在开发的过程中,我们不可避免的会遇到各种各样的编码,解码,或者乱码问题,很多时候,我们可以正常的解决问题,但是说实在的,我们有可能并不清楚问题到底是怎么被解决的,秉承知其然,更要知其所以然的理念,经过一番研究,就有了下面的这篇文章,鉴于本人功力尚浅,有错误请给予纠正 :-)
编码解码核心
简单的来说,编码是从一个字符,比如‘郭',到一段二进制码流的过程。解码是从一段二进制码流到一个字符的过程。
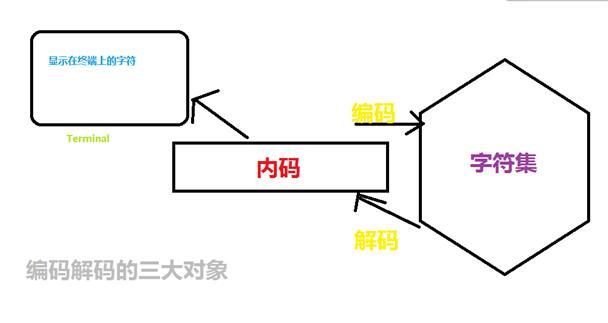
但是,就计算机工作原理而言,这其中涉及到了三个对象。
•字符 (我们在各种终端上面看得到的显示结果)
•内码 (对应显示的字符的计算机存储数据)
•字符集 (内码在内存中的具体实现)
这三者之间的配合如下图。
字符
对于字符而言,是我们程序员而言想必是最熟悉的了吧。什么Abs_=+/.80,都是我们所熟悉使用的字符。虽然我们表面上看到的是一个个的字符,但是在计算机而言,其真正识别和处理的不过是对应于显示的字符的一个个的内码。
内码
内码是汉字在计算机内部存储,处理和传输用的信息编码。它必须与ASCII码兼容但又不能冲突。
也许你会想,ASCII码又是什么? 对此,百度百科是这样解释的:
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
从这里我们不禁会想,既然是单字节编码,那么汉字这种多字节表示的信息又是怎么被计算机识别和处理的呢?
国标码规定:一个汉字用两个字节来表示,每个字节只用前七位,最高位均未作定义。但我们要注意,国标码不同于ASCII码,并非汉字在计算机内的真正表示代码,它仅仅是一种编码方案,计算机内部汉字的代码叫做汉字机内码,简称汉字内码。
所以,这也是国人在平时开发过程中经常会遇到的 乱码问题的根源。
字符集
字符集作为内码在内存中的具体实现,肩负着很大的责任。
•ascii不仅仅指英文对应的内码,还包括它的具体实现,也就是它的字符集。它是用一个字节存储每个内码的。
•unicode是所有文字(包括英文,中文,日文等)所对应的内码的集合。
unicode的实现方式比较多样,常用的有UTF-8,GBK,GB18030。
•其中,UTF-8是一种不定长的内码实现方式。
GB18030兼容GBK,GBK兼容GB2312。
严格点来讲,我们所谓的编码解码问题:编码指内码编码成字符集;解码指字符集解码为内码
-----------------------------------------------
系统编码
众所周知,在不同的操作系统上,支持的编码也是不太一致的。所以我们在跨平台操作的时候,需要重点考虑的问题就包括系统编码问题。
windows
在Windows上查询当前系统的活动代码页,就可以知道当前系统使用的编码。
调出命令行之后输入: chcp 即可。
基本上国人的电脑上会显示936
936 代表GBK 扩展的EUC-CN 编码( GB 2312-80编码,包含 6763 个汉字)到Unicode (GB13000.1-93)中定义的20902个汉字,即中国大陆使用的是简体中文zh_CN.。
Linux
在Linux操作系统上查看系统编码更是方便。
locale是最核心的一个变量。它包括12个基本属性。这12个基本属性构成某个地区的语言习惯,日期,货币,单位等文化因素。LC_ALL是强制修改locale信息的命令。LANG是locale的默认设置命令。因此,当LC_ALL强制locale信息以后,LANG的设置也就失效了。
当然了,我们可以根据自己的喜好,来为自己的linux计算机分配系统编码。
----------------------------------------------------
Python中的编码问题
一般而言,谈到程序编码问题,首屈一指的就是Python语言中的编码了。尤其是Unicode字符集的使用,更是让人摸不着头脑。不过,现在不用担心了,待会我会出绝招滴。
系统编码
经过了刚才的知识的铺垫,大家肯定对此也有了一定的感悟了。Python中的系统编码充当了一个桥梁的作用。其通常也是写源码的编辑器的编码方式。它代表源码文件内的所有内容都是根据词方式编码成二进制码流,存入到磁盘中的。
系统编码可以通过locale命令查看(LINUX)。
说白咯,就是操作系统是怎么存储我们的Python源程序的。
Python编码
这是一个比较新的概念,也是Python编码问题的根源。那就是指python内设置的解码方式。如果不设定的话,python默认是ascii解码。所以我们不难理解为什么有汉字的时候很容易出现乱码的情况了吧。
为了解决Python默认编码不支持汉字的窘境。我们需要手动的设置,让其识别咱们可爱的博大精深的汉字。一般有如下三种方式。
方式一
只能Python识别
在源码文件开头(一定要是第一行):#coding=UTF-8,源码文件的设置解码方式为UTF-8
方式二
可以被其他的语言识别
在源码文件开头(一定是第一行):#--coding:UTF-8--,源码文件的设置解码方式是UTF-8
方式三
我经常使用的方式是方式一加方式三
import sys
reload(sys)
sys.setdefaultencoding('UTF-8')
文件编码
对于文件编码,大体意思就是系统为我们即将存储的文件而进行的编码操作。
实例一
系统编码:locale:gbk python源文件test.py #coding='UTF-8' s='郭' print s
在test.py被保存的那一刻,系统会以gbk的方式将数据存储到本地硬盘上,而在下次我们运行这段代码的时候,Python编码会按照源文件开头指定的utf-8编码来解码并运行,所以遇到'郭'的时候,由于码制的不同,出现乱码或者出现错误就不难理解了。
实例二
系统编码:locale:gbk
test.py
#coding='gbk'
s='郭'
ss=s.encode('UTF-8')
这个时候,系统编码仍然会以gbk的变啊买房时对源文件进行编码处理,但是在遇到ss=s.encode('UTF-8')的时候,会先以Python编码指定的方式将对应的字符串(二进制码流)编码,再按照系统编码对其进一步的编码处理。
而在下次加载的时候,程序会被以对二进制码流,按照解码的编码处理原则处理。也就是说Python解释到ss=s.encode('UTF-8')行的时候,会对相应的二进制码流以utf-8的方式解码,这样就能很好的解决掉字符集不匹配的问题了。
二进制码流(python中,所有字符串都表示的是相应的二进制码流,所有的unicode都表示的是相应的内码)
Python中字符串和Unicode的区别
字符串表示的是编码后的二进制码流,unicode表示的是内码。所以,为了避免解码错误的出现,最好使用unicode表示
unicode的定义,使用
•s=u'郭':定义unicode字符串s。s表示的是哈的unicode内码
•ss=unicode(s,'gbk'):对字符串s按照gbk方式解码,ss表示解码后的内码
•import codecs
f=codecs.open(filename,'r','gbk‘)
s=f.read()
按照gbk方式读取filename,读取后的内容转变成unicode内码存在变量s中。
了解了以上编码解码的底层原理之后,基本上就可以应对相关的乱码问题了。
-----------------------------------------------------
PHP中的编码
在PHP中我们也经常会遇到页面出现乱码的情况,有了上面的知识基础,我们再过来看PHP中的乱码问题,就会迎刃而解了。当然了,今天主要是来讲一讲如何解决PHP中文乱码问题。
header
header("Content-Type:text/html;charset=utf-8");
加上头信息的作用就是告诉浏览器,以XX方式来解码。基本上而言不会有太大的问题,但是前提是双方的系统编码能保持一致,否则也会出现由于系统编码不同而引起的乱码问题,对照Python的案例,我们也很容易可以理解。
set names XX
mysql_query("set names UTF-8");
这个是对数据库数据乱码的很好的解决办法。说白了这就是所谓的“系统编码不同而引起的乱码问题的一类”。就拿MySQL数据库而言,我们是以客户端的形式来访问的数据,如果MySQL客户端的编码为gbk,而我们的浏览器解码使用的是UTF-8,请问怎么可能不会乱码呢?
只要保持双方的编码,解码方式一致,乱码问题,不攻自破。
-------------------------------------------------------
数据库中的编码
通过刚才的学习,类比系统编码和文件编码。我们经常遇到的数据库信息存取出现乱码问题就可以很容易的解决了。
修改字符集设置即可。但是这不是一个好习惯,比较好的做法是修改读取出来的数据的编码。
以MySQL为例。
可以先输入查询语句SHOW VARIABLES LIKE ‘character_set_%';,查看所有的编码是否是UTF-8.
如果不是可以使用Server Instance Config 把默认的字符集设置为utf-8或者修改/MySQL/MySQL Server 5.0/my.ini中的default-character-set=gbk
character-set-server=gbk;
然后重新启动mysql的服务就行了
JSP乱码
在开发JavaWeb的时候,遇到JSP乱码的情况有很多,下面着重的来探讨一下解决方案呢。
JSP页面本身
每个页面上加上 这样在jsp页面里,点右键,查看编码方式则为UTF-8.
<%@page pageEncoding="UTF-8" contentType="text/html; charset=UTF-8" %>
也可以把设置myEclipse中默认的contentTyepe。步骤是:windows->preferences->Generl->ContentType.然后设置成UTF-8.一定要update~~
在JSP页面头部加入下面这句话,告诉浏览器应该调用UTF-8的字符集。
或者使用HTML标签来声明
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
数据库连接语句
•设置characterencoding为UTF-8 如jdbc.mysql.url=jdbc:mysql://localhost:3306/db?useUnicode=true&characterEncoding=UTF8
•如果使用Hibernate,那就把所有的配置文件头部的编码格式改成UTF-8。
Tomcat方面
为了保证get/post数据都采用相同的UTF8编码,我们在server.xml中进行了如下设置:
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000"redirectPort="8443" URIEncoding="UTF-8" />
过滤器Filter
有些时候,使用过滤器可以一劳永逸的解决乱码问题,原理就是强化了通信双方的编码一致性。
//在doFilter方法中添加这样的代码
HttpServletRequest request = (HttpServletRequest )req;
HttpServletResponse response = (HttpServletResponse )resp;
request.setCharacterEncoding("UTF-8");
response.setHeader("Content-Type:text/htmlcharset=UTF-8");
response.setCharacterEncoding("UTF-8");
//放行
chain.doFilter(request,response);
总结
回顾一下,解决乱码问题的核心就是保证编码与解码工作的一致性。无论是系统编码还是文件编码,保证编码工作和解码工作的反向一致性,基本上就不会出现乱码问题。
如果你发现文章中有不恰当的地方,欢迎批评指正。
以上这篇浅谈编码,解码,乱码的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
最后
以上就是尊敬冬天最近收集整理的关于浅谈编码,解码,乱码的问题的全部内容,更多相关浅谈编码,解码,乱码内容请搜索靠谱客的其他文章。








发表评论 取消回复