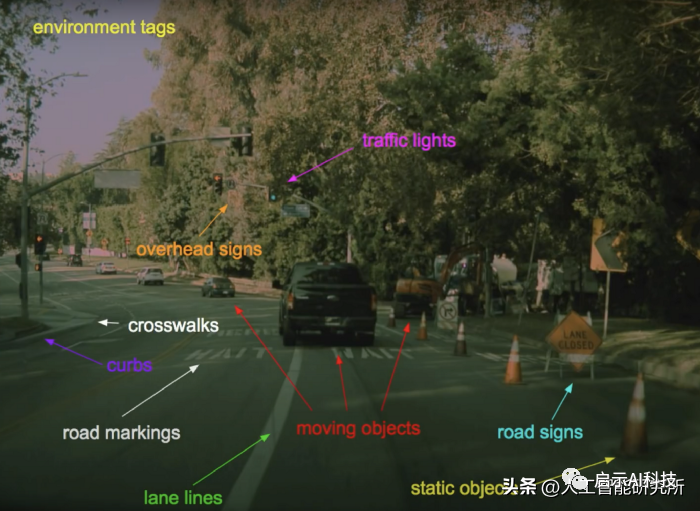
特斯拉的自动驾驶仪无疑是目前最先进的计算机视觉系统,从自动驾驶汽车最重要的功能,车道检测到行人跟踪,再到信号灯识别等等,它们必须涵盖所有道路信息,并预测每种情况。因此特斯拉发布了“ Tesla Vision ” 相机制成的感知系统,特斯拉的计算机视觉新系统只配备了8个摄像头……这种纯计算机视觉的应用,使其成为世界上唯一不使用雷达的自动驾驶公司之一!

从下面视频中,我们可以看到特斯拉的计算机视觉系统。车辆周围的 8 个摄像头(左,搜集车周围的影像)通过神经网络生成 3 维“向量空间”(右,生成最终的车道信息),代表自动驾驶所需的一切信息,如线条、边缘、路缘、交通标志、红绿灯、汽车;汽车的位置、方向、深度、速度等等信息,而这一些的实现,只是特斯拉上面的8个摄像头与自动驾驶系统来实现的。其中自动驾驶系统中,最重要的便是来训练处理8个摄像头采集到的影像信息的神经网络模型了。

其最初研究计算机视觉时,人们也是参考了人类的视觉系统,当眼睛搜集的信息到达视网膜后,经过大脑皮层的多个区域、神经层,最终形成生物视觉,我们才能在脑中生成图像。计算机视觉系统就是参考这样的设计来设计目前的计算机视觉神经网络系统,而计算机视觉任务中,物体检测一般有如下通用的结构:
Input → backbone → neck → head → Output
Backbone:指特征提取网络,用于识别单个图像中的多个对象,并提供对象的丰富特征信息。我们经常使用 AlexNet、ResNet、VGGNet 作为骨干网络。
检测头(head):在特征提取(骨干)之后,它为我们提供了输入的特征图表示。对于一些实际的任务,比如检测对象、分割等。我们通常在特征图上应用一个“检测头”,所以它就像一个头附着在主干上。
neck:颈部位于主干和头部之间,用于提取一些更精细的特征。(例如特征金字塔网络(FPN),BiFPN)
最初,在目标检测任务中,特斯拉使用了一些手动设计的网络,例如 AlexNet、VGG、ResNet、DenseNet等神经网络主干。后来,随着数据规模和网络深度的增加,相关特斯拉研究人员开始考虑使用半自动化网络设计和自动化网络设计来代替人工网络设计。
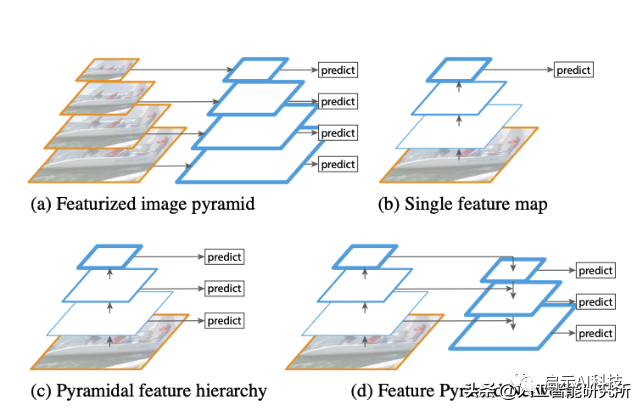
2020 年 Facebook 人工智能研究 (FAIR) 论文Designing Network Design Spaces中提出了一种新的神经网络Regnet(正则网络结构)。经过神经网络主干处理后,RegNet给出了不同尺度、不同分辨率的多个特征。在这个特征提取网络中,在最底部,我们有非常高的分辨率和非常低的通道数,而在顶部有高通道数,且低分辨率。所以底部的神经元用于检查图像的细节,顶部的神经元用于理解场景上下文(语义)信息
正是RegNet神经网络这样的特性,特斯拉使用 Regnet(正则网络结构)作为其神经网络主干。
Hydranets——特斯拉的疯狂神经网络
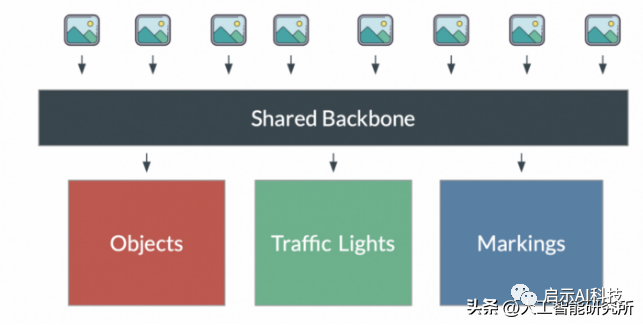
而检测头部分,特斯拉由于要在一个神经网络中,需要检测很多任务,比如车道线检测,人物检测与追踪,信号灯检测等等,而以往的计算机视觉任务中,我们的神经网络最终只有一个输出头,要么是对象检测,要么是实例分割,等等,显然,在一个自动驾驶系统中,这样的神经网络不太实用,且我们也不能同时运行多个神经网络模型来控制自动驾驶系统,这样的话,很容易引起神经网络之间的问题,计算机视觉系统处理也很困难。

特斯拉将这些任务融合在一个新的架构中,有一个共同共享的主干并分支成多个头。这种架构称为 HydraNets。简称九头蛇网络,当然,并不是输出只有9个头,毕竟自动驾驶的计算机视觉任务,不是9个头就可以处理的。
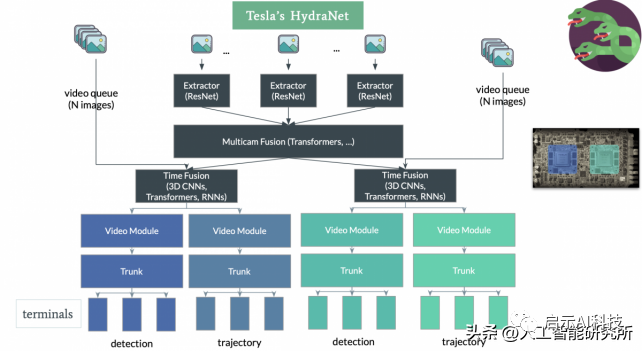
1、所有 8 幅图像首先由图像提取器处理。为此,使用了类似于 ResNet 的架构,Regnet(正则网络结构)
2、然后是多机位融合。这个想法是将所有 8 个图像组合成一个超级图像。为此,HydraNets使用了类似transformer的架构。
3、时间融合。这个想法是将时间带入神经网络,并将超级图像与所有先前的超级图像融合在一起。为此,有 N 个图像的视频队列。例如,如果他们想用 2 秒进行融合,并且假设摄像机以每秒 30帧的速度工作,N 将为 60。时间融合是使用 3D CNN、RNN 或 Transformer 完成的。
4、最后,输出被分成 HEADS。
需要注意的一点:正如上图所看到的,整个神经网络模型都被分成了左右2部分:这实际上是神经网络模型在 2 个芯片上并行运行的方式.

特斯拉的TPU
HydraNets 具有三个主要优点
特征共享:减少重复卷积计算,减少主干数量,在测试时特别高效
解耦任务:将特定任务从主干中解耦,能够单独微调任务
Representation Bottleneck:训练时缓存特征,在做微调工作流时,只使用缓存的特征微调头部。
HydraNet 训练工作流程:
1、进行端到端培训,他们共同训练所有内容
2、在多尺度特征级别缓存特征。
3、使用缓存功能微调每个特定任务
4、再次进行端到端培训并进行迭代。
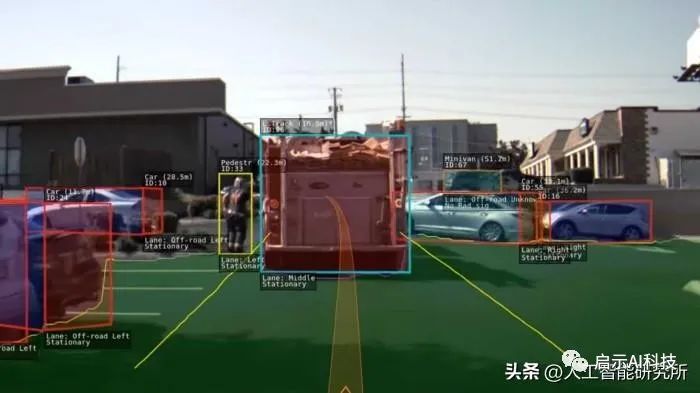
下图是一个版本的 HydraNet 中处理单个图像得到的一些预测

而特斯拉如何训练其神经网络那?如何训练 Hydranet?

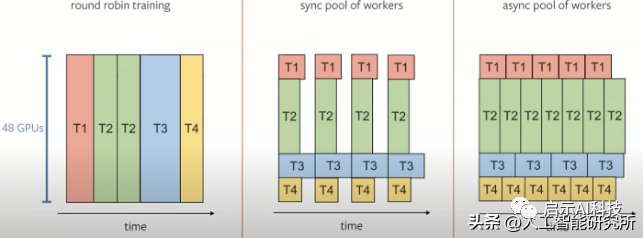
根据特斯拉团队的说法,在 GPU 上训练一个有 48 个头的神经网络需 70,000 小时!差不多8年了,特斯拉团队为了解决这个问题,把训练模式从 “round robin”模式转换为“pool of workers”模式.这样就大大缩短了训练时间,且我们从HydraNets神经网络架构中知道,特斯拉还使用了双MCU架构,并行处理。
Transformer模型作为NLP与图片视频领域中,最重要的模型构架,在最近今年越来越受到了重视,虽然Transformer模型刚开始设计,是在NLP领域,但是随着VIT模型,以及SWIN模型的发布,把Transformer模型也有效的应用到了CV计算机视觉领域,让Transformer模型也能够进行CV领域的任务处理
更多Transformer模型VIT 模型SWIN Transformer模型参考头条号:人工智能研究所
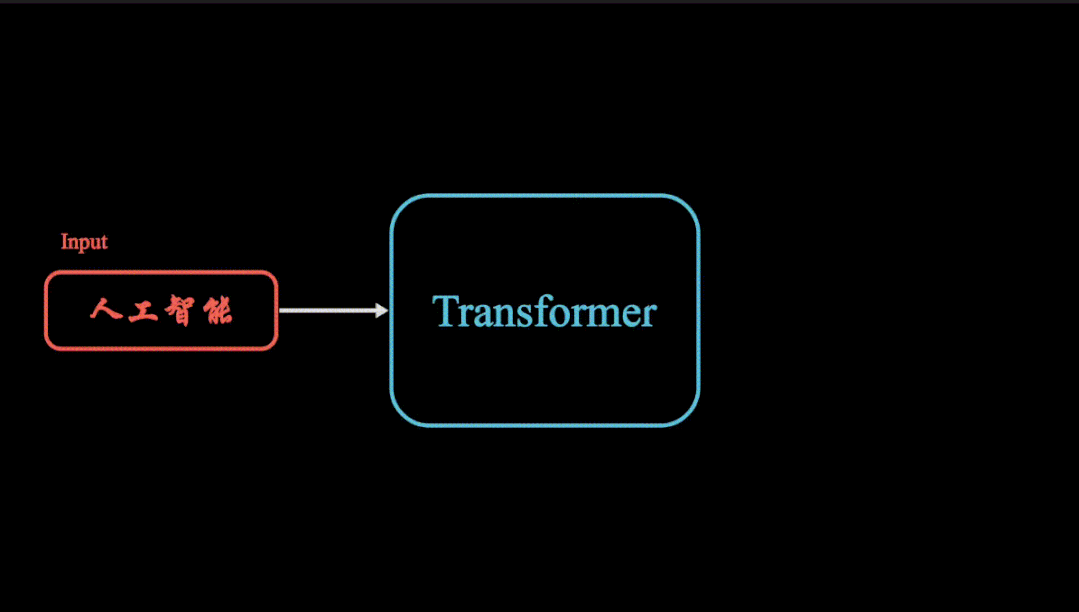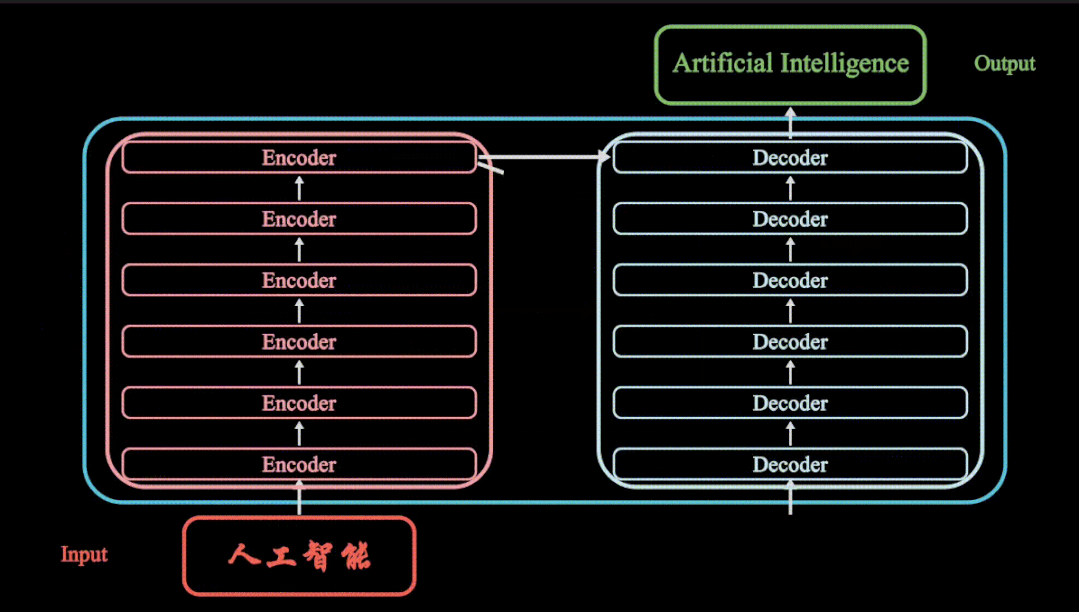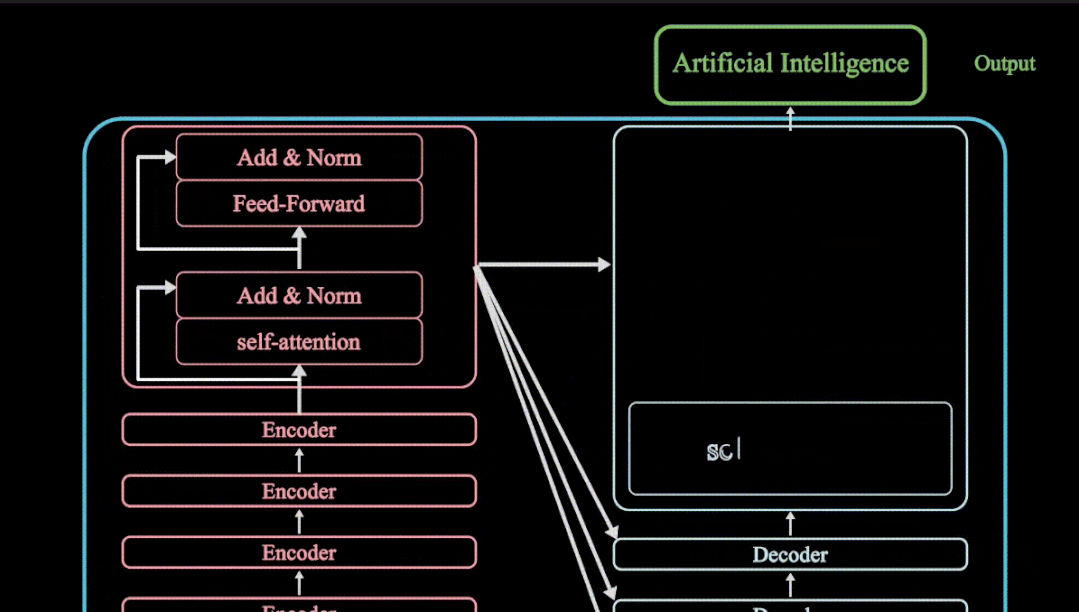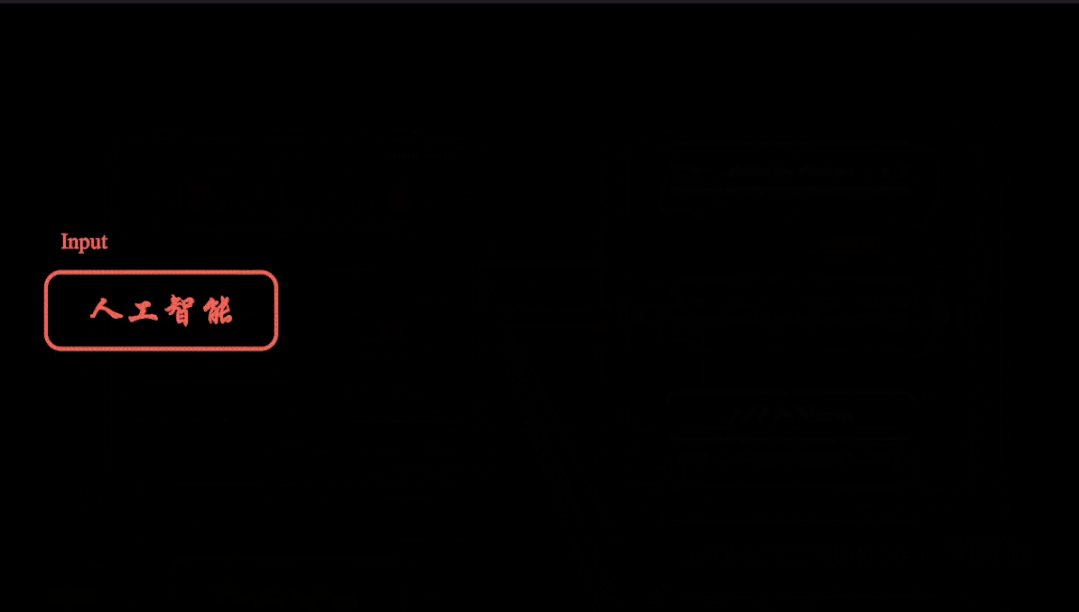
VX搜索小程序:AI人工智能工具,体验不一样的AI工具
最后
以上就是土豪芒果最近收集整理的关于HydraNet——特斯拉自动驾驶强大的人工智能神经网络模型的全部内容,更多相关HydraNet——特斯拉自动驾驶强大内容请搜索靠谱客的其他文章。








发表评论 取消回复