本博客所有内容采用 Creative Commons Licenses 许可使用. 引用本内容时,请保留 朱涛, 出处 ,并且 非商业 .
引入
完成了若干个基于WEB的项目, 也了解了从前端的js,css,html到后端python/php等, 二者如何交互, 最终浏览器如何执行, 这些在心里也已经很明确了. 不过一个问题一直萦绕在心中,那就是:
一个html有若干个外部资源(js,css,flash,image等),这些请求是何时下载的,又是何时执行的?
不清楚,不明白, 所以也就不知道我写的js究竟何时执行的, 也就不知道为什么很多高性能的建议是要将js置于一个 html底端的</body>之前.
如果你也不是很明确,请来和我一起学习吧.
具体分析
首先我们来看一个示例的html页面,如下:
<html>
<head>
<script src="/static/jquery.js" type="text/javascript"></script>
<script src="/static/abc.js" type="text/javascript">
</script>
<link rel="stylesheets" type="text/css" href="/static/abc.css"></link>
<script>
$(document).ready(function(){
$("#img").attr("src", "/static/kkk.png");
});
</script>
</head>
<body>
<div>
<img id="img" src="/static/abc.jpg" style="width:400px;height:300px;"/>
<script src="/static/kkk.js" type="text/javascript"></script>
</body>
</html>
它有如下几种资源:
- 3个外部js文件,1个inline js代码
- 1个外部css文件, 1个inline css代码
- 1个image文件,及1个js请求的image
总共是6个http request.
在分析之前,我们来看看firefox对这个html请求的结果, 如下图:

我们再看看chrome(linux)对这个html的请求结果,如下图(图比较小,可以在新标签中打开):
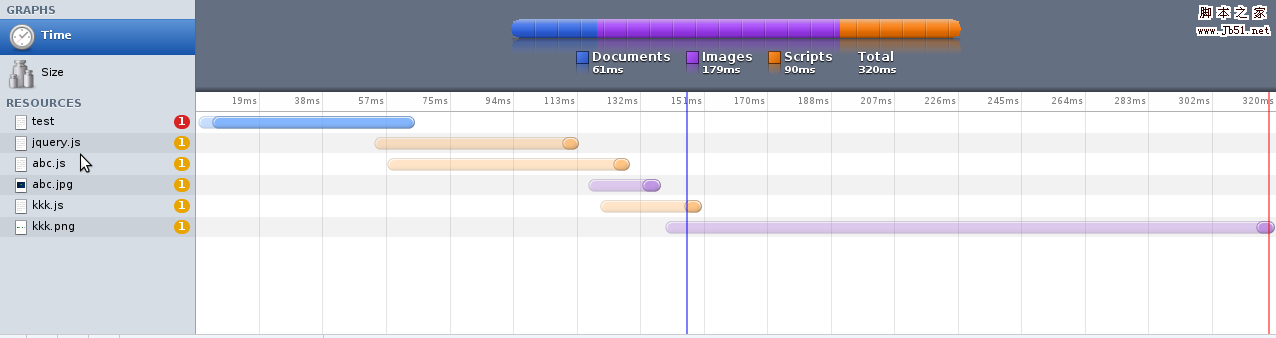
我们先分析下,然后再去说明这2种请求结果的不同.
请求分析
首先说明下面这些描述主要是基于自己google, 咨询朋友和在 SO 和 IRC 上获得, 我并没有阅读相关的spec(当然我很想阅读,如果知道相关spec的朋友请留言谢谢), 不能保证其正确性和准确性,风险自担 :D.
基于相关的调研, 我的理解为, 对于一个URI请求, 浏览器会按照下面的请求和执行顺序进行:
- 一个线程对DOM进行下载(也就是html, 而不去管html中的外部资源)
- 另外一个线程会开始分析已经下载的DOM, 并开始下载其中的外部资源(如js, css, image等)
- 第三个线程(如果有的话)会去下载2正在下载的以外的外部资源
- 如果允许更多的连接, 更多的线程会继续下载其它资源
一个请求可以同时有多少个connection(线程), 取决于不同的浏览器, http1.1 标准中规定的是对于同一个server/proxy(也就是hostname) 不超过2个connection, 但是在实际的浏览器实现中, 具体如下:
Firefox 2: 2 Firefox 3: 6 Opera 9.26: 4 Opera 9.5 beta: 4 Safari 3.0.4 Mac/Windows: 4 IE 7: 2 IE 8: 6
所以请根据这个实际情况来思考上面的下载顺序.
然后我们看执行顺序(js的执行, css的应用等):
- 只要浏览器"看到了"了js代码,它就会执行
- 浏览器是从下到下,一行一行地执行
- 如果js代码位于一个函数或者对象中,则只有当函数或者对象被调用时才会执行
- 而所谓的direct code(不处于函数或者对象中的代码),则会从上到下顺序执行
- 当css文件下载完成时, 相应的样式也会应用到DOM上
- onload或者jquery的$(document).ready()是在DOM下载完成后执行
在实际的浏览器中, 一般遇到<script>标签会自动block住其它线程的下载, 如firefox, 这也是为什么 在web开发中常常推荐将<script>标签置于</body>之前的原因.
但是并非所有的浏览器都block, 如chrome并不会block住其它的connection. 所以具体的load还需要参考具体的浏览器实现.
建议, 将<script></script>标签置于</body>之前, 这样可以在大多数情况下都得到较好的性能.
对Firefox和chrome的请求分析
我们回过头来看下上面2个图中的请求响应图.
Firefox
有如下特征:
- 首先下载html
- html下载完成后, 从上到下依次下载外部文件(js, css,img)
- js会block其它外部文件的下载
- 其它文件会并行下载
chrome
有如下特征:
- 首先下载html
- 从上到下依次下载外部文件(js,css,img)
- 各个资源的下载顺序是并行的
你可能会奇怪如果js可以并行下载,那么可能位于DOM下面的代码会先执行, 首先可以肯定的是 即使下面的js先完成下载,也不会影响到整体的从上到下的执行顺序,浏览器会维护这种顺序的关系, chrome的这种方式也是未来浏览器的一种趋势, 而这也是为什么chrome能够更快的原因之一.
有意思的一个插曲
在提出这个问题后,我便多方入手, 向朋友咨询, 向 SO 提出问题, 甚至去Firefox的 IRC 进行了提问,
回答的朋友还都是很耐心的, 不过, 他们大多向我问了一个问题 做WEB开发, 你为什么要了解这些细节.
对于这样的问题,我还是比较纳闷的, 我一直认为 一个好的程序员,不仅需要知道how, 还要知道what, 甚至why,
知道how,只说明你是一个合格的码工,只会简单地使用别人提供的东西来开发.
知道what, 说明你开始去关注背后是如何实现的, 随着时间推进, 这时候你会逐渐成为一个有经验的程序员.
知道why, 说明你开始向hacker的路迈进了, 开始逐步走向了技术牛人的路线了,长此以往你会有很大的成长的. 参考 How To Become A Hacker.
让我们去享受细节,本质的快乐吧,而不是只停留在我会的层面那么表面的快乐.
结论
浏览器是各大厂商抢占的市场,无论是自主(Firefox, chrome, IE, Opera, Safari)或者基于一定的内核(遨游, 搜狗, TT, 360等), 但是可以肯定的是浏览器会更加强大, 遵守规范, 更快的响应等, 而我们WEB程序员的日子也会好过很多.
本文部分细节还是比较含糊, 后面可能还会在写一篇文章来进行更彻底,清晰的说明.
欢迎讨论.
后记
这次是不惜血本了, 之前积累了快400的 SO reputation score, 一下压出去了150个来寻找最满意的答案.
具体大家可以参考:
Load and execution sequence of a web page?
帖子中有较详细的回答,可以作为参考.
参考资料
- Load and execution sequence of a web page?
- JavaScript DOM load events, execution sequence, and $(document).ready()
- JavaScript Execution Order
- Newbie - when is the CSS applied?
最后
以上就是孝顺白开水最近收集整理的关于让你了解HTML及资源是如何加载的的全部内容,更多相关让你了解HTML及资源是如何加载内容请搜索靠谱客的其他文章。








发表评论 取消回复