如果经常做大数据相关的工作,那么,分布式的程序是必不可少的,只有非常清晰的了解,大数据框架的调度流程及核心原理,才能写出高效的程序。所以,最近梳理下spark的调度流程。可能不是特别深入,但是,是自己逐步深入学习的基础。如果恰好能帮助到你的话,那是我的荣幸!
spark是什么?
Apache Spark™ is a unified analytics engine for large-scale data processing.
这是官网的一句话,spark是一个统一的大数据处理引擎。
它内部集成了很多处理模块,以及机器学习模块。所以spark现在是一个比较常用的大数据分布式处理引擎。
所以,spark的任务调度流程的理解是十分重要的,下面将介绍一些核心的概念,然后数量任务调度的流程。
核心概念
-
1.Spark Application: 指用户编写的Spark应用程序,其中包括一个Driver部分的功能代码和分布在集群中多个节点上运行的Executor代码。是一个统称。
-
2. Driver: Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver。它是spark任务的管理者。
-
3. Executor: 某个Application运行在worker节点上的一个进程, 该进程负责运行某些Task, 并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor, 在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个CoarseGrainedExecutor Backend能并行运行Task的数量取决与分配给它的cpu个数。
下图是spark官网的示意图,我们可以梳理到drive和其他几个概念之间的关系:
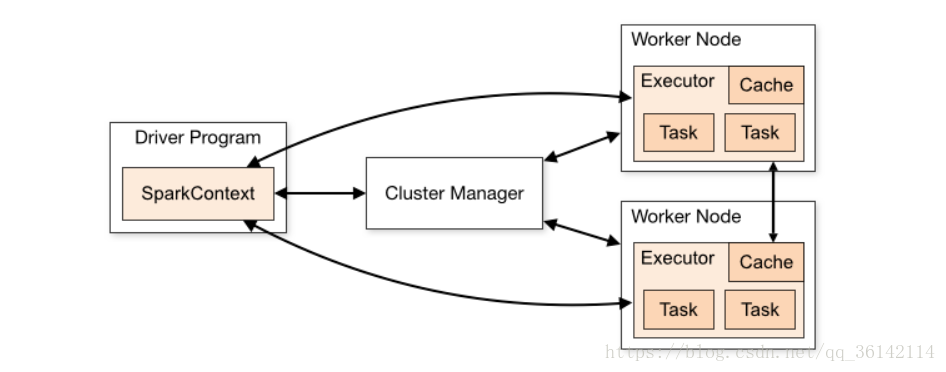
-
4. Cluter Manager:指的是在集群上获取资源的外部服务。目前有三种类型
- Standalon : spark原生的资源管理,由Master负责资源的分配
- Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
- Hadoop Yarn: 主要是指Yarn中的ResourceManager
-
5. Worker: 集群中任何可以运行Application代码的节点,在Standalone模式中指的是通过slave文件配置的Worker节点,在Spark on Yarn模式下就是NoteManager节点
-
6. Task: 某个Executor上的工作单元,和hadoop MapReduce中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责
-
7. Job: 包含多个Task组成的并行计算,往往由Spark Action触发生成, 一个Application中往往会产生多个Job
-
8. Stage: 每个Job会被拆分成多组Task, 作为一个TaskSet, 其名称为Stage,Stage的划分和调度是有DAGScheduler来负责的,Stage有非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage)两种,Stage的边界就是发生shuffle的地方
-
9. DAGScheduler: 根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),并提交Stage给TASkScheduler。 其划分Stage的依据是RDD之间的宽窄依赖关系找出开销最小的调度方法。
-
10. TASKSedulter: 将Taskset提交给worker运行,每个Executor运行什么Task就是在此处分配的. TaskScheduler维护所有TaskSet,当Executor向Driver发生心跳时,TaskScheduler会根据资源剩余情况分配相应的Task。另外TaskScheduler还维护着所有Task的运行标签,重试失败的Task。
TASKSedulter与Driver和executor之间的关系示意图如下:
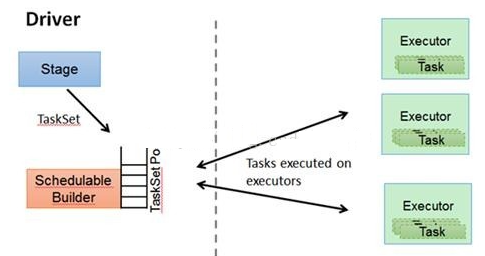
调度流程
这是一张从网上找到的调度流程图,我感觉写的还是很全面的可以参考学习:
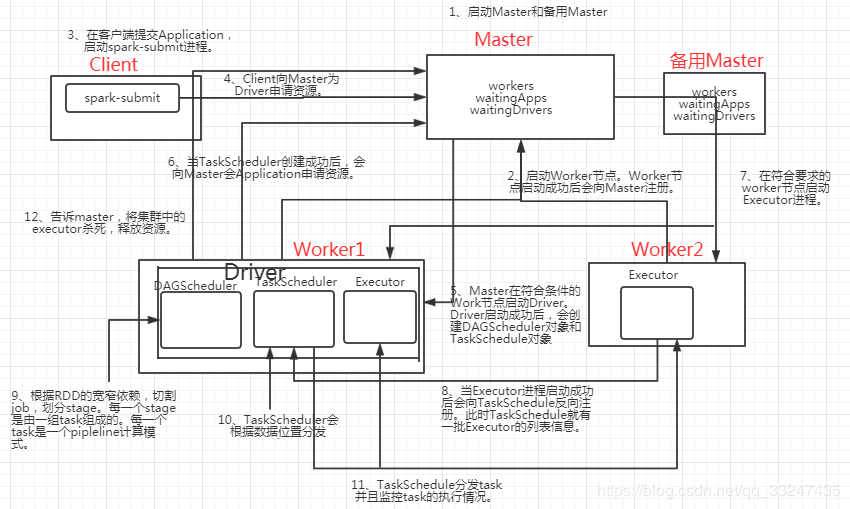
流程描述如下:
1.master节点及worker节点的启动,这个与spark无关,是属于集群的任务,如果你用的spark on yarn 那么就是yarn的任务。yarn需要启动AM和NM等,为任务准备好调度环节。
2.client也就是用户,提交任务。也就是我们的spark-submit。它会创建我们的application。
3.资源请求,也就是和调度系统master请求资源。master根据第一次情况的情况,分配第一个worker,来启动整个application的driver进程,负责整个application的任务管理。
4.Driver再次向master申请,任务执行所需要的资源。
5.master 将符合条件的worker上启动executor进程。
6.TASKSedulter进程启动,来管理taskSet,了解executor信息
7.spark启动DAGScheduler进程,根据宽窄依赖进行stage划分。每一个task是一个pipeline(管道)。
8.TASKSedulter进行任务分发,及进行任务监控,汇报执行情况信息。
9.执行完毕后,Driver汇报结果,master杀死executor,释放资源。
参数设置
1.num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
常用的计算公式是:
executor 数量 = spark.cores.max/spark.executor.cores
其中:
spark.cores.max 是指你的spark程序需要的总核数
spark.executor.cores 是指每个executor需要的核数
2.executor-memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G-8G较为合适。但是这只是一个参考值,具体的设置还是得根据资源队列来定。num-executors乘以executor-memory,就代表了你的Spark任务将申请到的总内存量(也就是所有Executor进程的内存总和),这个量是不能超过队列的最大内存量的。否则会报错。
还有要考虑队列资源其他人的使用情况,不能独占资源,影响其他业务。
3.executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2-4个较为合适。也要根据资源情况,进行调整。如果是共享资源,那么建议,num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同事的任务运行。
4.spark.default.parallelism
参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:Spark作业的默认task数量为500-1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
重点:
1.executor 是属于一个沙箱的概念,他的内存情况是相对的,是临时隔离起来的一个空间。
2.task是以管道pipeline的形式执行的。
3.数据会被切分为很多partition,那么,每个partition的数据会在一个task上执行。是任务执行的最小单元,相当于我们的机器单机执行。
参考文献:
1.https://blog.csdn.net/qq_33247435/article/details/83960291
2.http://spark.apache.org/
3.https://blog.csdn.net/QQ1131221088/article/details/88982338
4.https://blog.csdn.net/SunWuKong_Hadoop/article/details/53940132
最后
以上就是受伤衬衫最近收集整理的关于spark任务调度流程梳理spark是什么?核心概念调度流程参数设置重点:参考文献:的全部内容,更多相关spark任务调度流程梳理spark是什么内容请搜索靠谱客的其他文章。








发表评论 取消回复