本文介绍 3D单目目标检测从入门到做自己的Tesla
这篇教程是一个新纪元,如果你还没有学完目标检测从入门到精通,不妨可以关注一下我们的专栏,职业输送高科技干货知识,关注这一个专栏你便可以掌握所有AI以及机器人相关的知识。如果你目标检测已经觉得自己牛逼到了极点,那接下来可以来挑战下一个任务,进行单目的3D目标检测。
如果你不知道Tesla是什么,进入官网http://tesla.cn了解一下,听说最近马斯克把FSD涨价一千美元了,声称FSD的价值高达数十万美元,这一涨价一台iPhone没了,工资没怎么长,要买的东西疯了似的涨。没办法,虽然国情就如此呢,既然你涨那么猛,不如我们来模仿一下你的核心技术,FSD最牛逼的是啥?不外乎是基于摄像头的一整套自动驾驶系统。今天我们要做的,就是用一个超级简单的模型,来做一个3D的单目目标检测模型。
在这个教程里面,涉及到的东西比较多,比如:
摄像头的投影矩阵,位姿变换;
基于关键点热力图的预测模型;
3D世界坐标系与摄像头坐标系的转换;
摄像头坐标系与像素点的转换;
摄像头内参外参的概念;
必要的深度学习知识。
讲了这么多,先来看看我们要实现的单目3D检测的效果把:

3dsmokemono
我们实现将构建在smoke之上。在smoke之前,其实也有很多尝试使用单目进行3d检测的网络模型,比如CenterNet3D,比如RTM3D等,最新smoke似乎表现出了最好的性能,实测下来在速度和精度上都有一个不错的均衡。
smoke我们有一个fork的版本,在这上面我们做的改进主要有:
原始版本只能从dataloader里面做inference,我们实现了只需要输入一张image,就可以将3D框预测出来并visualize;
原始的版本有着各种各样的路径bug,而现在你可以传入一个KITTI的video sequence path,就可以直接对这个video进行预测,所有的内参外参都自动帮你处理;
原始的版本依赖于DLA,我们尝试修改了不同的骨干网络,实验发现,更轻量的网络可以在更小的计算量下获得差不多的性能。
我们探索了模型在wild数据上的效果,比如我们从网上找的交通场景的3D检测方法(当然前提是你得知道摄像头的内参),具体实验结果我们也在我们的fork版本中有提供。
BTW,smoke这篇论文应该是纵目科技做的。
01 smoke模型结构

从模型层面来说,背后idea也很简单,通过前置的网络得到一系列的热力图,对这些热力图进行分类和定位,这里和centernet或者说其他模型不同的地方就在于,回归的不是4个点,而是6个点。包含哪6个点?
whlxyz
其实就是定义物体的尺寸和位置。事实上仅有这些还是不够的,因为如果你是一个空间的自由物体,你会有俯仰,还有侧倾,因此真正定义一个物体的姿态是需要在加上3个自由度的,事实上,在大多数情况下,我们的汽车不太可能在水平上面上进行翻转,包括人也是。因此我们在加上一个水平上的转向角就够了。
这就构成了我们用单目进行3D检测的解决方案。
在我们fork的版本的代码中,有一段这样的定义:
class KittiSmokeDetectionInfo(object): def __init__(self, line): ''' [ 0.0000000e+00 1.6826042e+00 4.7441586e+02 1.8074373e+02 5.3575635e+02 2.2734413e+02 1.4526575e+00 1.6065563e+00 3.7408915e+00 -6.1363697e+00 -2.0827448e-01 3.2981182e+01 1.4986509e+00 6.4066571e-01] ''' self.name = line[0] # self.truncation = float(line[1]) # self.occlusion = int(line[2]) # local orientation = alpha + pi/2 self.alpha = float(line[1]) # in pixel coordinate self.xmin = float(line[2]) self.ymin = float(line[3]) self.xmax = float(line[4]) self.ymax = float(line[5]) # height, weigh, length in object coordinate, meter self.h = float(line[6]) self.w = float(line[7]) self.l = float(line[8]) # x, y, z in camera coordinate, meter self.tx = float(line[9]) self.ty = float(line[10]) self.tz = float(line[11]) # global orientation [-pi, pi] self.rot_global = float(line[12])
这其实就是将smoke模型里面的每个index的值的定义进行了分配,这方便与我们后面拿取其中的数值进行推理和可视化。

论文效果显示,其精确度远超现有的单目3D检测方法,包括Centernet,实际上预测效果也不错。
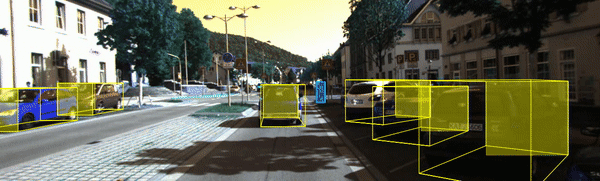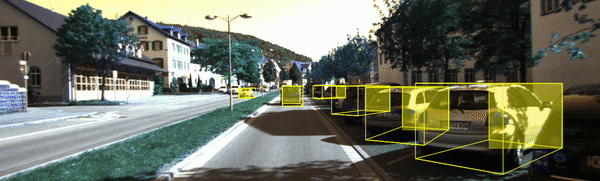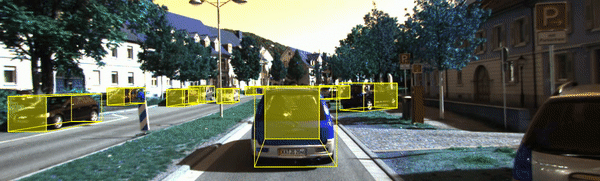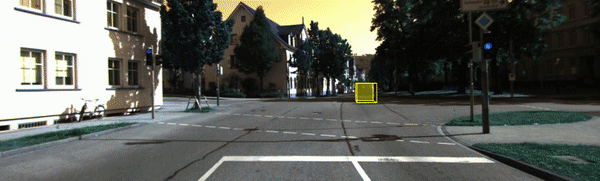


02 端到端的单目3D目标检测
单目3D检测有一个很直接的问题,训练出来的模型是否和摄像机的外参数有关?事实上,通常情况下,我们在做一个单目3D模型的时候,会使用一个固定的摄像机内参,典型的例子如Centernet3D,这种训练出来的模型只能在固定的场景下用,如果你换一个摄像机,或者你自己有一个摄像机,知道内参,然后随便拍一张照片或者录制一段驾驶视频,预测出来的结果应该是不准的。
在smoke模型训练的时候,需要提供的参数包括:
标注的物体长宽高,在真实3D环境下的物体尺寸,单位是m;
摄像头的内参,其实这个内参主要是将物体的中心点位置,映射到摄像机的坐标系下;
物体的中心点位置;
物体的航向角。
这里需要注意的是,实际上我们并不需要更多的角度自由度,只需要一个Y轴的转向角即可,这个我们将用来估算3Dbox的转向姿态。
在我们的fork代码中,你可以只输入一张图片,就可以完成3D框的预测,使用我们预先设定好的内参。(注意,这么做是因为KITTI数据中大部分的摄像机内参差不多,我们测试了很多段视频,即便是互相使用内参,结果也差不多)。当然这只是映射到图片之后的效果,可能真实场景下的效果会不准,但是谁care呢,毕竟你深度不知道(此处需要毫米波雷达)。
data_f = args.data
calib_f = args.calib_file
if not calib_f:
calib_f = os.path.join(os.path.dirname(
os.path.dirname(data_f)), 'calib_cam_to_cam.txt')
print('calib file: ', calib_f)
# we have to load image sequence or image's intrinsics K first
K = get_P_from_str(
'7.215377e+02 0.000000e+00 6.095593e+02 4.485728e+01 0.000000e+00 7.215377e+02 1.728540e+02 2.163791e-01 0.000000e+00 0.000000e+00 1.000000e+00 2.745884e-03')
K = K[:3, :3]
calib = get_P_from_str('7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 3.485728000000e+01 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 1.163791000000e-01 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.745884000000e-03')
print('K: ', K)
print('P: ', calib)
if os.path.isdir(data_f):
all_imgs = glob.glob(os.path.join(data_f, '*.png'))
all_imgs = sorted(all_imgs)
print(all_imgs[0])
img = cv2.imread(all_imgs[0])
videowriter = cv2.VideoWriter('res.mp4', cv2.VideoWriter_fourcc(*'DIVX'), 25, (1242, 375))
for img_f in all_imgs:
# img = cv2.imread(img_f)
img = Image.open(img_f)
inn, target = prepare_data(img, cfg, K)
# 开始预测大家请注意,在KITTI中,testing和training的calib标注格式是一样的,你一般只需要拿到这个P。而在sequence的raw data里面,calib的标注格式和他们不同。
你需要拿到的也是这个P,但是K实际上P左上角的3x3的矩阵。也就是说P实际上是内参和外参的综合体。实际预测的时候我们拿到这个P就可以了,我们提供了方法抽取出内参K和calib矩阵。
03 最后
尽管我们在视频上通过标定好的内外参数,准确的可视化了我们的3D检测结果,基本上证明了3D目标检测的可行性以及它的准确性,但还有几个问题值得我们深入思考:
模型真的是sensor independent的吗?假如我们有自己的数据集,用KITTI train的模型,是否也可以inference?
如果我们要train自己的data,我们如何去prepare我们的数据?需要用到Lidar吗?
AI算法后丹修炼炉是一个由各大高校以及一线公司的算法工程师组建的算法与论文阅读分享组织。我们不定期分享最新论文,资讯,算法解析,以及开源项目介绍等。
最后
以上就是每日一库最近收集整理的关于3d目标检测_3D单目目标检测从入门到做自己的Tesla的全部内容,更多相关3d目标检测_3D单目目标检测从入门到做自己内容请搜索靠谱客的其他文章。








发表评论 取消回复