使用WebClient和htmlunit实现简易爬虫
import com.gargoylesoftware.htmlunit.WebClient;
提供了public
P getPage(final String url)方法获得HtmlPage。
import com.gargoylesoftware.htmlunit.html.*;
包含了HtmlPage、HtmlForm、HtmlTextInput、HtmlPasswordInput、HtmlElement、DomElement等元素。
构造webclient对象
WebClient webClient= new WebClient();
无参默认是BrowserVersion.BEST_SUPPORTED,有参构造支持5种浏览器:
BrowserVersion.CHROME
BrowserVersion.EDGE
BrowserVersion.FIREFOX
BrowserVersion.FIREFOX_78
BrowserVersion.INTERNET_EXPLOER
使用webclient.getPage(String url)获得页面:
try {
page = webClient.getPage(url);
} catch (IOException e) {
e.printStackTrace();
}
利用webClient.getPage(url);方法,将其封装成一个getHtmlPage静态方法
private static class innerWebClient{
private static final WebClient webClient = new WebClient();
}
public static HtmlPage getHtmlPage(String url){
//调用此方法时加载WebClient
WebClient webClient = innerWebClient.webClient;
webClient.getOptions().setCssEnabled(false);
//配置webClient
webClient.getOptions().setCssEnabled(false); //设置CSS是否生效
webClient.getOptions().setJavaScriptEnabled(true); //设置JS是否生效
webClient.setAjaxController(new NicelyResynchronizingAjaxController()); //设置AJAX请求
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false); //设置是否抛出异常码
webClient.getOptions().setThrowExceptionOnScriptError(false); //设置是否抛出脚本错误
webClient.waitForBackgroundJavaScript(3*1000); //设置等待JS毫秒数
webClient.getCookieManager().setCookiesEnabled(true); //设置是否支持Cookie
HtmlPage page = null;
try {
page = webClient.getPage(url);
} catch (IOException e) {
e.printStackTrace();
}
return page;
}
在教务官网学期课表页,拿到对应标签的ID

登录教务官网页面:
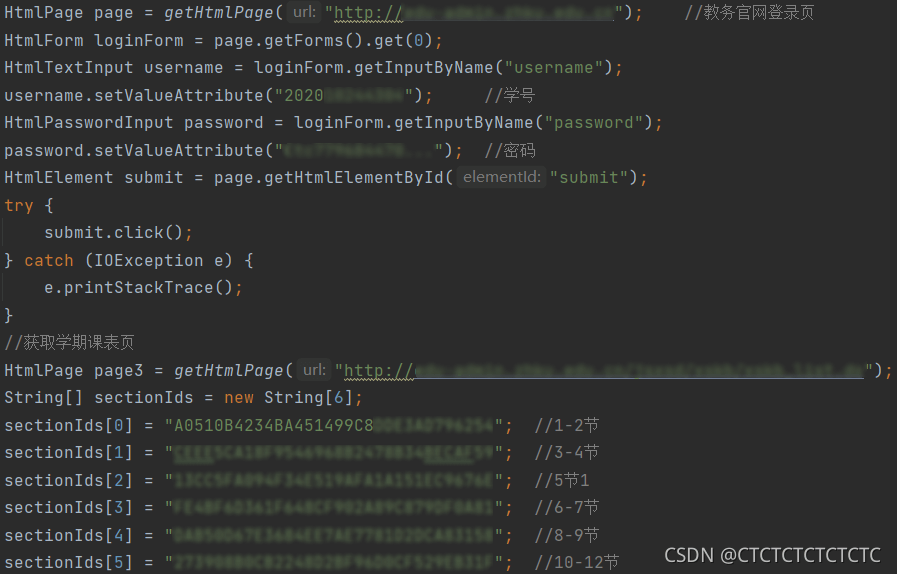
静态解析课程信息方法:
//获取周次集合
public static ArrayList<Integer> getWeekCount(String weekAndSection){
ArrayList<Integer> weekList = new ArrayList<>();
int index = weekAndSection.indexOf("(周)");
if(index == -1){
return new ArrayList<>();
}
String subWeek = weekAndSection.substring(0, index); //1-3,5,15,18
String[] weekArr = new String[10];
int idx = subWeek.indexOf(","); //1或3
int num = 0,n = 0;
while (subWeek.contains(",")){
weekArr[num] = subWeek.substring(0,idx); //第一个逗号前面的内容,给数组
subWeek = subWeek.substring(idx+1); //剩余内容
n = subWeek.indexOf(",");
idx = n;
num++;
}
weekArr[num] = subWeek;
for (String s : weekArr) {
if(s!=null && !s.equals("")){
if(s.contains("-")){
int ix = s.indexOf("-");
int begin = Integer.parseInt(s.substring(0,ix));
int end = Integer.parseInt(s.substring(ix+1));
for (int i = begin; i <= end; i++) {
weekList.add(i);
}
}else{
weekList.add(Integer.parseInt(s));
}
}
}
return weekList;
}
//获取节次集合
public static ArrayList<Integer> getSectionCount(String weekAndSection){
int begin = weekAndSection.indexOf("[") + 1;
int end = weekAndSection.indexOf("节");
String section = weekAndSection.substring(begin, end);
int len = section.length();
String first = section.substring(0,2);
String last = section.substring(len-2,len);
ArrayList<Integer> sectionList = new ArrayList<>();
int firstInt = Integer.parseInt(first);
int lastInt = Integer.parseInt(last);
for (int i = firstInt; i <= lastInt; i++) {
sectionList.add(i);
}
return sectionList;
}
开始解析课程信息
DomElement[][] domElements = new DomElement[7][6]; //7天,6个节次部分
String key = "";
//星期一~星期日:1-2~7-2
for (int i = 0;i < 7;i++){ //星期一到星期日
for (int j = 0;j <= 5;j++){ //sectionIds[0]到sectionIds[5]
if(j == 2){ //由于第5节为空,略过
continue;
}
key = sectionIds[j] + "-" + (i+1) + "-2";
if(page3.getElementById(key) == null){
throw new NullPointerException("Key过期了!");
}else{
domElements[i][j] = page3.getElementById(key);
}
String course = domElements[i][j].asText();
String temp[] = new String[10];
int num = 0;
int index;
for (int g = 0; course.contains("---------------------"); g = g + index) {
index = course.indexOf("---------------------");
temp[num] = course.substring(0,index);
course = course.substring(index+21);
num++;
}
temp[num] = course;
String[] courseInfo = new String[4];
for (int k = 0;k < temp.length;k++) {
if(temp[k] == null || temp[k].equals("") || temp[k].equals(" ")){
continue;
}
if(temp[k].indexOf("n") == 1){
temp[k] = temp[k].substring(2);
}
ArrayList<Integer> weekList;
ArrayList<Integer> sectionList;
if(temp[k].contains("网络课")){
temp[k] = temp[k].substring(0,temp[k].indexOf("n"));
courseInfo[0] = temp[k];
weekList = null;
sectionList = null;
}else{
int idx,cnum = 0;
for(int h = 0; temp[k].contains("n") && cnum <= 3;h = h+idx){
idx = temp[k].indexOf("n");
courseInfo[cnum] = temp[k].substring(0,idx);
temp[k] = temp[k].substring(idx+1);
cnum++;
}
weekList = getWeekCount(courseInfo[2]);
sectionList = getSectionCount(courseInfo[2]);
}
System.out.println("课程名===" + courseInfo[0]);
System.out.println("教师名===" + courseInfo[1]);
System.out.println("周次===" + weekList);
System.out.println("节次===" + sectionList);
System.out.println("地点===" + courseInfo[3]);
System.out.println("星期" + (i+1));
}
}
}
输出效果:

基于Uni-App实现的课程表小程序:

以上就是Java爬虫范例之使用Htmlunit爬取学校教务网课程表信息的详细内容,更多关于Java 爬虫的资料请关注靠谱客其它相关文章!
最后
以上就是热心蜻蜓最近收集整理的关于Java爬虫范例之使用Htmlunit爬取学校教务网课程表信息的全部内容,更多相关Java爬虫范例之使用Htmlunit爬取学校教务网课程表信息内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复