前言
限流器,顾名思义用来对高并发的请求进行流量限制的组件。
限流包括 Nginx 层面的限流以及业务代码逻辑上的限流。流量的限制在众多微服务和 service mesh 中多有应用。限流主要有三种算法:信号量、漏桶算法和令牌桶算法。下面依次介绍这三种算法。
笔者在本文的程序示例均以 Go 语言实现。
1. 问题描述
用户增长过快、热门业务或者爬虫等恶意攻击行为致使请求量突然增大,比如学校的教务系统,到了查分之日,请求量涨到之前的 100 倍都不止,没多久该接口几乎不可使用,并引发连锁反应导致整个系统崩溃。如何应对这种情况呢?生活给了我们答案:比如老式电闸都安装了保险丝,一旦有人使用超大功率的设备,保险丝就会烧断以保护各个电器不被强电流给烧坏。同理我们的接口也需要安装上“保险丝”,以防止非预期的请求对系统压力过大而引起的系统瘫痪,当流量过大时,可以采取拒绝或者引流等机制。
后端服务由于各个业务的不同和复杂性,各自在容器部署的时候都可能会有单台的瓶颈,超过瓶颈会导致内存或者 cpu 的瓶颈,进而导致发生服务不可用或者单台容器直接挂掉或重启。
2. 信号量限流
信号量在众多开发语言中都会有相关信号量的设计。如 Java 中的Semaphore 是一个计数信号量。常用于限制获取某资源的线程数量,可基于 Java 的 concurrent 并发包实现。
信号量两个重要方法 Acquire() 和 Release()。通过acquire()方法获取许可,该方法会阻塞,直到获取许可为止。通过release()方法释放许可。
笔者在阅读一些语言开源实现后,总结出信号量的主要有非阻塞和阻塞两种。
2.1 阻塞方式
采用锁或者阻塞队列方式,以 Go 语言为示例如下:
// 采用channel作为底层数据结构,从而达到阻塞的获取和使用信号量
type Semaphore struct {
innerChan chan struct{}
}
// 初始化信号量,本质初始化一个channel,channel的初始化大小为 信号量数值
func NewSemaphore(num uint64) *Semaphore {
return &Semaphore{
innerChan: make(chan struct{}, num),
}
}
// 获取信号量,本质是 向channel放入元素,如果同时有很多协程并发获取信号量,则channel则会full阻塞,从而达到控制并发协程数的目的,也即是信号量的控制
func (s *Semaphore) Acquire() {
for {
select {
case s.innerChan <- struct{}{}:
return
default:
log.Error("semaphore acquire is blocking")
time.Sleep(100 * time.Millisecond)
}
}
}
// 释放信号量 本质是 从channel中获取元素,由于有acquire的放入元素,所以此处一定能回去到元素 也就能释放成功,default只要是出于安全编程的目的
func (s *Semaphore) Release() {
select {
case <-s.innerChan:
return
default:
return
}
}
在实现中,定义了 Semaphore 结构体。初始化信号量,本质是初始化一个channel,channel 的初始化大小为信号量数值;获取信号量,本质是向channel放入元素,如果同时有很多协程并发获取信号量,则 channel 则会 full 阻塞,从而达到控制并发协程数的目的,也即是信号量的控制;释放信号量的本质是从channel中获取元素,由于有acquire的放入元素,所以此处一定能回去到元素 也就能释放成功,default只要是出于安全编程的目的。
2.2 非阻塞方式
以并发安全的计数方式比如采用原子 atomic 加减进行。
3. 限流算法
主流的限流算法分为两种漏桶算法和令牌桶算法,关于这两个算法有很多文章和论文都给出了详细的讲解。从原理上看,令牌桶算法和漏桶算法是相反的,一个 进水,一个是 漏水。值得一提的是 Google Guava 开源和 Uber 开源限流组件均采用漏桶算法。
3.1 漏桶算法
漏桶(Leaky Bucket)算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率)然后就拒绝请求。可以看出漏桶算法能强行限制数据的传输速率。示意图如下:
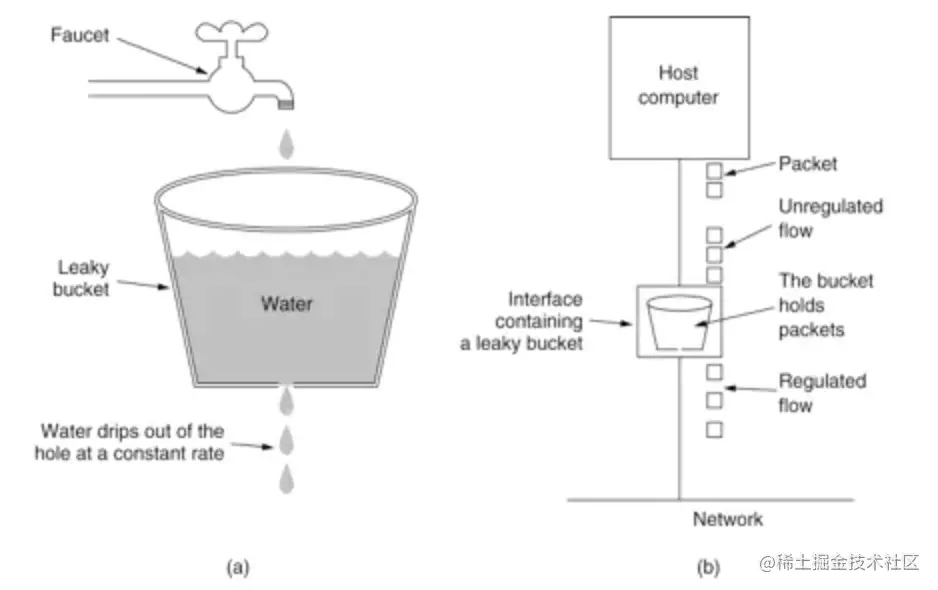
可见这里有两个变量,一个是桶的大小,支持流量突发增多时可以存多少的水(burst),另一个是水桶漏洞的大小(rate)。
漏桶算法可以使用 redis 队列来实现,生产者发送消息前先检查队列长度是否超过阈值,超过阈值则丢弃消息,否则发送消息到 Redis 队列中;消费者以固定速率从 Redis 队列中取消息。Redis 队列在这里起到了一个缓冲池的作用,起到削峰填谷、流量整形的作用。
3.2 令牌桶算法
对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。桶里能够存放令牌的最高数量,就是允许的突发传输量。
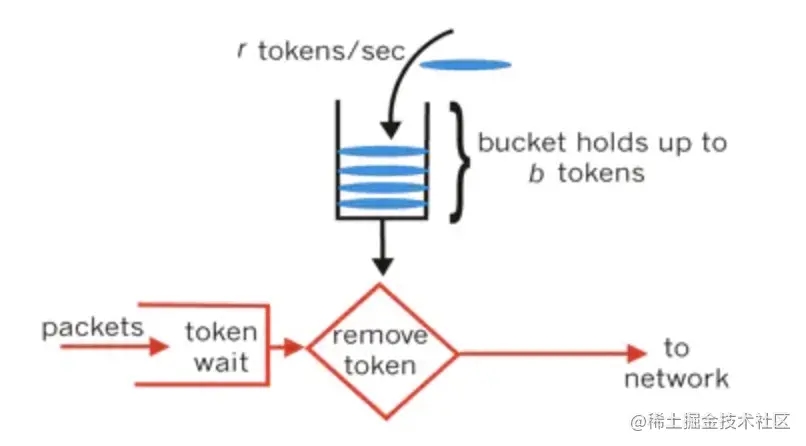
放令牌这个动作是持续不断的进行,如果桶中令牌数达到上限,就丢弃令牌,所以就存在这种情况,桶中一直有大量的可用令牌,这时进来的请求就可以直接拿到令牌执行,比如设置qps为100,那么限流器初始化完成一秒后,桶中就已经有100个令牌了,等启动完成对外提供服务时,该限流器可以抵挡瞬时的100个请求。所以,只有桶中没有令牌时,请求才会进行等待,最后相当于以一定的速率执行。
可以准备一个队列,用来保存令牌,另外通过一个线程池定期生成令牌放到队列中,每来一个请求,就从队列中获取一个令牌,并继续执行。
3.3 漏桶算法的实现
所以此处笔者开门见山,直接展示此算法的 Go 语言版本的实现,代码如下:
// 此处截取自研的熔断器代码中的限流实现,这是非阻塞的实现
func (sp *servicePanel) incLimit() error {
// 如果大于限制的条件则返回错误
if sp.currentLimitCount.Load() > sp.currLimitFunc(nil) {
return ErrCurrentLimit
}
sp.currentLimitCount.Inc()
return nil
}
func (sp *servicePanel) clearLimit() {
// 定期每秒重置计数器,从而达到每秒限制的并发数
// 比如限制1000req/s,在这里指每秒清理1000的计数值
// 令牌桶是定期放,这里是逆思维,每秒清空,实现不仅占用内存低而且效率高
t := time.NewTicker(time.Second)
for {
select {
case <-t.C:
sp.currentLimitCount.Store(0)
}
}
}
上述的实现实际是比较粗糙的实现,没有严格按照每个请求方按照某个固定速率进行,而是以秒为单位,粗粒度的进行计数清零,这其实会造成某个瞬间双倍的每秒限流个数,虽然看上去不满足要求,但是在这个瞬间其实是只是一个双倍值,正常系统都应该会应付一瞬间双倍限流个数的请求量。
改进
如果要严格的按照每个请求按照某个固定数值进行,那么可以改进时间的粗力度,具体做法如下:
func (sp *servicePanel) incLimit() error {
// 如果大于1则返回错误
if sp.currentLimitCount.Load() > 1 {
return ErrCurrentLimit
}
sp.currentLimitCount.Inc()
return nil
}
func (sp *servicePanel) clearLimit() {
// 1s除以每秒限流个数
t := time.NewTicker(time.Second/time.Duration(sp.currLimitFunc(nil)))
for {
select {
case <-t.C:
sp.currentLimitCount.Store(0)
}
}
}
读者可以自行尝试一下改进之后的漏斗算法。
4. Uber 开源实现 RateLimit 深入解析
uber 在 Github 上开源了一套用于服务限流的 go 语言库 ratelimit, 该组件基于 Leaky Bucket(漏桶)实现。
4.1 引入方式
#第一版本 go get github.com/uber-go/ratelimit@v0.1.0 #改进版本 go get github.com/uber-go/ratelimit@master
4.2 使用
首先强调一点,跟笔者自研的限流器最大的不同的是,这是一个阻塞调用者的限流组件。限流速率一般表示为 rate/s 即一秒内 rate 个请求。先不多说,进行一下用法示例:
func ExampleRatelimit() {
rl := ratelimit.New(100) // per second
prev := time.Now()
for i := 0; i < 10; i++ {
now := rl.Take()
if i > 0 {
fmt.Println(i, now.Sub(prev))
}
prev = now
}
}
预期的结果如下:
// Output:
// 1 10ms
// 2 10ms
// 3 10ms
// 4 10ms
// 5 10ms
// 6 10ms
// 7 10ms
// 8 10ms
// 9 10ms
测试结果完全符合预期。在这个例子中,我们给定限流器每秒可以通过100个请求,也就是平均每个请求间隔10ms。因此,最终会每10ms打印一行数据。
构造限流器
首先是构造一个Limiter 里面有一个 perRequest 这是关键的一个变量,表示每个请求之间相差的间隔时间,这是此组件的算法核心思想,也就是说将请求排队,一秒之内有rate个请求,将这些请求排队,挨个来,每个请求的间隔就是1s/rate 从来达到 1s内rate个请求的概念,从而达到限流的目的。
// New returns a Limiter that will limit to the given RPS.
func New(rate int, opts ...Option) Limiter {
l := &limiter{
perRequest: time.Second / time.Duration(rate),
maxSlack: -10 * time.Second / time.Duration(rate),
}
for _, opt := range opts {
opt(l)
}
if l.clock == nil {
l.clock = clock.New()
}
return l
}
限流器Take() 阻塞方法
Take() 方法 每次请求前使用,用来获取批准 返回批准时刻的时间。
第一版本
// Take blocks to ensure that the time spent between multiple
// Take calls is on average time.Second/rate.
func (t *limiter) Take() time.Time {
t.Lock()
defer t.Unlock()
now := t.clock.Now()
// If this is our first request, then we allow it.
if t.last.IsZero() {
t.last = now
return t.last
}
// sleepFor calculates how much time we should sleep based on
// the perRequest budget and how long the last request took.
// Since the request may take longer than the budget, this number
// can get negative, and is summed across requests.
t.sleepFor += t.perRequest - now.Sub(t.last)
// We shouldn't allow sleepFor to get too negative, since it would mean that
// a service that slowed down a lot for a short period of time would get
// a much higher RPS following that.
if t.sleepFor < t.maxSlack {
t.sleepFor = t.maxSlack
}
// If sleepFor is positive, then we should sleep now.
if t.sleepFor > 0 {
t.clock.Sleep(t.sleepFor)
t.last = now.Add(t.sleepFor)
t.sleepFor = 0
} else {
t.last = now
}
return t.last
}
在实现方面,可以看到第一版本采用了 Go 的 lock,然后排队 sleep,完成 sleep 之后,请求之间的间隔时间恒定,单位时间之内有设定好的请求数,实现限流的目的。
第二版本
// Take blocks to ensure that the time spent between multiple
// Take calls is on average time.Second/rate.
func (t *limiter) Take() time.Time {
newState := state{}
taken := false
for !taken {
now := t.clock.Now()
previousStatePointer := atomic.LoadPointer(&t.state)
oldState := (*state)(previousStatePointer)
newState = state{}
newState.last = now
// If this is our first request, then we allow it.
if oldState.last.IsZero() {
taken = atomic.CompareAndSwapPointer(&t.state, previousStatePointer, unsafe.Pointer(&newState))
continue
}
// sleepFor calculates how much time we should sleep based on
// the perRequest budget and how long the last request took.
// Since the request may take longer than the budget, this number
// can get negative, and is summed across requests.
newState.sleepFor += t.perRequest - now.Sub(oldState.last)
// We shouldn't allow sleepFor to get too negative, since it would mean that
// a service that slowed down a lot for a short period of time would get
// a much higher RPS following that.
if newState.sleepFor < t.maxSlack {
newState.sleepFor = t.maxSlack
}
if newState.sleepFor > 0 {
newState.last = newState.last.Add(newState.sleepFor)
}
taken = atomic.CompareAndSwapPointer(&t.state, previousStatePointer, unsafe.Pointer(&newState))
}
t.clock.Sleep(newState.sleepFor)
return newState.last
}
第二版本采用原子操作+for的自旋操作来替代lock操作,这样做的目的是减少协程锁竞争。 两个版本不管是用锁还是原子操作本质都是让请求排队,第一版本存在锁竞争,然后排队sleep,第二版本避免锁竞争,但是所有协程可能很快跳出for循环然后都会在sleep处sleep。
小结
保障服务稳定的三大利器:熔断降级、服务限流和故障模拟。本文主要讲解了分布式系统中高可用的常用策略:限流。限流通常有三种实现:信号量(计数器)、漏桶、令牌桶。本文基于漏桶算法实现了一个限流小插件。最后分析了 uber 开源的 uber-go,限流器 Take() 阻塞方法的第二版本对协程锁竞争更加友好。
参考 https://www.uoften.com/article/251947.htm
以上就是Go实现分布式系统高可用限流器实战的详细内容,更多关于Go分布式系统高可用限流器的资料请关注靠谱客其它相关文章!
最后
以上就是机智曲奇最近收集整理的关于Go实现分布式系统高可用限流器实战的全部内容,更多相关Go实现分布式系统高可用限流器实战内容请搜索靠谱客的其他文章。








发表评论 取消回复