大概总结了一下CVPR2022目标检测领域的文章,并未包括跨域和3D目标检测。
个人总结,难免有疏漏,大家参考一下就好。
CVPR 2022
一、常规目标检测
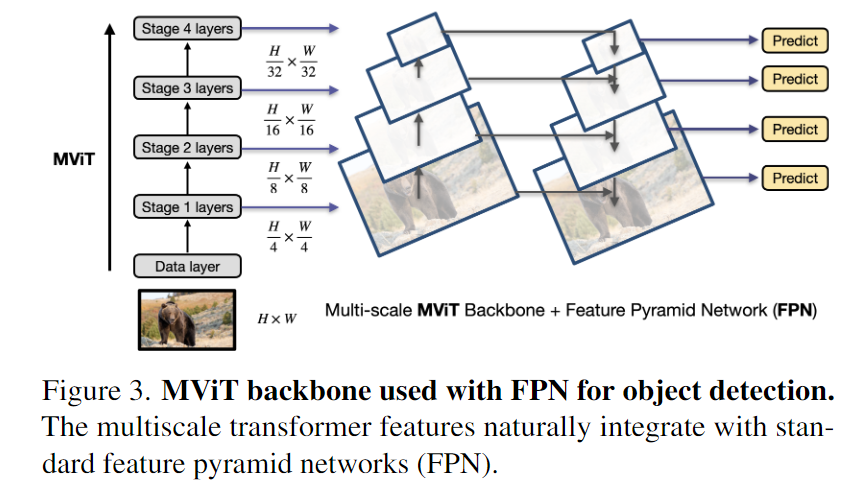
1. MViTv2: Improved Multiscale Vision Transformers for Classification and Detection
- 作者Yanghao Li, Chao-Yuan Wu, Haoqi Fan, Karttikeya Mangalam, Bo Xiong, Jitendra Malik, Christoph Feichtenhofer
- 引用:32
- 创新点:
- 优化了池化注意力机制: (a)移位不变的位置嵌入,即使用分解的位置距离引入transformer块的位置信息; (b)残差池化连接,以补偿注意力计算中的池化步长的影响。
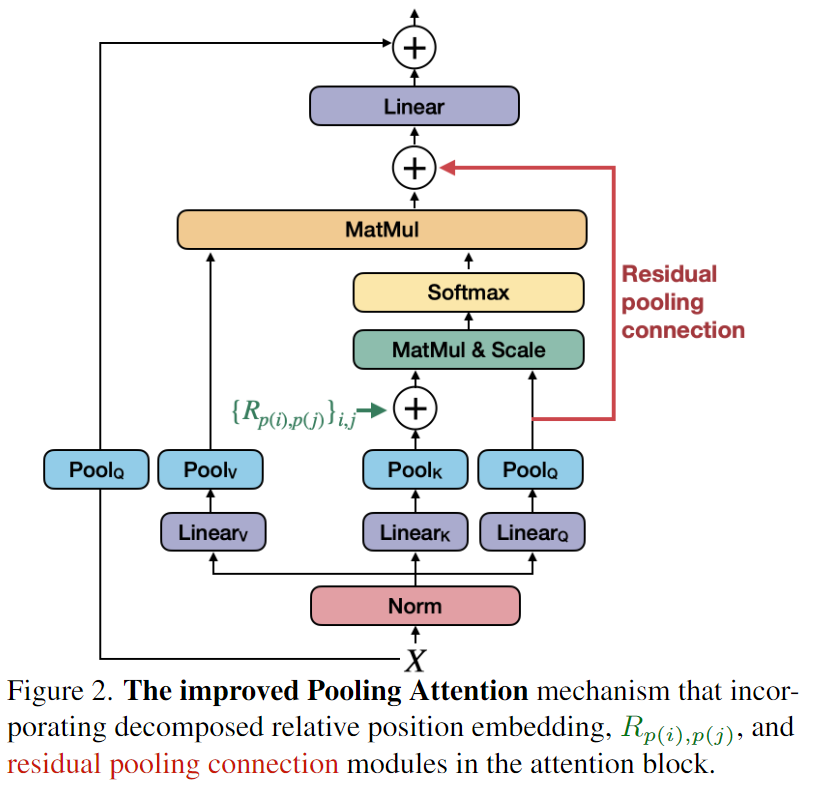
- 使用改进的 MviT 结构,我们采用了一个标准的密集预测框架: Mask R-CNN 和特征金字塔网络(FPN) ,并将其应用于目标检测和实例分割
- 优化了池化注意力机制: (a)移位不变的位置嵌入,即使用分解的位置距离引入transformer块的位置信息; (b)残差池化连接,以补偿注意力计算中的池化步长的影响。
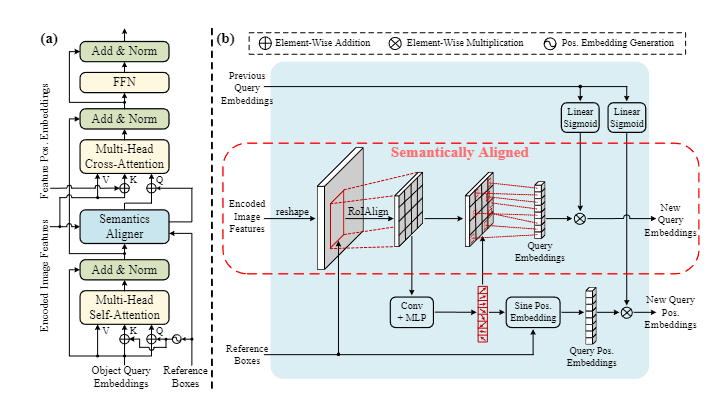
2. Accelerating DETR Convergence via Semantic-Aligned Matching
- 作者:Gongjie Zhang, Zhipeng Luo, Yingchen Yu, Kaiwen Cui, Shijian Lu
- 引用:8
- 创新点
- 提出了 语义对齐匹配 DETR (SAM-DETR) ,它通过创新地将交叉注意解释为一个“匹配和提取”过程,并通过编码图像特征对目标查询进行语义对齐来促进其匹配,从而显著加速了 DETR 的收敛。
- 提出了显式搜索目标的显著特征,并将其提供给语义匹配的交叉注意模块,进一步提高了检测精度,加快了模型的收敛速度。
- 实验验证了提出的 SAM-DETR 算法与原有的 DETR 算法相比,收敛速度明显加快。
- 由于只是在原有的 DETR 中增加了一个即插即用模块,其他操作基本上没有变化,所以提出的 SAM-DETR 可以很容易地与现有的解决方案集成,这些解决方案可以修改注意机制,进一步提高 DETR 的收敛性,即使在12个训练周期内,也可以达到与更快的 R-CNN 相当的收敛速度
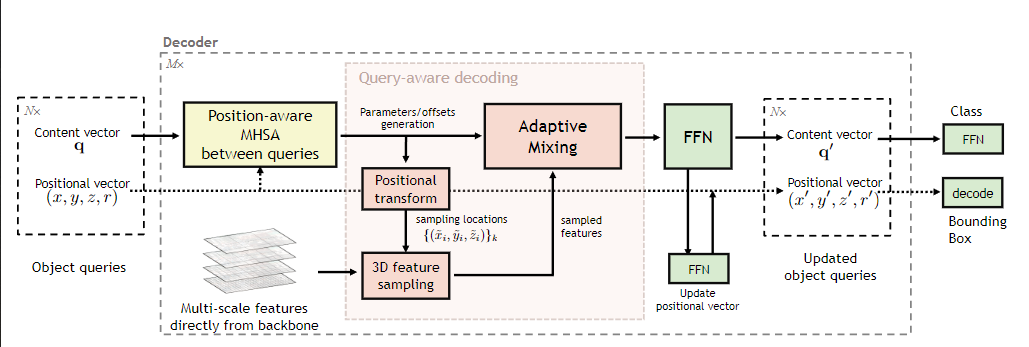
3. AdaMixer: A Fast-Converging Query-Based Object Detector
- 作者:Ziteng Gao, Limin Wang, Bing Han, Sheng Guo
- 引用:2
- 创新点
- 提出了一个快速收敛的基于查询(如DETR系列、SMCA、Sparse R-CNN)的目标检测器AdaMixer,由骨干网络和本文提出的解码器组成,并没有额外的注意力编码器或显式的金字塔网络
- 为了有效地使用查询来表示对象,AdaMixer 从整体上引入了自适应三维特征采样器和通道语义与空间结构的自适应混合
- 自适应三维特征采样器:通过将backbone中的多尺度特征映射作为一个三维特征空间,本文提出的解码器可以灵活地在空间和尺度上对特征进行采样,以自适应地处理基于查询的物体的位置和尺度变化
- 通道语义与空间结构的自适应混合:在查询的指导下,自适应混合算法将通道和空间混合算法应用于具有动态核的采样特征。自适应位置采样和整体内容解码显著提高了查询对不同图像检测不同目标的适应性。
4. DESTR: Object Detection With Split Transformer
- 作者:Liqiang He, Sinisa Todorovic
- 引用:1
- 创新点
- 解码器中的分类分支和回归分支分别计算各自的交叉注意力,而不是共享相同的交叉注意
- 在编码器后面插入一个小检测器,用于学习分类、回归和位置嵌入
- 在解码器中计算查询及其相邻空间上下文的自注意,而不是对每个查询孤立技术自注意力
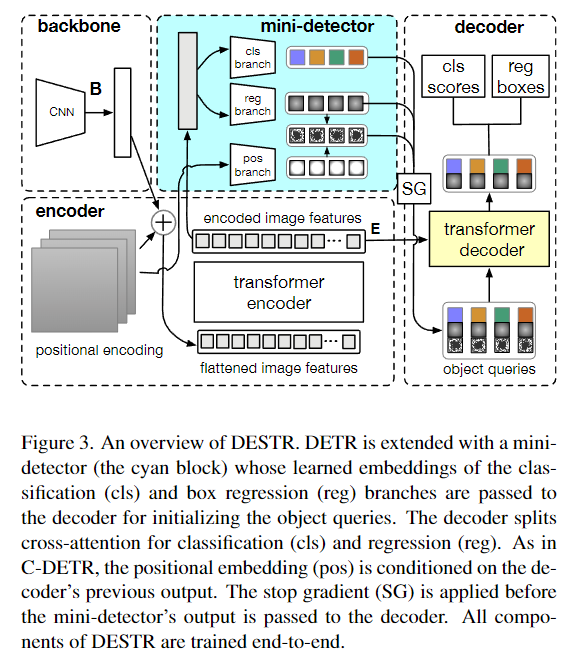
5. R ( D e t ) 2 R(Det)^2 R(Det)2: Randomized Decision Routing for Object Detection
- 作者:Yali Li, Shengjin Wang
- 引用:1
- 创新点
- 针对目标检测中的多节点决策问题,提出了路径选择与预测值的分离方法。具体来说,提出了基于树的决策头端到端联合学习的随机决策路由。
- 提出了一种新的目标检测决策头,该决策头引入路由概率和掩码,从多个节点产生发散决策,以提高整体决策效率
二、半监督目标检测
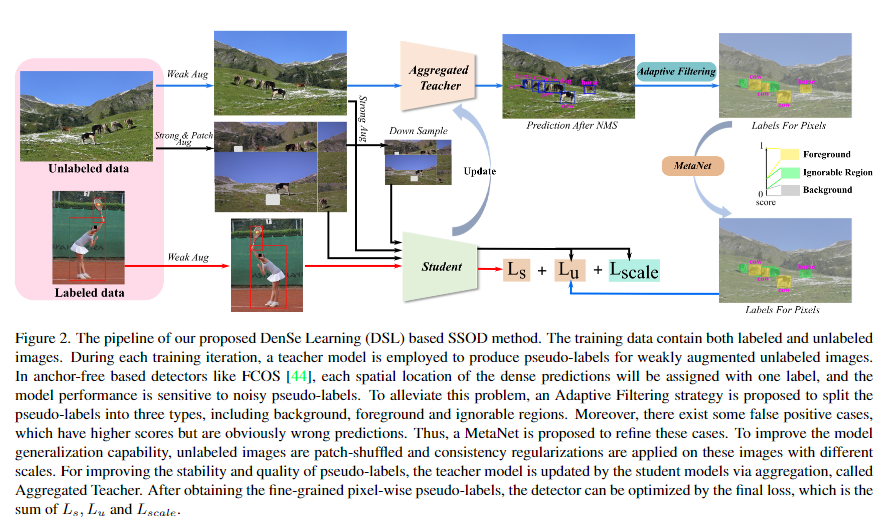
6. Dense Learning based Semi-Supervised Object Detection
- 作者:Binghui Chen, Pengyu Li, Xiang Chen, Biao Wang, Lei Zhang, Xian-Sheng Hua
- 引用:1
- 任务: 半监督目标检测
- 创新点
- 开发了一种简单而有效的密集学习(DSL)方法,以提高未标记数据的利用率。据我们所知,这是 SSOD 的第一个无锚方法。
- 提出一种自适应滤波(AF)策略,为每个像素分配细粒度伪标签
- 引入聚合教师(AT)策略,提高估计伪标签的稳定性和质量;
- 采用混合补丁学习和尺度间的不确定性一致性正则化,提高模型的泛化性能
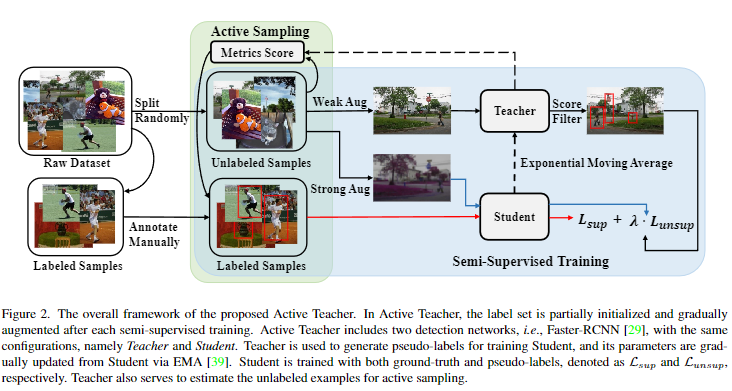
7. Active Teacher for Semi-Supervised Object Detection
- 作者:Peng Mi, Jianghang Lin, Yiyi Zhou, Yunhang Shen, Gen Luo, Xiaoshuai Sun, Liujuan Cao, Rongrong Fu, Qiang Xu, Rongrong Ji
- 引用:0
- 任务:半监督目标检测
- 创新点
- 我们首次尝试研究以师生为基础的半监督目标检测的数据初始化,并为不同的取样策略进行广泛的实验。这些定量和定性的分析可以为实际应用中的数据注释提供有用的参考。
- 我们提出了一个名为主动教师的新的 SSOD 师生框架,它不仅在基准数据集上优于一组 SSOD 方法,而且能够使基线检测网络以更少的标签开支实现100% 的全监督性能
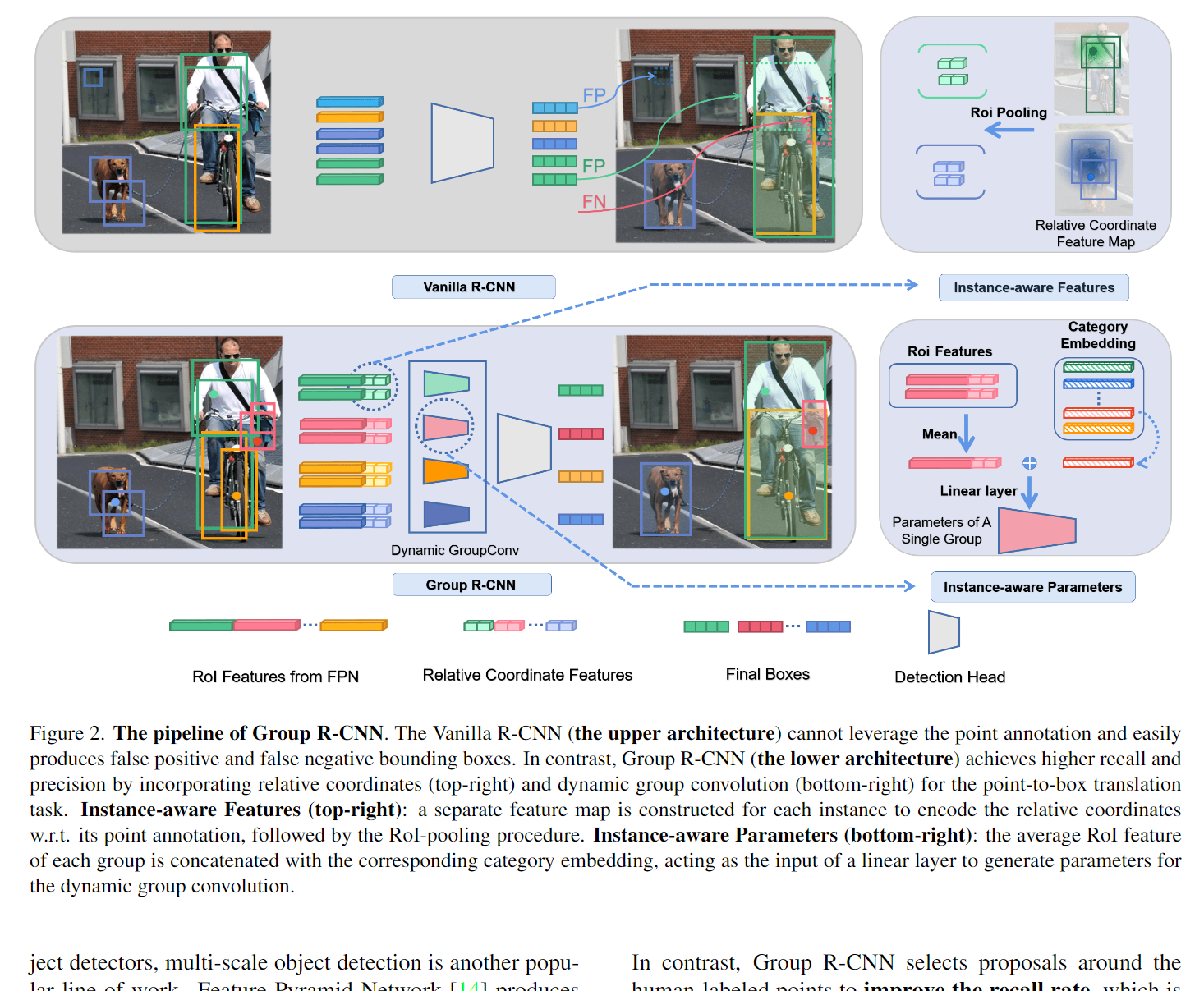
8.Group R-CNN for Weakly Semi-Supervised Object Detection With Points
- 作者:Shilong Zhang, Zhuoran Yu, Liyang Liu, Xinjiang Wang, Aojun Zhou, Kai Chen
- 引用:3
- 任务:基于点的弱半监督目标检测
- 训练数据由一组带有边界框的完全注释图像和一组每个实例只有一个点注释的大型弱标记图像组合而成
- 创新点
- 提出了实例感知的表示学习,包括实例感知的特征增强和实例感知的参数生成。使用点注释来计算实例感知的相对坐标,用这些坐标来构造实例感知的特征映射,成功地解决了实例分配过于简单所带来的收敛问题,获得了较好的性能
- 所提出的Group RCNN相较于DETR,能够直接利用FPN结构,并且继承了CNN的收敛优势
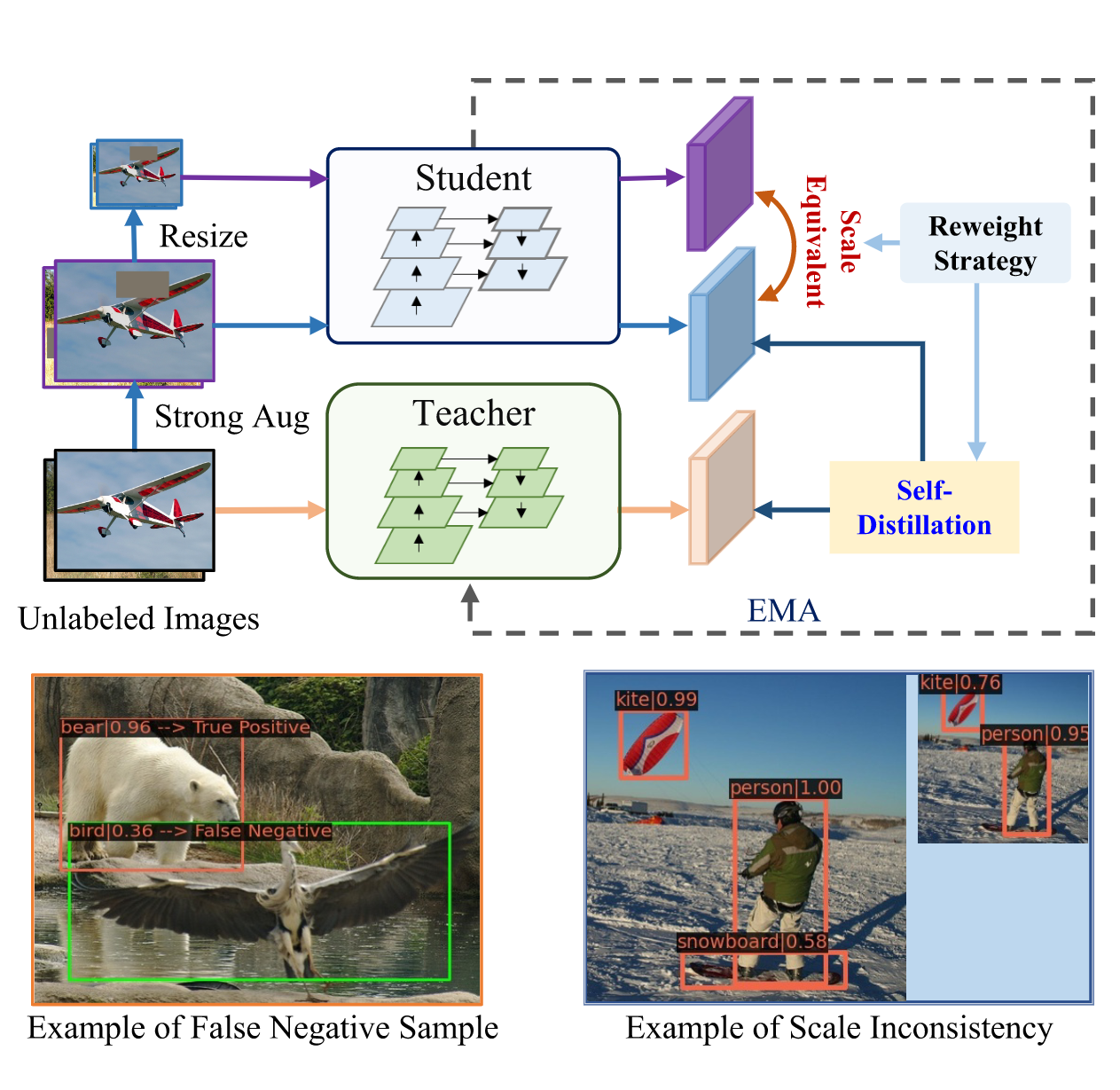
9.Scale-Equivalent Distillation for Semi-Supervised Object Detection
- 作者:Qiushan Guo, Yao Mu, Jianyu Chen, Tianqi Wang, Yizhou Yu, Ping Luo
- 引用:1
- 任务:半监督目标检测
- 创新点
- 针对目前半监督目标检测任务中的困难,提出了Scale-Equivalent蒸馏框架,由以下几个部分组成:
- 由于尺度是低维语义流形中的一个重要因素,作者设计了一个跨不同层次的预测尺度一致性正则化方法,以解决物体尺度差异大的问题。
- 针对硬伪标签噪声对识别一致性的不利影响,提出了一种在不增加可学习参数的情况下提高泛化性能的自蒸馏方法。
- 实施了一个重新加权策略以克服类别不平衡,重点关注不同层次输出之间的不一致性,以及教师和学生检测器之间的不一致性。
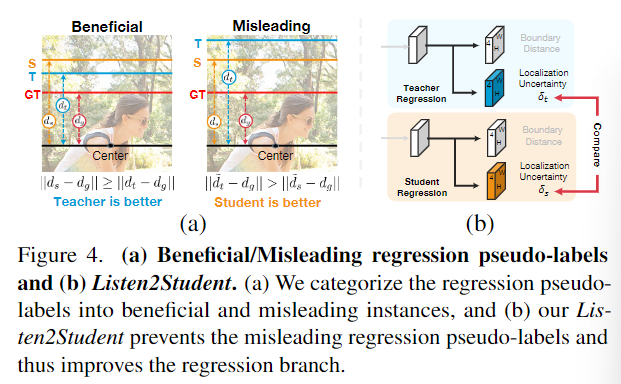
10.Unbiased Teacher v2: Semi-Supervised Object Detection for Anchor-Free and Anchor-Based Detectors
- 作者:Yen-Cheng Liu, Chih-Yao Ma, Zsolt Kira
- 引用:0
- 任务:半监督目标检测
- 创新点
- 首先研究了现有无锚检测器在半监督目标检测上的有效性,发现它们在半监督环境下的性能很差,无锚探测器中使用的带中心的框选择和基于定位的标记方法都不能很好地回归
- 通过考虑教师和学生预测的相对不确定度估计,提出了**Listen2Student **机制,显著防止了边界框回归训练中的误导性伪标签
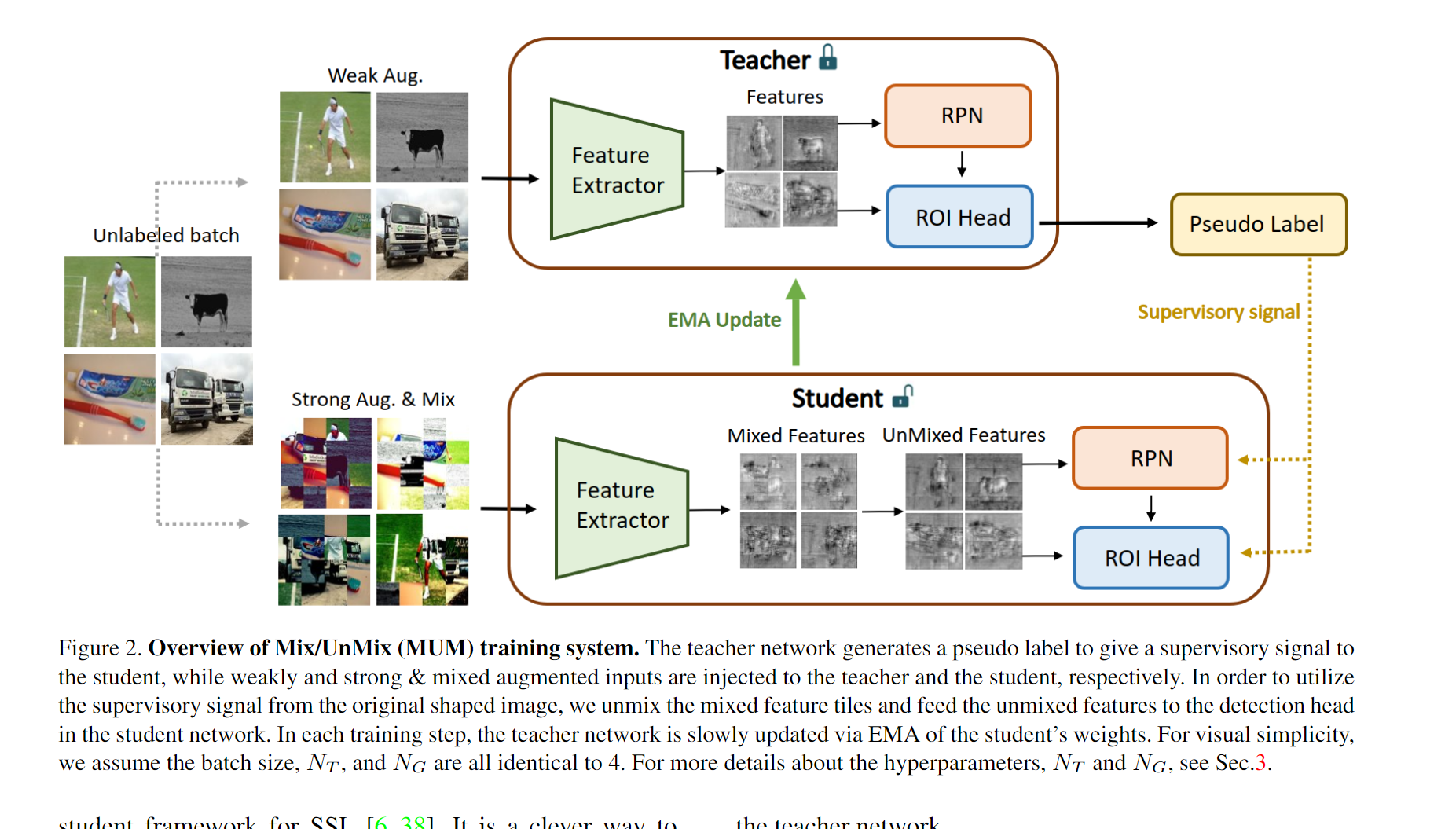
11.MUM: Mix Image Tiles and UnMix Feature Tiles for Semi-Supervised Object Detection
- 作者:JongMok Kim, JooYoung Jang, Seunghyeon Seo, Jisoo Jeong, Jongkeun Na, Nojun Kwak
- 引用:3
- 任务:半监督目标检测
- 创新点
- 提出了一种简单而有效的数据增强方法 Mix/UnMix (MUM) ,该方法对图像进行混合输入,并在特征空间中对图像进行重构。因此,MUM 算法可以利用非插值伪标签的插值正则化效应,成功地生成有意义的弱增强-强增强图像对。
- 通过实验验证了该方法相对于可靠基线方法的优越性,并在 MS-COCO 和 PASCAL VOC 数据集上取得了较好的性能。此外,作者还证明了提出的方法的通用性,在不同的骨干上也能达到较好的提升。
三、少样本目标检测
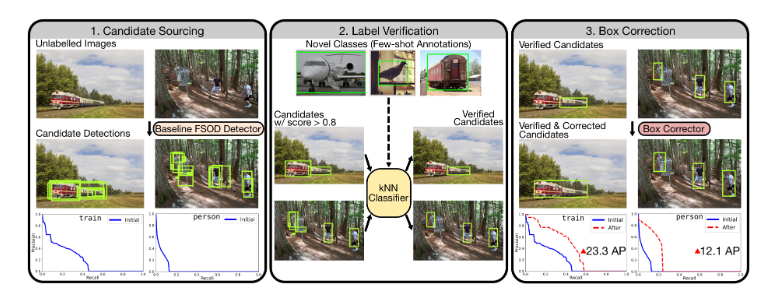
12. Label, Verify, Correct: A Simple Few Shot Object Detection Method
- 作者:Prannay Kaul, Weidi Xie, Andrew Zisserman
- 引用:6
- 任务:增量少样本目标检测
- 已有一个训练完成的检测器,需要检测仅有很少样本的新类
- 创新点
- 用两阶段目标检测器(Faster RCNN)研究了少样本目标检测的问题
- 引入一种新的伪标注验证和修正算法,显著提高了伪标注的类别和标注框坐标的精度。首先用训练好的检测器对未标注的数据给出预测框,之后使用KNN对上一步的标签进行验证,再调整Faster RCNN的RPN以调整预测框的位置,从而得到大量高质量的预测框,将这些框作为训练数据继续训练检测器
- 分析了数据增强的几个关键组成部分,并进行了消融实验,以验证其必要性
13. Semantic-aligned Fusion Transformer for One-shot Object Detection
- 作者:Yizhou Zhao, Xun Guo, Yan Lu
- 引用:0
- 任务: one-shot目标检测
- 仅根据一个给定实例检测新对象
- 创新点
- 本文提出的语义校准融合Transformer是离线One-shot目标检测任务中的第一个无先验框一阶段检测器,比最先进的两阶段模型产生更好的性能
- 讨论了query-support特征融合问题,提出了一种统一的注意机制来解决空间和尺度上的语义失调问题。本文对此的实现可以扩展到一般的融合neck
- 通过定性和定量实验,我们证明了新的语义对齐融合方法通过涉及跨尺度的远程关系和收集更全面的元知识,优于传统的关联方法
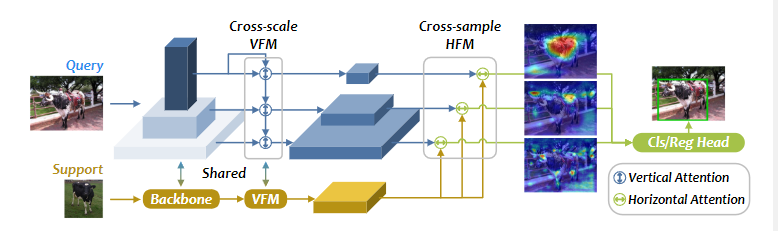
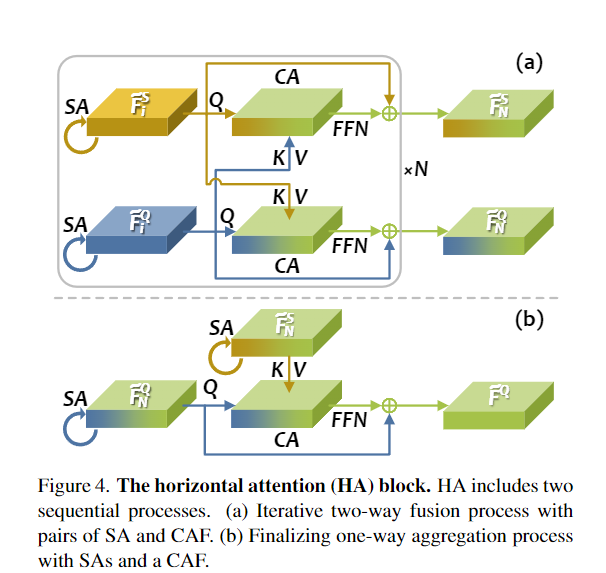
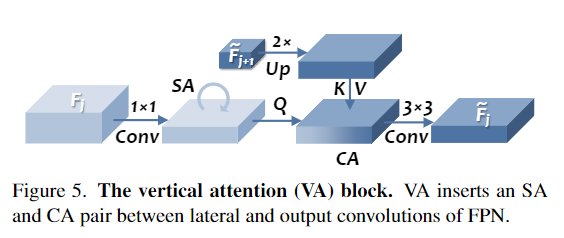
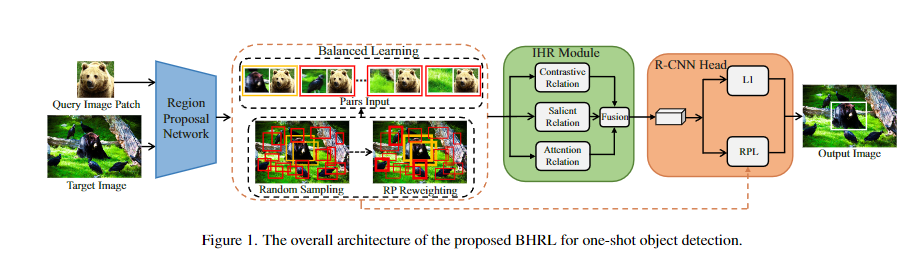
14. Balanced and Hierarchical Relation Learning for One-shot Object Detection
- 作者:Hanqing Yang, Sijia Cai, Hualian Sheng, Bing Deng, Jianqiang Huang, Xian-Sheng Hua, Yong Tang, Yu Zhang
- 引用:1
- 任务:** one-shot目标检测(OSOD)**
- 创新点
- 针对 OSOD 任务,作者设计了一个功能强大的多级关系模块 IHR。同时利用对比度、显著度和注意度三个层次上的语义相似性,寻找查询图像块与目标图像之间更全面的关系。
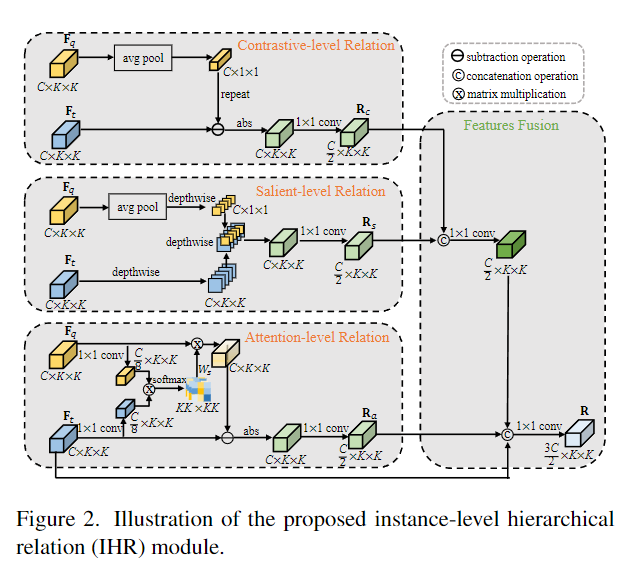
- 提出一个简单而有效的Ratio-Preserving Loss,以解决正负样本不平衡的问题,从而实现IHR模块的平衡和有效学习。
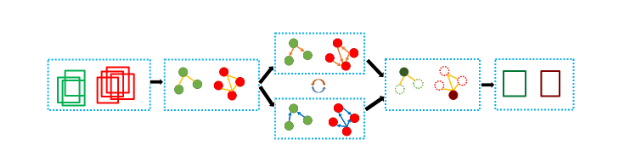
18. SIOD: Single Instance Annotated Per Category Per Image for Object Detection
- 作者:Hanjun Li, Xingjia Pan, Ke Yan, Fan Tang, Wei-Shi Zheng
- 引用:1
- 任务:单实例目标检测(SIOD)
- 一张图片中一类只打一个标签框
- 不同目标检测区别如下图:弱监督(WSOD)、半监督(SSOD)、稀疏标注(SAOD)、单实例(SIOD)

- 创新点
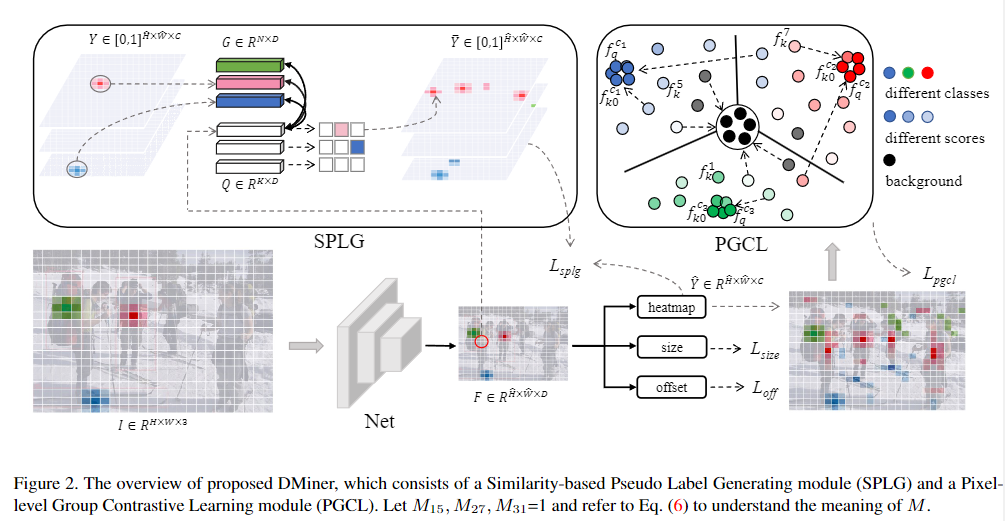
- 提出了 SIOD 任务,节省了标注成本。
- 提出挖掘未标记实例的 DMiner 框架,提高对伪标记的容忍度。
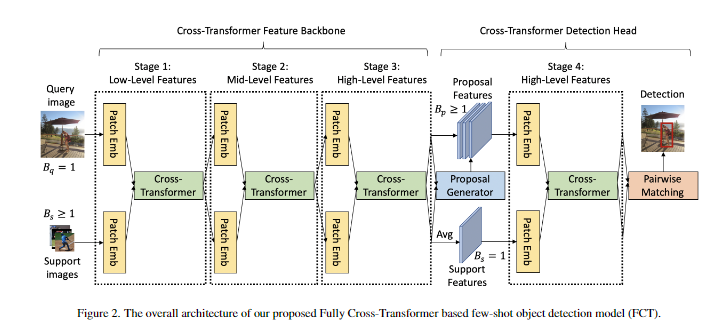
16. Few-Shot Object Detection With Fully Cross-Transformer
- 作者:Guangxing Han, Jiawei Ma, Shiyuan Huang, Long Chen, Shih-Fu Chang
- 引用:8
- 任务:少样本目标检测
- 创新点
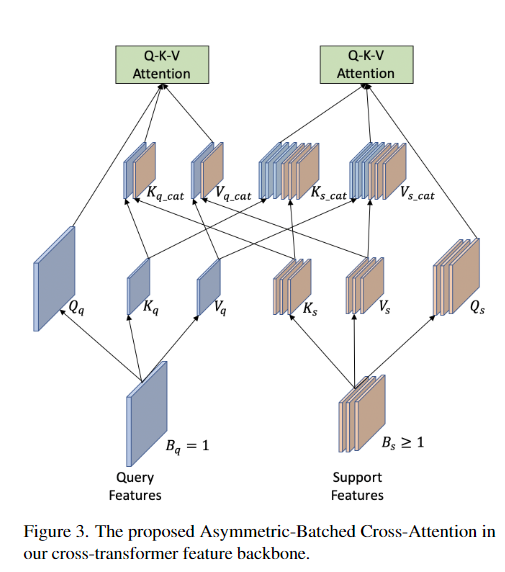
- 据我们所知,我们是第一个探索和提出基于视觉transformer的少样本目标检测模型。
- 针对特征骨干和检测头,提出了一种新的全交叉transformer,以增强查询和支持之间的多级交互。我们还提出了跨分支的非对称分批交叉注意力机制。
17. Sylph: A Hypernetwork Framework for Incremental Few-Shot Object Detection
- 作者:Li Yin, Juan M. Perez-Rua, Kevin J. Liang
- 引用:0
- 任务:增量少样本目标检测
- 創新點:
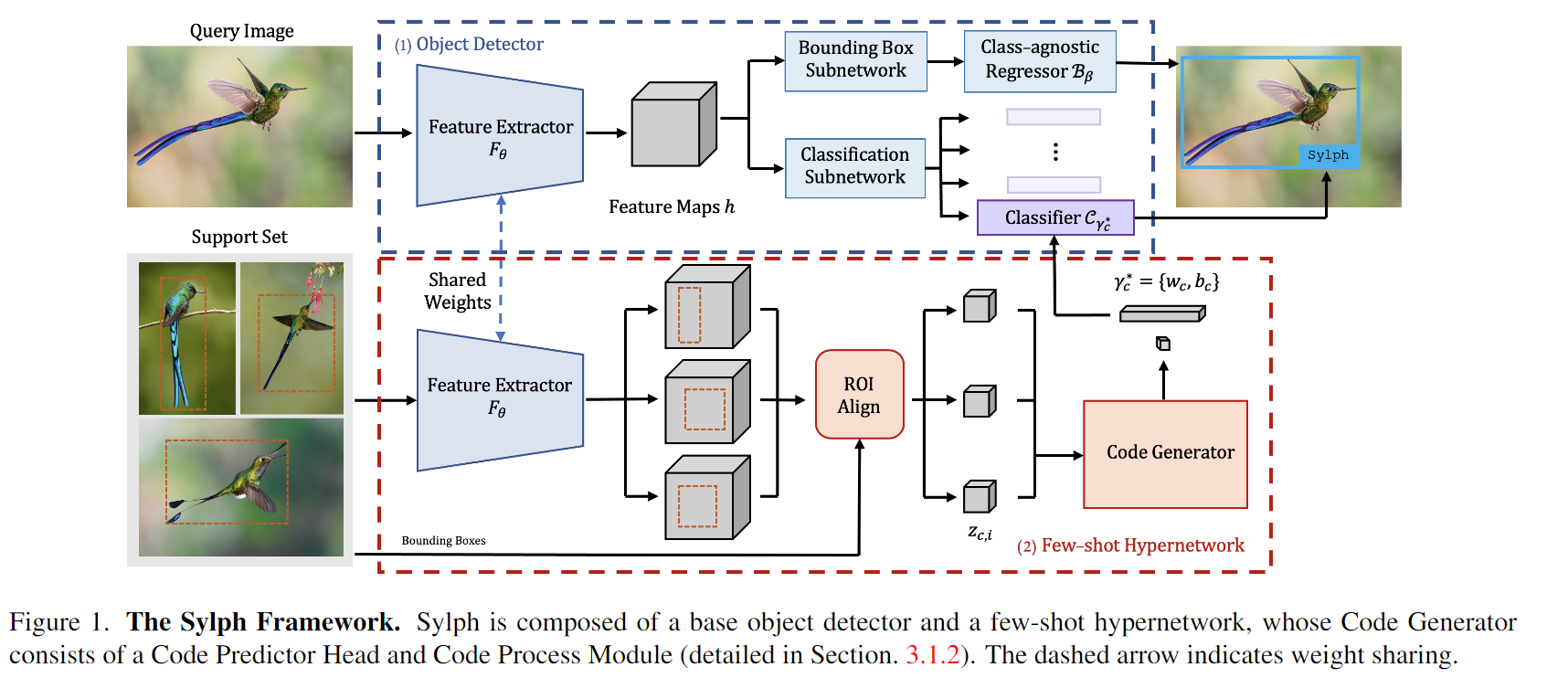
- 使用类似于 ONCE 的基本检测器和 超网络(hypernetwork)架构 ,區別為:
- ONCE试图直接生成位置回归模型的参数,将查询样本特征映射到输出預測框。但作者利用了一个基于大量基类数据预先训练的具有类不可知定位能力的基检测器,将定位与分类分离,大大简化了这项任务
- 研究了类条件超网络的行为,对其结构进行了一些关键的改进,并对预测参数进行了归一化处理,提高了预测精度
18.Adaptive Hierarchical Representation Learning for Long-Tailed Object Detection
- 作者:Banghuai Li
- 引用:0
- 任务:长尾目标检测
- 创新点
- 提出了一个简单而有效的方法,称为自适应层次表示学习(AHRL) ,从metric 学习的角度来解决长尾目标检测的问题。AHRL分为两阶段:
- 第一阶段,首先训练一个典型的基线模型,即Mask R-CNN。然后采用无监督聚类算法,根据预训练模型的分类权重构建分层特征空间。
- 第二阶段,提出了一个新的损失函数,称为自适应层次表示损失 ,以实现论文提出的由粗到精设计。
四、知识蒸馏
19. Focal and Global Knowledge Distillation for Detectors
- 作者:Zhendong Yang, Zhe Li, Xiaohu Jiang, Yuan Gong, Zehuan Yuan, Danpei Zhao, Chun Yuan
- 引用:12
- 任务:知识蒸馏
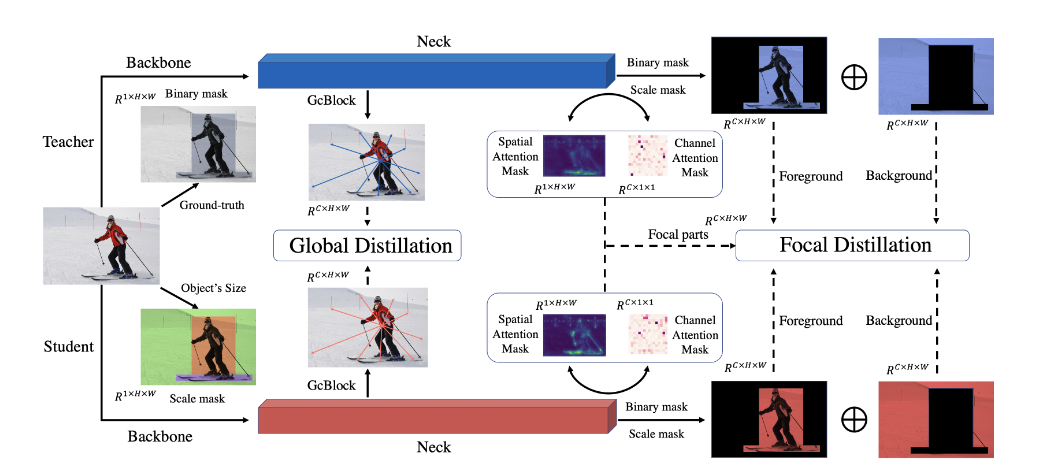
- 创新点:
- 展示了师生关注的像素和通道有很大不同。如果提取像素和通道而不区分它们,那么可以产生细微的提升。
- 提出焦点和全局蒸馏,使学生不仅能够专注于教师关键的像素和通道,而且能够了解像素之间的关系。
- 通过对 COCO的大量实验,包括一阶段、两阶段、无先验框方法,在各种探测器上验证了此方法的有效性,实现了最先进的性能
20. Localization Distillation for Dense Object Detection
- 作者:Zhaohui Zheng, Rongguang Ye, Ping Wang, Dongwei Ren, Wangmeng Zuo, Qibin Hou, Ming-Ming Cheng
- 引用:11
- 任务:知识蒸馏
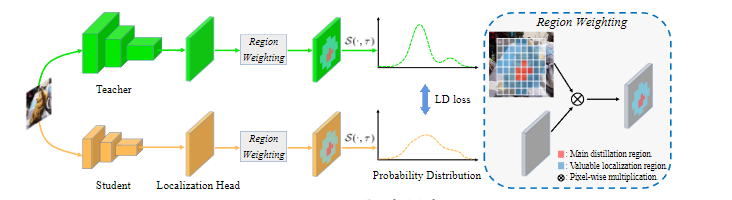
- 创新点:
- 之前知识蒸馏(KD)目标检测方法专注于教师网络和学习网络中,backbone和neck等深度特征的模型,这无法提取有效的定位信息,作者将回归损失定位成下游任务,同原始的KD中设计出对应的**位置蒸馏(LD)**的蒸馏方式。
- 根据拟议的分治蒸馏策略,进一步引入了有价值的定位区域(VLR),以帮助有效判断哪些区域有利于分类或位置学习。
五、开集目标检测
21. OW-DETR: Open-world Detection Transformer
- 作者:Akshita Gupta, Sanath Narayan, K J Joseph, Salman Khan, Fahad Shahbaz Khan, Mubarak Shah
- 引用:11
- 任务:开放世界目标检测
- 将尚未引入训练集的对象识别为“未知”,无需明确监督
- 在逐渐接收到相应的标签时,逐步学习这些已识别的未知类别,而不会忘记先前学习的类别
- 创新点:
- 提出了一个基于Transformer的开放世界检测器,OW-DETR,以多尺度的自注意机制和可变感受野来模拟上下文。
- 引入一个注意力驱动的伪标记方案,将注意力得分高,但不匹配任何已知类别的预测框标记为未知类别。利用伪未知样本和ground truth已知样本训练一个分类器,区分未知对象和已知对象。
- 引入一个置信度分支,通过将构成前景对象的特征从已知类转移到未知类,以学习前景对象和背景之间的区别。
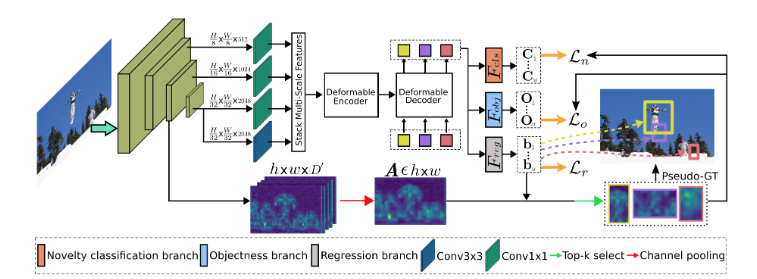
22. Unknown-Aware Object Detection: Learning What You Don’t Know from Videos in the Wild
- 作者:Xuefeng Du, Xin Wang, Gabriel Gozum, Yixuan Li
- 引用:5
- 任务:视频中未知感知的目标检测
- 创新点:
- 我们提出了一个新框架,称为时空未知蒸馏(STUD)。据我们所知,我们是第一个利用视频中丰富的信息,为目标检测模型进行面向对象的识别的方法。
- STUD 通过在空间和时间维度提取不同的未知物体,有效地规范了物体探测器,而不需要对 OOD (未知分布)物体进行昂贵的人工注释。此外,我们表明,STUD 比在高维像素空间合成未知(例如GAN)或使用负样本作为未知更有利。
- 我们在大规模 BDD100K 和 Youtube-VIS 数据集上广泛评估拟议的 STUD。STUD 获得了最先进的结果,大大优于最佳基线(BDD100K 上 FPR95为10.88%) ,同时保持了 ID 数据上目标检测的准确性
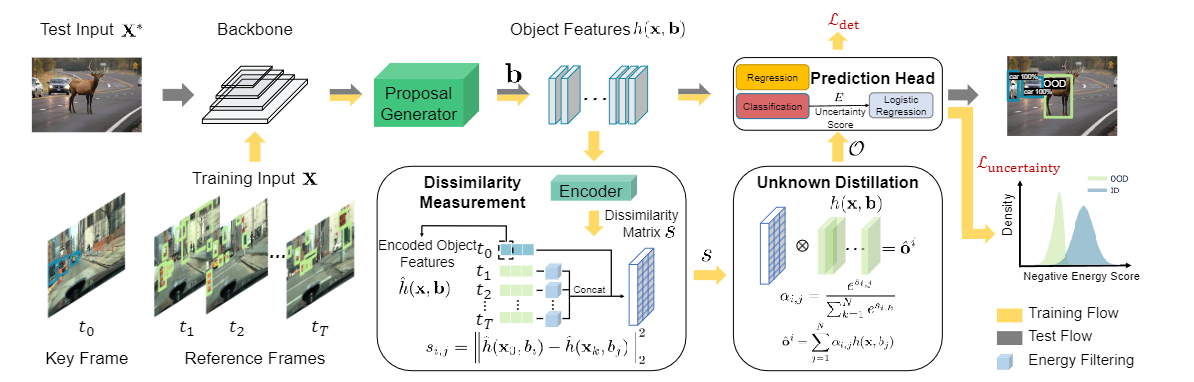
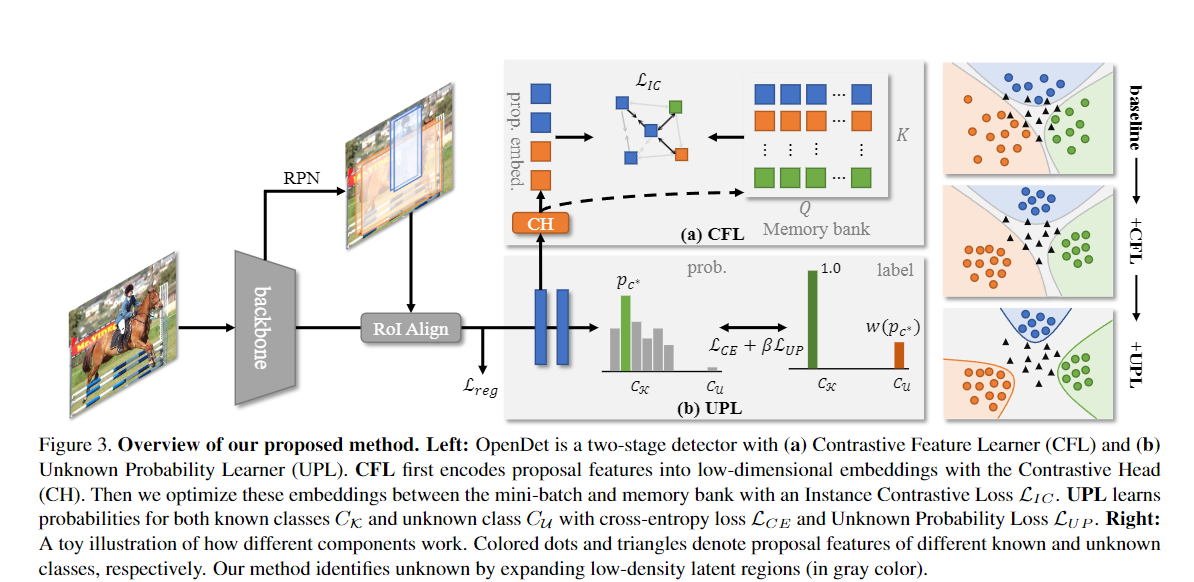
23. Expanding Low-Density Latent Regions for Open-Set Object Detection
- 作者:Jiaming Han, Yuqiang Ren, Jian Ding, Xingjia Pan, Ke Yan, Gui-Song Xia
- 引用:1
- 任务:Open-Set目标检测(OSOD)
- 除了检测识别已知物体外,还会检测一些未知类别的物体
- 创新点
- 是第一个通过模拟低密度潜在区域来解决 OSOD 的方法
- 提出了一种新的开集检测器(OpenDet) ,它有两个设计良好的模型,**对比特征学习(CFL) **和 未知概率学习(UPL),可以通过端到端的方式进行训练,并直接应用于开集环境。
六、增量目标检测
24. Overcoming Catastrophic Forgetting in Incremental Object Detection via Elastic Response Distillation
- 作者:Tao Feng, Mang Wang, Hangjie Yuan
- 引用:1
- 任务:增量目标检测(IOD)
- 创新点
- 本文首次探讨了基于响应的 IOD 蒸馏方法,剖析了基于特征和基于响应的 IOD 解决方案之间的本质区别。
- 提出基于统计分析的 弹性反应精馏( ERD ) 方法,根据提出的弹性反应选择( ERS )策略分别提取选择性分类和回归响应。
- 在 MS COCO 上的大量实验表明,该方法达到了最先进的性能,可以很容易地推广到不同的检测器
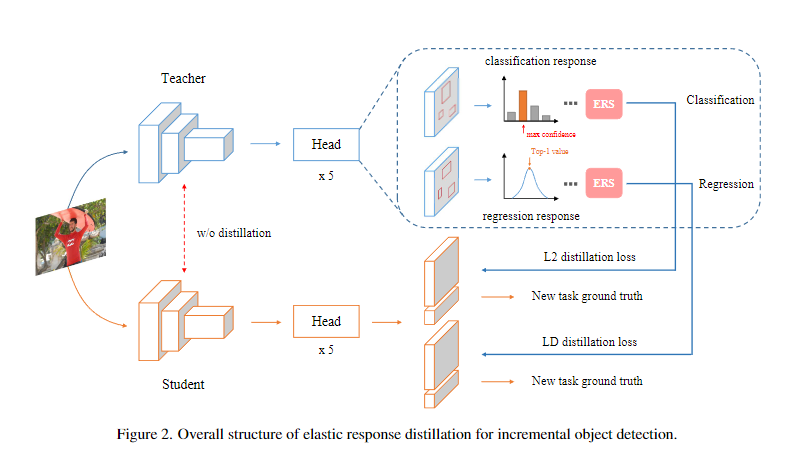
七、小目标目标检测
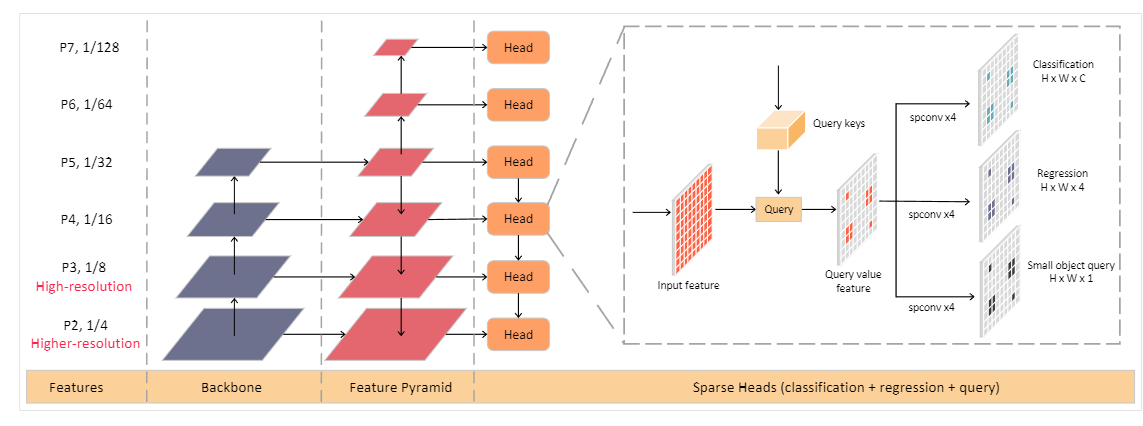
25. QueryDet: Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection
- 作者:Chenhongyi Yang, Zehao Huang, Naiyan Wang
- 引用:12
- 任务:小目标检测
- 创新点
- 提出了QueryDet,降低了所有基于特征塔的目标检测器的计算成本。该方法在保持快速推理速度的同时,有效地利用了高分辨率特征,提高了对小目标的检测性能
- 级联稀疏查询:首先在低分辨率特征上预测小目标的粗略位置,然后在高分辨率特征上集中计算相应的确切位置。这个过程可以看作是一个查询过程: 粗略的位置是查询键,用于检测小对象的高分辨率特性是查询值
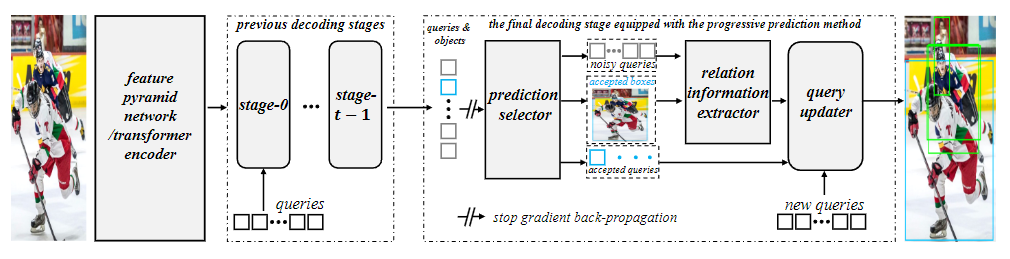
26. Progressive End-to-End Object Detection in Crowded Scenes
- 作者:Anlin Zheng, Yuang Zhang, Xiangyu Zhang, Xiaojuan Qi, Jian Sun
- 引用:2
- 任务:密集目标检测
- 创新点
- 提出了一种渐进式预测方法,该方法使用预测选择器、关系信息提取器、查询更新器和标签分配器来提高基于查询的目标检测器在处理拥挤场景时的性能
- 预测选择器:选择与高置信度得分相关的查询作为接受的查询,其余的查询作为噪声查询。
- 关系提取器:用于噪声查询与其接受邻居之间的关系建模,从而让噪声查询“感知”其目标是否已被检测到。噪声查询用于对检测结果的补充,一个物体如果被选择器判断为可接受的,那么就不需要进行关系提取.
- 查询更新器:通过执行一个新的局部自注意机制,只关注空间相关的邻居
- 标签分配器:被接受的查询倾向于产生真阳性,而噪声查询包括相当数量的真阳性和假阳性。因此提出了一种新的一对一标签分配规则,用于在已接受的和经过细化的噪声查询之间分配样本。
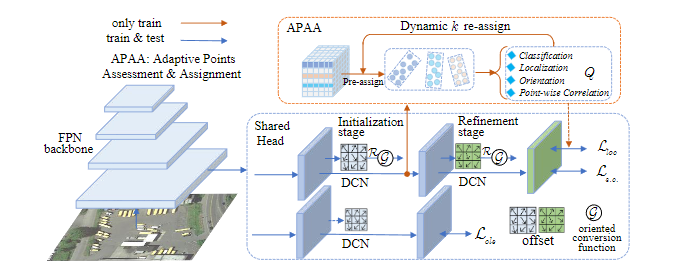
八、有向目标检测
27. Oriented RepPoints for Aerial Object Detection
- 作者:Wentong Li, Yijie Chen, Kaixuan Hu, Jianke Zhu
- 引用:12
- 任务:空中目标检测
- 创新点
- 提出了一种有效的空中目标检测方法,该方法通过引入灵活的自适应点来实现目标检测。首先从中心点生成初始自适应点,进一步细化自适应点以适应空中目标,根据点的布局生成有向位置框
- 针对点集学习问题,提出了一种有效的自适应点评估与分配方案。这种方法使检测器能够从相邻目标或背景噪声中捕获非轴对齐特征,从而分配具有代表性的样本。
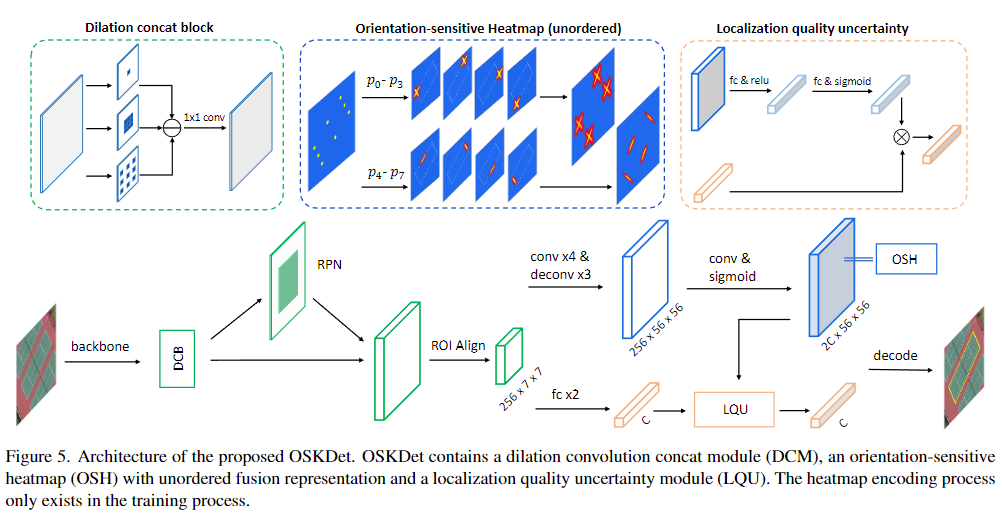
28. OSKDet: Orientation-Sensitive Keypoint Localization for Rotated Object Detection
- 作者:Dongchen Lu, Dongmei Li, Yali Li, Shengjin Wang
- 引用:0
- 任务:有向目标检测
- 创新点
- 提出了一种基于关键点热图的有向检测器 OSKDet。为了更好地表示旋转目标,我们设计了一种方向敏感的热图,它能够了解旋转目标的形状和方向,对提高定位精度有着重要的作用。
- 探索了一种新的无序关键点热图融合方法。这种新的表示方法可以消除基于规则的关键点排序引起的学习混乱。
- 提出了一种定位质量不确定性模块,通过关键点定位分布的特征融合,有效地提高了分类得分的置信度。
九、其他
29. Interactron: Embodied Adaptive Object Detection
- 作者:Klemen Kotar, Roozbeh Mottaghi
- 引用:0
- 任务:在交互环境中自适应目标检测
- 现有模型都在固定的训练集与测试集上进行,训练完成后冻结所有参数,这与真实世界情况不符
- 通过与环境的互动,在没有任何显式监督的情况下继续更新模型参数(在测试时训练)
- 创新点
- 提出了一种自适应目标检测方法,在训练和推理过程中对模型进行更新,模型在推理过程中通过与环境的交互学习适应,而不需要任何明确的监督。

30. Confidence Propagation Cluster: Unleash Full Potential of Object Detectors
- 作者:Yichun Shen, Wanli Jiang, Zhen Xu, Rundong Li, Junghyun Kwon, Siyi Li
- 引用:0
- 任务:目标检测后处理
- NMS的替代
- 创新点
- 提出了一个新的聚类框架(CP-Cluster),适用于所有需要后处理的目标检测器,并且这个新的聚类框架的表现优于准确性中基于NMS的效果。
- CP-Cluster将所有候选框从位置框转换为一组图正例和负例在每个图中迭代传播,进而增益真正的正例并且抑制冗余框。
- 将CP-Cluster应用于各种主流探测器,而无需重新训练,包括FasterRCNN,SSD,FCOS,YOLOV5 等。
最后
以上就是风中魔镜最近收集整理的关于CVPR2022目标检测文章汇总+创新点简要分析CVPR 2022的全部内容,更多相关CVPR2022目标检测文章汇总+创新点简要分析CVPR内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复