
论文地址:https://ieeexplore.ieee.org/document/9008383
源码地址:https://github.com/Gabriel-Macias/robust_frcnn
1 以前的方法
在目标域中有监督地fine-tuning /无监督地学习跨域表征。前者需要额外的带标签实例数据,后者消除了两个新挑战带来的cost:①source/target域的表征要在某个空间上匹配 ②要定义一个特征匹配的机制(MMD、H-divergence、adversarial learning)
2 观察
尽管在源域训练好的模型在目标域上测试会有次优解,但目标检测会有一定准确率。检测出来的目标可以用来retrain模型,但又因为model在target domain检测出来的实例不准确,所以在retraining过程中要用一个鲁棒性好的检测框架。这带来的好处是model在target domain上的训练方式是无监督的,通过向model喂源域和目标域的数据,可以实现域间表征的匹配。
3 两种noise
- 目标标签的错误(分类错误);
- 不正确的bbox位置和尺寸(bbox不能紧包围目标);
4 方法
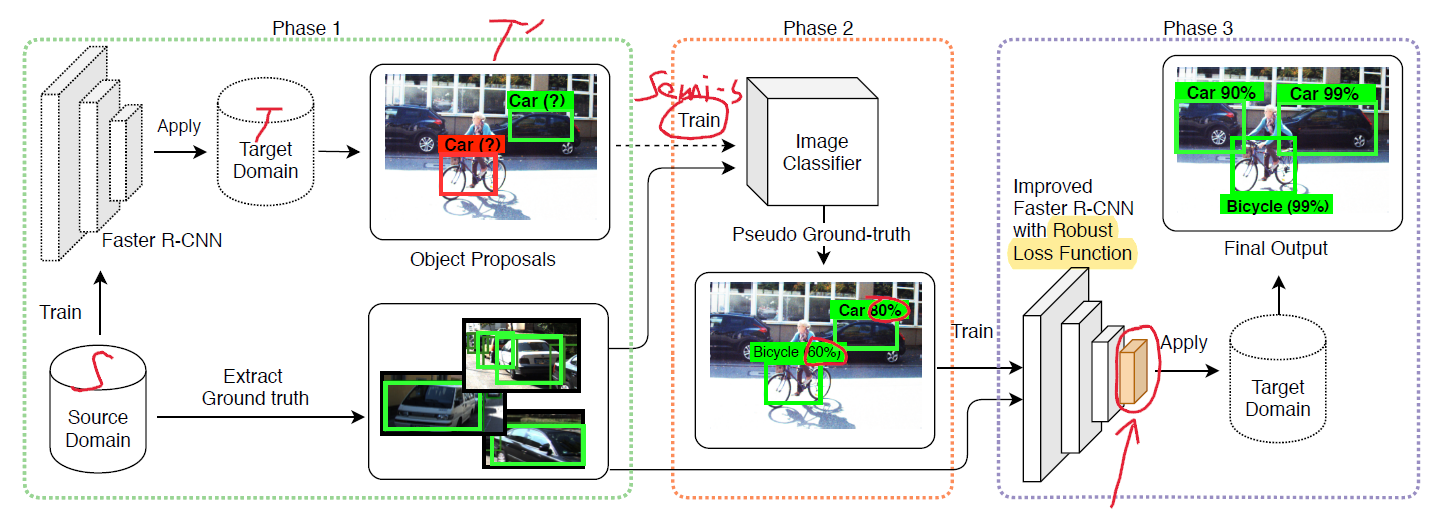
辅助图像分类训练
先从目标域中提取一些gt的bbox,然后用这些bbox去训练一个分类模块,用这个分类模块给target domain的bbox评分,这可能会用到Phase One中没用到的representation。![]() 代表由bbox剪切出来的img的类别,包括前景类别和背景。
代表由bbox剪切出来的img的类别,包括前景类别和背景。
以概率的视角看待Faster RCNN
ROI分类器预测出RPN产生的bbox的分类分数和位置。其中分类预测![]() ,定位预测建模为一个多元正态分布
,定位预测建模为一个多元正态分布![]() ,一个均值为
,一个均值为![]() ,常值对角协方差矩阵
,常值对角协方差矩阵![]() ,实际上只有均值是由ROI分类器产生的,用来定位目标。
,实际上只有均值是由ROI分类器产生的,用来定位目标。
5 鲁棒Faster RCNN
要有一个校正的机制,去校正那些错误的信息location/size,故提出问题:

噪声标签存在情况下,argmaxp_cls以及 argmaxp_loc可能会否决掉噪声标签,但无论如何准确地识别出特征的类别或位置。此外,也有一个图像分类模型p_img可能会更加准确地预测出target domain的bbox的类别标签,因为它训练时用到了一开始训练任务所没有用到的信息。如何合并FasterRCNN的p_cls、p_loc以及img model的p_img来得到一个目标更准确的类别和位置?
Vahdat提出了一个EM算法,图像分类模型的鲁棒训练方法。--》由此算法激发,提出两个机制来校正分类和定位的误差,基于存在噪声标签实例下训练分类模型时,真实标签的分布应该不仅靠近潜在分类模型生成的分布,还应该靠近从其他数据源获得的辅助分布。
5.1 Classification Error Correction
作者找一个分布q(y_c),靠近于Faster RCNN的分类模块p_cls和图像分类模型p_img,并提出推断q(y_c)的目标函数:
![]()
KL即Kullback-Leibler divergence,且α>0平衡两项的值,如果α的值很大,q会倾向于p_img,反之倾向于p_cls,在训练过程中,α的值可以改变来让两个分布达到一个理想的平衡状态。然后解出上述目标函数的闭合解:
首先提出定义1:

证明过程:
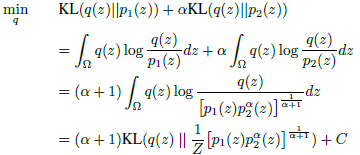
此处的Z是![]() 的标准化,C是一个与q无关的常值,由此可以的得到目标函数的闭合解:
的标准化,C是一个与q无关的常值,由此可以的得到目标函数的闭合解:
![]()
因为p_cls和p_img都是softmax激活后的解,q(y_c)同理。在训练过程,将α的值从大到小改变,因为在训练一开始,p_cls的结果不准确,对于准确类比标签的预测不佳,因此将α设置为一个较大的值,让q(y_c)更多地依赖p_img。
5.2 Bounding Box Refinement
有了上面对于类别的refine之后,用类似的方法对location和size进行refine,回想起Faster RCNN的定位预测可以认为是正态分布![]() 。令
。令![]() 为图像x的起始检测结果。Faster RCNN每一代用
为图像x的起始检测结果。Faster RCNN每一代用![]() ,以图像x和proposal
,以图像x和proposal![]() 预测目标的位置,用类似方法定义一个正确目标定位的分布q的目标函数:
预测目标的位置,用类似方法定义一个正确目标定位的分布q的目标函数:
![]()
定义2:
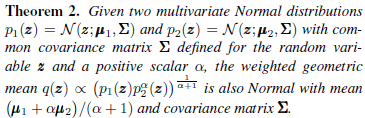
证明过程:
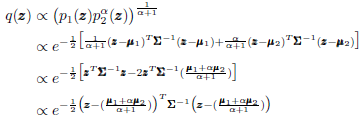
所以,
![]()
故由此可得上述目标函数的最小值
![]()
当α=∞时,忽略Faster RCNN当前输出;当α=0时,用它的输出作为定位值。在训练过程中,将α设置为较大值,并逐渐减小,因此在训练一开始时,q依赖于p_init因为它比模型当前输出更准确,后期p_loc更准确,所以q更依赖p_loc。
5.3 Training Objective Function
当实例来自于源域,只用FasterRCNN的原始loss fcn来更新参数;
当实例来自于目标域,用上述的q(y_c)和q(y_l)来修正bbox的标注,q(y_c)作为CE loss fcn中误分类项的soft target labels,![]() 作为回归项的目标定位,这里的修改只发生在ROI classifier的loss fcn上,因为RPN是class-agnostic的。
作为回归项的目标定位,这里的修改只发生在ROI classifier的loss fcn上,因为RPN是class-agnostic的。
5.4 False Negative Correction
上述方法只会修正阶段一得到的object proposals,使得模型能够修正false positive(没有包含到任何前景的目标的实例或者包含一个类别与预测类别不一样的目标)的错误。但还要修正false negative(前景类别的positive实例在第一阶段没有被检测到),在这一阶段中这些实例定义为hard negative,依赖FasterRCNN的hard negative挖掘阶段,将hard negative增加为训练集的背景实例。
因此,源域中提取的hard negative就是背景,但目标域提取的“背景”实例也可能包括前景目标,因此在训练时遇到第二种情况时,定义![]() 为soften one-hot向量,设置背景的概率为1-ϵ,其他类别的归一化为ϵ
为soften one-hot向量,设置背景的概率为1-ϵ,其他类别的归一化为ϵ![]() /C,用到CE loss的soft target label。
/C,用到CE loss的soft target label。
6 Image Classification
Image classification model半监督地训练,样本从源域(干净的训练集)和目标域(带噪声标签的的样本集)中crop出来。对于源域图像,用CE loss against gt labels;对于目标域,用CE loss against soft labels,这里会计算到预测的分类数据和softened one-hot annotation vector的加权几何平均值。《Toward robustness against label noise in training deep discriminative neural networks》
最后
以上就是完美冰棍最近收集整理的关于论文笔记:A Robust Learning Approach to Domain Adaptive Object Detection1 以前的方法2 观察3 两种noise4 方法5 鲁棒Faster RCNN6 Image Classification的全部内容,更多相关论文笔记:A内容请搜索靠谱客的其他文章。








发表评论 取消回复