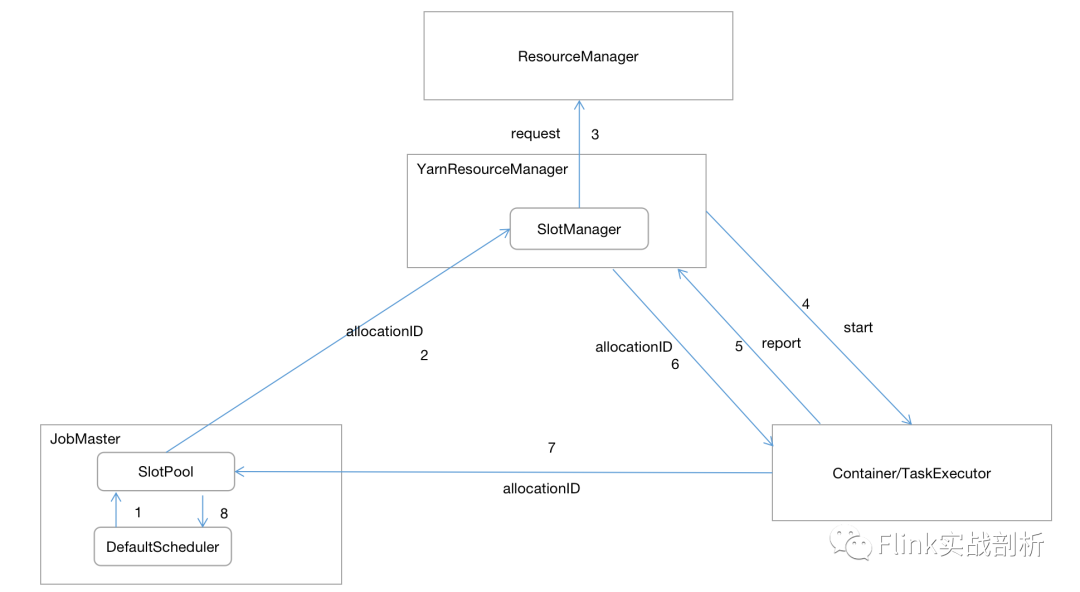
任务调度与部署是在JobMaster中通过DefaultScheduler完成,其会首先为所有的ExecutionVertex向SlotPoo(1)l申请资源然后部署,SlotPool会向ResourceManager中SlotManager(2)申请资源,如果没有可用的资源,那么就会向Yarn申请一个Container(3),待yarn分配了资源之后,回调给YarnResourceManager,进而启动TaskExecutor(4),TaskExecutor启动之后就会向YarnResourceManager汇报其资源情况(5),在YarnResourceManager进行资源匹配之后就会向TaskExecutor申请资源(6),然后TaskExecutor会将自身的资源分配给SlotPool(7), 最后告知给DefaultScheduler(8)将任务部署到对应的TaskExecutor上。至此完成一次完整的任务调度过程。
在SlotPool向SlotManager申请资源前,会生成一个AllocationId的唯一标识(资源ID),并且在申请的时候会将这个标识一起携带过去,当TaskExecutor向YarnResourceManager汇报自身资源情况时,在YarnResourceManager中会做一个资源请求(携带AllocationId)与实际资源匹配的过程,主要是通过资源大小(cpu、内存)匹配,匹配成功之后YarnResourceManager会向TaskExecutor发送一个申请slot请求(携带AllocationId),待请求成功之后TaskExecutor会将资源分配给对应的AllocationId的请求(7),完成资源匹配过程。
Locality 调度实现分析
通常Flink与kafka是部署在不同的集群上,这里所说的Locality仅仅是实现rack级别的调度,即将任务调度在kafka对应分区数据所在的rack上,为了实现此功能,分为以下几个步骤:
1)数据分配:Flink每一个Source-Task拉取partition是按照一定规则进行分配的,为了实现相同rack的partition在同一个task,因此需要改变其分配策略;为了保证每一个rack的数据都被消费到,需要对source并行度进行扩张,以前可能一个task消费所有rack的数据,现在需要每一个rack上的数据都有对应的task去拉取数据
实现:在flink-conf.yaml 中配置yarn集群机器分布情况,包括ip以及对应的rack信息,那么任务启动会获取这些信息;在StreamGraphGenerator中的transformSource方法提前生成每个source-task消费的对应topic与partition信息,以及其需要调度到的rack信息。这里主要说明一下目前的分配策略:
例如:有a,b,c 三个rack, topic1对应partition:[0,1,2,3,4,5], 可通过KafkaConsumer的partitionsFor方法获取对应的partition信息,parition的分布情况是:a ->[0,1],b->[2,3],c->[4,5]
如果设置的并行度为:1 ,则分配规则是:task0(a)->[0,1],task1(b)->[2,3],task2(c)->[4,5]
如果设置的并行度为:4 ,则分配规则是:task0(a)->[0],task1(b)->[2],task2(c)->[4],task3(a)->[1],task4(b)->[3],task5(c)->[5]
注:task0 表示下标为0的task
扩充规则是:userSourceParallelism%numRack==0?userSourceParallelism:(1+userSourceParallelism/numRack)*numRack, 即生成的并行度是rack个数的整数倍。
生成的配置放在ExecutionConfig中的GlobalParameters中,实际效果图:

代表着下标为0的task消费partition-2,同时部署在rack-a中的机器上,下标为1的task消费partition-1,同时部署在rack-b的机器上,下标为2的task消费partition-0,同时部署在rack-c中的机器上。
2)资源申请:默认情况下在Flink向Yarn申请资源是不携带任何NodeManager信息的,通常需要向yarn申请资源的流程是当遇到新的Source-Task时才会去走这个流程(根据slot-shared机制),因此只需要在Source对应的ExecutionVetex上打上对应的rack标签即可,将这个rack一直传递到YarnResourceManager端,然后获取该rack对应的机器,从这些机器上申请资源。
实现:在申请资源前会给ExecutionVertex配置相关的资源信息,在ExecutionVertexSchedulingRequirementsMapper.getPhysicalSlotResourceProfile中完成,因此在这里对ExecutionVertex的资源信息打上rack信息
boolean hasNoConnectedInputs=
executionVertex.getJobVertex().getJobVertex().hasNoConnectedInputs();
if(hasNoConnectedInputs){
try{
int index=executionVertex.getParallelSubtaskIndex();
ExecutionConfig executionConfig=executionVertex.getJobVertex().getJobVertex().getJobGraph().getExecutionConfig();
Map<String,String> map=executionConfig.getGlobalJobParameters().toMap();
String index2Zone=map.get("index2Zone");
String zone="";
ObjectMapper objectMapper=new ObjectMapper();
//index 表示该ExecutionVertext的下标Index
zone=objectMapper.readTree(index2Zone).findValue(String.valueOf(index)).asText();
//赋予区域信息
ResourceProfile resourceProfile1=resourceProfile.copy2ZoneUnknown(resourceProfile,zone);
LOG.debug("vertexName:{},ResourceProfile:{}",executionVertex.getJobVertex().getName(),resourceProfile1);
return resourceProfile1;
}catch (Throwable e){
LOG.error("parse resourceProfile error:{}",e);
}
}
在这里重新定义了ResourceProfile,赋予了其rack信息,ResourceProfile会一直传递到YarnResourceManager资源申请端:
public Collection<ResourceProfile> startNewWorker(ResourceProfile resourceProfile) {
if (!resourceProfilesPerWorker.iterator().next().isMatching(resourceProfile)) {
return Collections.emptyList();
}
//zone 表示 rack信息
String zone=resourceProfile.getZone();
if(zone!=null){
requestYarnContainer(zone);
}else{
requestYarnContainer();
}
return resourceProfilesPerWorker;
}
重新定义了requestYarnContainer流程,使请求包含rack信息:
AMRMClient.ContainerRequest getContainerRequest(String zone) {
String[] ipList= ResourceManager.ZONE_IPS.get(zone).split(",");//获取该rack下的所有iplist
LOG.debug("request slot from [{}] for zone [{}]",ipList,zone);
AMRMClient.ContainerRequest request= new AMRMClient.ContainerRequest(
getContainerResource(),
ipList,
null,
RM_REQUEST_PRIORITY,false);//false:RelaxLocality表示不允许资源降级申请,一定要使其分布在指定的机器上
containerRequestList.add(request);
return request;
}
由于yarn返回的是一个满足请求的一个资源集合,因此需要在满足的集合中做资源过滤,将多余资源返回给yarn,因此在回调方法onContainersAllocated中:
public void onContainersAllocated(List<Container> containers) {
runAsync(() -> {
log.info("Received {} containers with {} pending container requests.", containers.size(), numPendingContainerRequests);
//final Collection<AMRMClient.ContainerRequest> pendingReques ts = getPendingRequests();
//请求到的host
List<String> requestedHost=new ArrayList<>();
containers.stream().map(container -> container.getNodeId().getHost()).forEach(requestedHost::add);
//获取满足匹配的请求
final Collection<AMRMClient.ContainerRequest> pendingRequests=containerRequestList.stream().map(containerRequest -> Tuple2.of(containerRequest.getNodes(),containerRequest))
.filter(tuple2->
requestedHost.stream().filter(host->tuple2.f0.contains(host))
.count()>0
)
.map(map->map.f1).collect(Collectors.toList());
int matchRequest=pendingRequests.size();
log.info("recevied container size : {}, matching request:{}",containers.size(),matchRequest);
final Iterator<AMRMClient.ContainerRequest> pendingRequestsIterator = pendingRequests.iterator();
// number of allocated containers can be larger than the number of pending container requests
//final int numAcceptedContainers = Math.min(containers.size(), numPendingContainerRequests);
final int numAcceptedContainers = Math.min(matchRequest, numPendingContainerRequests);
final List<Container> requiredContainers = containers.subList(0, numAcceptedContainers);
final List<Container> excessContainers = containers.subList(numAcceptedContainers, containers.size());
for (int i = 0; i < requiredContainers.size(); i++) {
//removeContainerRequest(pendingRequestsIterator.next());
AMRMClient.ContainerRequest needRemoveRequest=pendingRequestsIterator.next();
containerRequestList.remove(needRemoveRequest);
removeContainerRequest(needRemoveRequest);
}
//返回多余的资源
excessContainers.forEach(this::returnExcessContainer);
requiredContainers.forEach(this::startTaskExecutorInContainer);
// if we are waiting for no further containers, we can go to the
// regular heartbeat interval
if (numPendingContainerRequests <= 0) {
resourceManagerClient.setHeartbeatInterval(yarnHeartbeatIntervalMillis);
}
});
}
3) 资源匹配:默认情况下,在YarnResourceManager中做分配到的资源与申请的资源匹配时是按照大小进行的,因此需要改为按照rack进行匹配
实现:匹配的流程在SlotManager.findExactlyMatchingPendingTaskManagerSlot中:
private PendingTaskManagerSlot findExactlyMatchingPendingTaskManagerSlot(ResourceProfile resourceProfile,String zone) {
for (PendingTaskManagerSlot pendingTaskManagerSlot : pendingSlots.values()) {
LOG.info("zone:{},request_zone:{}",zone,pendingTaskManagerSlot.getResourceProfile().getZone());
/**
* 区域匹配
*/
if(zone.equals(pendingTaskManagerSlot.getResourceProfile().getZone())){
LOG.debug("get resource zone:{},resourceProfile:{}",zone,pendingTaskManagerSlot.getResourceProfile());
return pendingTaskManagerSlot;
}
完成了这个资源匹配过程,并且在后续的流程中由AllocationId完成资源与具体的ExecutionVertex请求匹配,就可以将ExecutionVertex部署到匹配的机器上。
4) 指定source的消费数据:在数据分配中已经将每个task消费的数据指定好了,因此在source端只需要获取对应的分区信息即可,同时需要放弃默认的分配策略
实现:FlinkKafkaConsumerBase.open 中:
final List<KafkaTopicPartition> allPartitions = new ArrayList<>();
//从配置里面获取
Map<String,String> globalMaps=getRuntimeContext().getExecutionConfig().getGlobalJobParameters().toMap();
String index2TopicPartitionsStr=globalMaps.get("index2TopicPartitions");
ObjectMapper objectMapper=new ObjectMapper();
JsonNode rootNode=objectMapper.readTree(index2TopicPartitionsStr);
JsonNode topicPartitionNode=rootNode.findValue(String.valueOf(getRuntimeContext().getIndexOfThisSubtask()));
topicPartitionNode.fieldNames().forEachRemaining(topic->{
JsonNode partitionsNode=topicPartitionNode.findValue(topic);
partitionsNode.iterator().forEachRemaining(jsonNode -> {
allPartitions.add(new KafkaTopicPartition(topic,jsonNode.asInt()));
});
});
allPartitions.stream().forEach(x->{
LOG.debug("consumer topic:{}, partition:{}",x.getTopic(),x.getPartition());
});
allPartitions 就代表了该task需要消费的数据。
至此整个流程完成。
总结
在实现该方案前,也做过在任务调度后直接在FlinkKafkaConsumerBase中自定义partition的分配,即根据机器的所在rack去获取对应的rack上的数据,但是经常会出现有数据的rack上没有对应的rack任务,只能做降级处理,将这些rack上的分区数据分配给其他rack上的任务,仍然会有部分的数据跨机房拉取,流量成本消耗缩减效果并不好,因此才做了这个Locality的方案,由于涉及的内容比较多,本文只提供了一个实现的思路与关键的部分代码。目前的实现方案仍然存在以下几个限制:
1.一个任务只能消费一个kafka集群的数据,由于slot-share机制,不同的JobVertext可以分配到同一个Slot上,如果有多个kafka集群的话,source就会对应多个JobVertex,那么在后续的JobVertext在申请资源的时候就会寻找前面已经申请到资源的JobVertext,很有可能会匹配到其他的rack的资源,目前并未对这块进行改造。
2.一个TaskExecutor只分配一个Slot,如果有多个slot的话,第一次申请后,后续SlotPool向YarnResourceManager申请资源时,直接发现有可用的Slot就会直接分配,很有可能会匹配到其他的rack的资源,目前并未对这块进行改造。
3.如果topic的partition在rack分配不均匀,可能会造成流量倾斜,因此需要在topic创建中做好partition的分布。
4.由于source-vertext的扩充,会导致需要的资源变多,因此需要在cpu/内存与流量成本消耗之间权衡。
目前在使用上主要是针对大的topic采取该方案,流量成本也有很显著的缩减效果,后续会对以上问题进行优化。

最后
以上就是整齐学姐最近收集整理的关于Flink 实现Locality 模式调度的全部内容,更多相关Flink内容请搜索靠谱客的其他文章。








发表评论 取消回复