目录
- 模糊查询
- 表的约束
- 表之间的关联
- 多对一关联
- 多对多关联
- 一对一关联
模糊查询
可以根据大致提供的内容,找到我们想要的数据,它与=查询不同,拿char类型数据和varchar类型数据举例:
create table c1(x char(10));create table c2(x varchar(10));insert c1 values('io');insert c2 values('io');登录后复制模糊查询使用到的是like
select * from c1 where x like 'io';select * from c2 where x like 'io';
登录后复制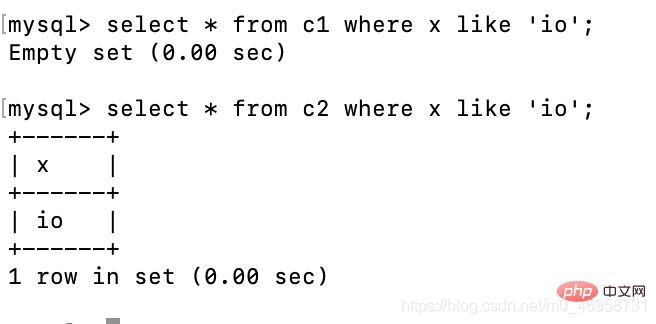
可以发现,c1里面的x为char类型,我们通过模糊查询是否有io这个数据,无法显示出来,而我们通过=却可以查询出来

模糊查询比较精准,这种方式查询,必须要输入这个字段的全部内容,才可以查询出来,而这里char类型存储的数据,长度不满10为,所以使用了空格补充,所以查询的时候,需要把空格带上才可以;
我们也可以使用模糊查询提供给我们的查询方式,% 表示任意0个或多个字符。
select * from c1 where x like 'io%';
登录后复制
如果我们只知道第二位是一个o,不知道开头和结尾,可以使用:_ 表示任意单个字符,再配合%匹配后面的多个字符
select * from c1 where x like '_o%';
登录后复制
SQL模糊查询的语法为
“SELECT column FROM table WHERE column LIKE ‘;pattern’;”。
SQL提供了四种匹配模式:
表的约束
介绍:
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分为:
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录FOREIGN KEY (FK) 标识该字段为该表的外键NOT NULL 标识该字段不能为空UNIQUE KEY (UK) 标识该字段的值是唯一的AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)DEFAULT 为该字段设置默认值UNSIGNED 无符号
ZEROFILL 使用0填充
登录后复制not null:字面意思就说明了,设置后,每次插入值时,必须为该字段设置值
default:如果没有为该字段设置值,则使用我们定义在default后面的一个默认值
UNIQUE KEY:某个字段设置这个约束后,那么它设置的值,在整个表中这个字段只能存在一个(唯一)
PRIMARY KEY:主键primary key是innodb存储引擎组织数据的依据,innodb称之为索引组织表,一张表中必须有且只有一个主键。主键是能确定一条记录的唯一标识
AUTO_INCREMENT:当设置以后,每次向表插入值时,这个字段会自动增长一个数字,但是这个字段必须是整数类型,而且还要是主键
FOREIGN KEY:外键,将该表的某个字段关联另一张表的某个字段,关联后这个字段的值必须对应关联字段的值。
我们创建表,通常会有一个id字段作为索引标识作用,并且会将它设置为主键和自增。
实例:
create table test(
id int primary key auto_increment,
identity varchar(18) not null unique key, --身份证必须唯一
gender varchar(18) default '男');insert test(identity) values('123456789012345678');登录后复制
当身份字段插入相同值,则会报错,因为字段设置了唯一值
insert test(identity,gender) values('0123456789012345678','女');登录后复制
我们会发现,id不对劲啊,那是因为笔者之前进行两次插入值操作,但是值并没有成功插入进去,但是这个自增却受到了影响.
这个时候,我们进行两部操作就可以解决这个问题。
alter table test drop id;alter table test add id int primary key auto_increment first;
登录后复制删除id字段,再重新设置。
很神奇是不是,这个MySQL的底层机制。vary 良心
还需要注意的是:我们使用delete删除一条记录时,并不会影响自增
delete from test where id = 2;insert test(identity,gender) values('111111111111111111','男');登录后复制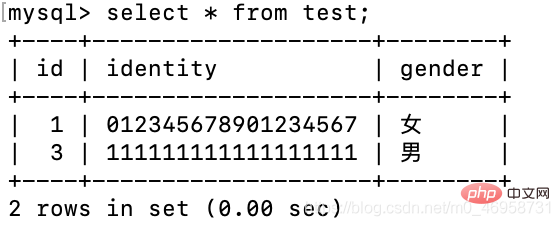
关于这个操作,如果我们只是删除单条记录的话,可以使用上序提供的方法还调整自增的值,而如果是删除整个表记录的话,使用以下方法:
truncate test;
登录后复制效果演示:delete删除整个表记录
效果演示:truncate删除整个表记录
联合主键
确保设置为主键的某几个字段的数据相同
实例:
create table test(
id int,
name varchar(10),
primary key(id,name));
insert test values(1,1);登录后复制
如果再次插入两个主键相同的数据,则会报错
只要设置主键的两个字段,在一条记录内,数据不完全相同就没有问题。
外键的话,我们在表之间的关联进行演示
表之间的关联
我们这里先介绍表之间的关联,后面再学习联表查询
通过某一个字段,或者通过某一张表,将多个表关联起来。
我们一张表处理好不行吗,为什么要关联,像这样?
有没有发现一个问题,有些员工它们对应的是相同部门,一张表就重复了很多次记录,随着员工数量的增加,就会出现越来越多个重复记录,相对更占用空间了。
那么我们需要将部门单独使用一张表,再将员工这个使用一个字段关联到另一个表内,我们可以使用外键,也可以不使用外键,先来演示外键的好处吧
多对一关联
如:多个员工对应一个部门。
员工表,先别急着创建,请向下看
create table emp(
id int primary key auto_increment,
name varchar(10) not null,
dep_id int,
foreign key(dep_id) references dep(id)
on update cascade # 级联更新
on delete cascade); # 级联删除
登录后复制上面外键的作用就是:
注意:必须是外键已存在,所以需要先创建部门表,再创建员工表
部门表
create table dep(
id int primary key auto_increment,
name varchar(16) not null unique key,
task varchar(16) not null);
登录后复制emp表的dep_id字段设置的数据必须是dep表已存在的id
所以我们需要先向dep表插入记录
insert dep(name,task) values('IT','技术'),('HR','招聘'),('sale','销售');登录后复制员工表插入记录
insert emp(name,dep_id) values
('jack',1),
('tom',2),
('jams',1),
('rouse',3),
('curry',2);
# ('go',4) 报错,在关联外键的id字段中找不到登录后复制注意:如果我们emp表的dep_id字段插入的数据,在dep表中的id字段不存在该数据时,就会报错。
查询我们创建后的效果
这样就把这两个表关联起来了,目前我们先不了解多表查询,这个先了解的是,表之间的关联。
我们再来看一下同步更新以及删除,外键的改动被关联表会受到影响
update dep set id=33333 where id = 3;
登录后复制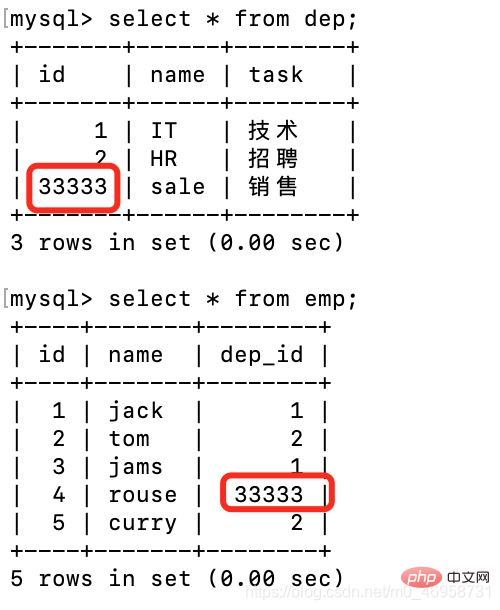
再来体验一下同步删除
delete from dep where id = 33333;
登录后复制
这就是外键带给我们的效果,有利也有弊:
- 优点:关联性强,只能设置已存在的内容,并且同步更新与删除
- 缺点:当删除外键表的某一条记录,关联表中有关联性的记录会被全部删除
多对多关联
多张表互相关联
如:一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多
这时使用外键会出现一个弊端,那就是先创建哪张表呢?它们都互相对应,是不是很矛盾呢?解决办法:第三张表,关联书的id与作者的id
book表
create table book(
id int primary key auto_increment,
name varchar(30));
登录后复制author表
create table author(
id int primary key auto_increment,
name varchar(30));
登录后复制中间表:负责将两张表进行关联
create table authorRbook(
id int primary key auto_increment,
author_id int,
book_id int,
foreign key(book_id) references book(id)
on update cascade
on delete cascade,
foreign key(author_id) references author(id)
on update cascade
on delete cascade);登录后复制多名作者关联一本书,或者一名作者关联多本书,书也要体现出谁关联了它
book表插入数据:
insert book(name) values
('斗破苍穹'),
('斗罗大陆'),
('武动乾坤');登录后复制author表插入数据:
insert author(name) values
('jack'),
('tom'),
('jams'),
('rouse'),
('curry'),
('john');登录后复制关联表插入数据:
insert authorRbook(author_id,book_id) values
(1,1),
(1,2),
(1,3),
(2,1),
(2,3),
(3,2),
(4,1),
(5,1),
(5,3),
(6,2);
登录后复制目前的对应关系就是:
一个作者可以产于多本书的编写,同时,每本书都会标明产于的作者
一对一关联
路人有可能变成某个学校的学生,即一对一关系。
在这之前,路人不属于学校。
原理就是:学校通过广告,或者通过电话邀请,将路人变成了学生。
路人表
create table passers_by(
id int primary key auto_increment,
name varchar(10),
age int);
insert passers_by(name,age) values
('jack',18),
('tom',19),
('jams',23);登录后复制学校表
create table school(
id int primary key auto_increment,
class varchar(10),
student_id int unique key,
foreign key(student_id) references passers_by(id)
on update cascade
on delete cascade);insert school(class,student_id) values
('Mysql入门到放弃',1),
('Python入门到运维',3),
('Java从入门到音乐',2);登录后复制数据存储的设计,需要提前设计好表的关联 关系,将关系全部设计好以后,剩下的只是往里存数据了,后续我们会了解到联表查询相关内容,将有关联性的内容,以虚拟表的形式查询出来,查询出来的数据可能来自多个表。
表的关联,建议使用以下方式
- 多对多 > 多对一 > 一对一
以上就是一起了解什么是MySQL数据库(三)的详细内容,更多请关注靠谱客其它相关文章!

最后
以上就是大意酒窝最近收集整理的关于一起了解什么是MySQL数据库(三)的全部内容,更多相关一起了解什么是MySQL数据库(三)内容请搜索靠谱客的其他文章。








发表评论 取消回复