简介
Beats 有多种类型,可以根据实际应用需要选择合适的类型。
常用的类型有:
- Packetbeat:网络数据包分析器,提供有关您的应用程序服务器之间交换的事务的信息。
- Filebeat:从您的服务器发送日志文件。
- Metricbeat:是一个服务器监视代理程序,它定期从服务器上运行的操作系统和服务收集指标。
- Winlogbeat:提供Windows事件日志。
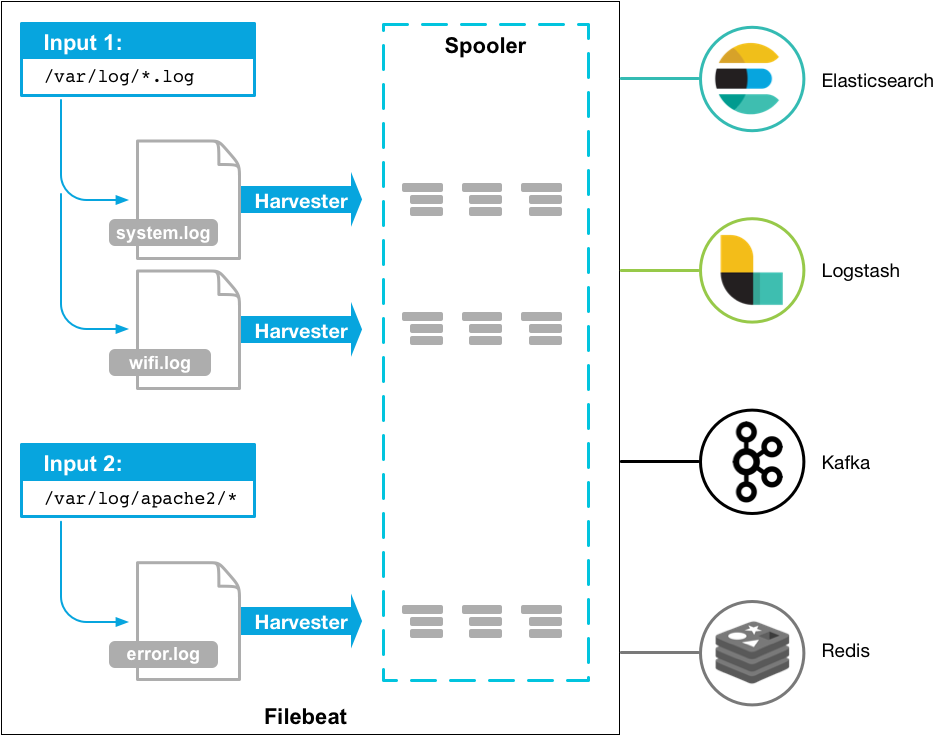
Filebeat 有两个主要组件:
harvester:负责读取一个文件的内容。它会逐行读取文件内容,并将内容发送到输出目的地。
prospector:负责管理 harvester 并找到所有需要读取的文件源。比如类型是日志,prospector 就会遍历制定路径下的所有匹配要求的文件。
安装filebeat 到目标机器
下载地址
https://www.elastic.co/cn/downloads/beats/filebeat
本测试使用windows环境安装filebeat
win:
下载win版本并解压,可以把它设置为系统服务
PS > cd ‘C:Program FilesFilebeat’
PS C:Program FilesFilebeat> .install-service-filebeat.ps1
Centos
解压:tar -zxvf filebeat-7.3.0-linux-x86_64.tar.gz
创建软链接:ln -s filebeat-7.3.0-linux-x86_64 filebeat
配置filebeat
由于6.0之后的版本,不再支持 document_type 这个选项了
Starting with Logstash 6.0, the document_type option is deprecated due to the removal of types in Logstash 6.0. It will be removed in the next major version of Logstash. If you are running Logstash 6.0 or later, you do not need to set document_type in your configuration because Logstash sets the type to doc by default.
所以为了lostash能区分不同目录发过来的日志,我们使用 tags属性
修改filebeat的配置文件 filebeat.yml
修改为如下配置,开启2个prospectors,收集2个目录下的日志,同样支持这样的写法:/var/log//.log
filebeat.prospectors配置多个目录文件监测输入源
filebeat.inputs:
- type: log
# Change to true to enable this prospector configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- d:nginxlog*.log
tags: ["naginx"]
- type: log
enabled: true
paths:
- d:javacmslog*.log
tags: ["cms"]
# ----------------output.kibana-------------------------
setup.kibana:
host: "localhost:5601"
# ----------------output.elasticsearch-------------------------
output.elasticsearch:
hosts: ["localhost:9200"]
protocol: "http"
index: "stat_filebeat"
# template.name: "stat_ilebeat"
# template.path: "filebeat.template.json"
# template.overwrite: false
#----------------output.logstash-----------------------------
output.logstash:
hosts: ["localhost:5044"]
#---------------output.kafka----------------------------------
output.kafka:
enabled: true
hosts: ["192.168.10.1:9092","192.168.10.2:9092","192.168.10.3:9092"]
topic: "liuzc_test"
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
上面监测两个文件源目类,并分别设置为了不同的tag名称,方便在后续的节点处理时根据不同的tag做不同的处理。
文件源数据输出方式有多种,es,logstash,Kibana等等其他数据中间件
主要配置参数
paths:指定要监控的日志,目前按照Go语言的glob函数处理。没有对配置目录做递归处理,比如配置的如果是:
encoding:指定被监控的文件的编码类型,使用plain和utf-8都是可以处理中文日志的。
input_type:指定文件的输入类型log(默认)或者stdin。 exclude_lines:在输入中排除符合正则表达式列表的那些行。
include_lines:包含输入中符合正则表达式列表的那些行(默认包含所有行),include_lines执行完毕之后会执行exclude_lines。
exclude_files:忽略掉符合正则表达式列表的文件(默认为每一个符合paths定义的文件都创建一个harvester)。
fields:向输出的每一条日志添加额外的信息,比如“level:debug”,方便后续对日志进行分组统计。默认情况下,会在输出信息的fields子目录下以指定的新增fields建立子目录,例如fields.level。
multiline:适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈。这个配置的下面包含如下配置
启动
这里以写入logstash为例
beats配置filebeat.yml
paths:
#- /var/log/*.log
- D:mntmin-toolnginx-1.16.0logsaccess.log
tags: ["log1"]
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
logstash配置
logstash监听filebeat的配置文件(只是输出监听到的数据到控制台,不写入别的组件)
input {
beats {
port => 5044
}
}
output {
stdout{codec=>"rubydebug"}
}
beats指定配置文件启动
./filebeat run -e -c filebeat.yml -d "publish"
./filebeat -e -c filebeat.yml -d "publish" # run 可以省略
启动logstash可以看到有数据打印到控制台则说明配置成功。
参考文档
Filebeat的高级配置-Filebeat部分
https://blog.csdn.net/liukuan73/article/details/52330600
最后
以上就是俊逸星月最近收集整理的关于Filebeat7.x安装和使用的全部内容,更多相关Filebeat7内容请搜索靠谱客的其他文章。








发表评论 取消回复