
作者:Jose A Dianes
翻译:季洋
校对:丁楠雅
本文约5822字,建议阅读20+分钟。
本系列将介绍如何在现在工作中用两种最流行的开源平台玩转数据科学。先来看一看数据分析过程中的关键步骤 – 探索性数据分析。
内容简介
本系列将介绍如何在现在工作中用两种最流行的开源平台玩转数据科学。本文先来看一看数据分析过程中的关键步骤 – 探索性数据分析(Exploratory Data Analysis,EDA)。
探索性数据分析发生在数据收集和数据清理之后,而在数据建模和分析结果可视化展现之前。然而,这是一个可反复的过程。做完某种EDA后,我们可以尝试建立一些数据模型或者生成一些可视化结果。同时,根据最新的分析结果我们又可以进行进一步的EDA,等等。所有的这些都是为了更快地找到线索,而不用纠结在数据细节和美观上。EDA的主要目的是为了了解我们的数据,了解它的趋势和质量,同时也是为了检查我们的假设甚至开始构建我们的假设算法。
了解了以上内容,我们将解释如何用描述统计学、基本绘图和数据框来回答一些问题,同时指导我们做进一步的数据分析。
这系列教程的所有代码和应用程序可以从GitHub(https://github.com/jadianes/data-science-your-way)中得到。你可以随意参与并同我们分享你的进度。
准备数据
我们将继续使用在介绍数据框时已经装载过的相同的数据集。因此你可以接着数据框相关教程继续这个章节,或者重新学习数据准备教程 (https://www.codementor.io/python/tutorial/python-vs-r-for-data-science-data-frames-i)。
我们要回答的问题
在任何的数据分析过程中,总有一个或多个问题是我们要回答的。定义这些问题,是整个数据分析过程中最基本也是最重要的一个步骤。因为我们要在我们的结核病数据集中做探索性数据分析,有一些问题需要我们回答:
哪些国家拥有最高传染性结核病发病率?
从1990年到2007年世界结核病的总体趋势是什么?
哪些国家没有符合这个趋势?
还有哪些关于这个疾病的真相可以从我们的数据中得到?
描述性统计
Python
在Python中,对一个pandas.DataFrame对象的基本的描述性统计方法是describe()。它等同于R语言中data.frame的summary()方法。

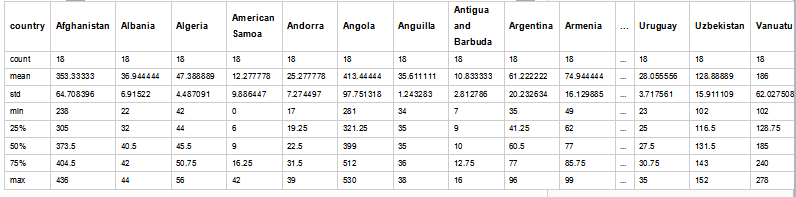
这里列出了所有列的统计信息,我们可以用以下方法来访问每个列的汇总信息:

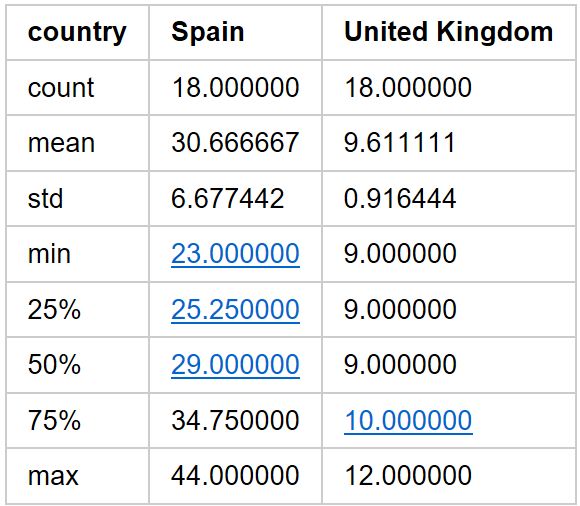
Pandas包中有多得可怕的描述性统计方法(可参照文档http://pandas.pydata.org/pandas-docs/stable/api.html#api-dataframe-stats)。其中一部分已经包含在了我们的summary对象中,但是还有更多的方法不在其中。在接下来的教程中我们将好好的利用它们来更好的了解我们的数据。
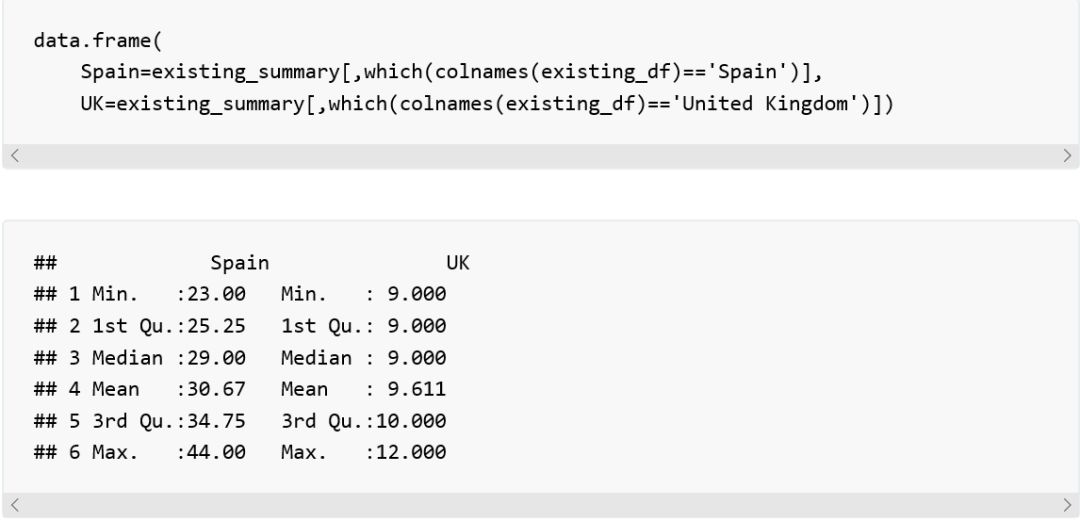
例如,我们可以得到西班牙(Spain)每年结核病发病量的变化百分比:

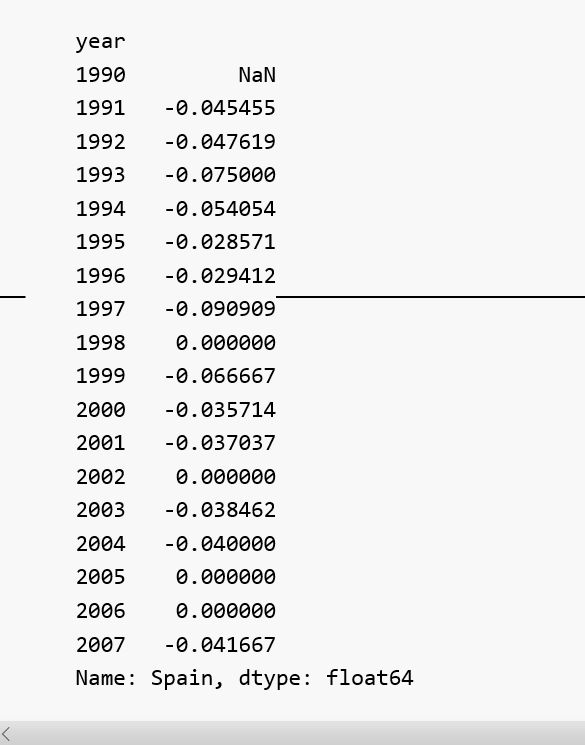
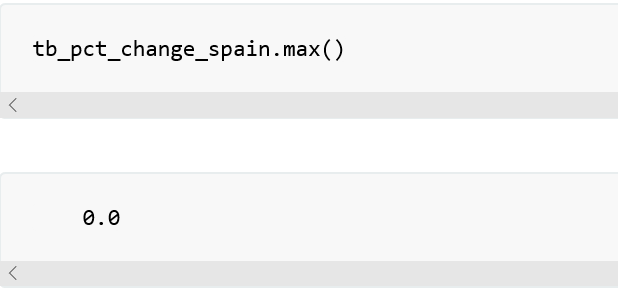
同时从以上结果得到最大值:
也可以对英国(United Kingdom)做同样的操作:
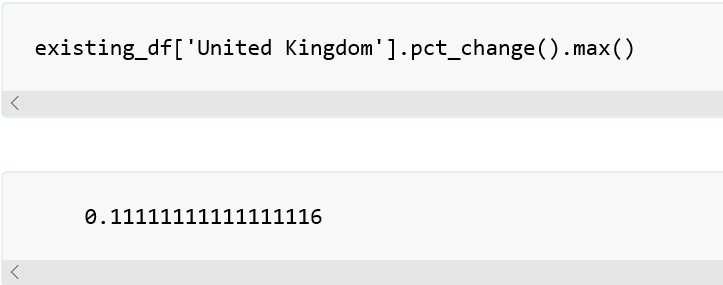
如果我们要了解索引值(year),我们用argmax 方法(或Pandas新版本中的idmax调用方法)如下:
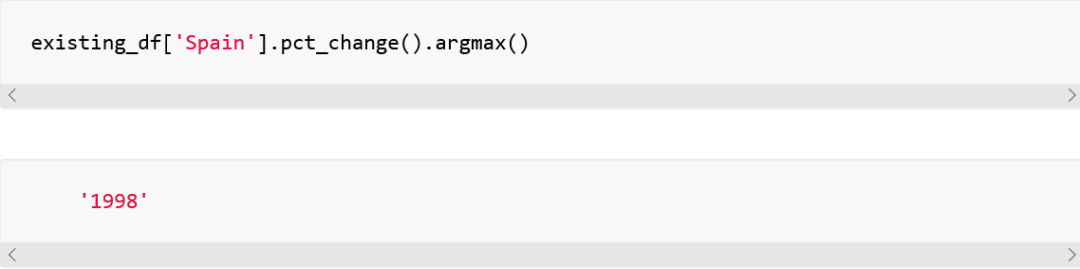
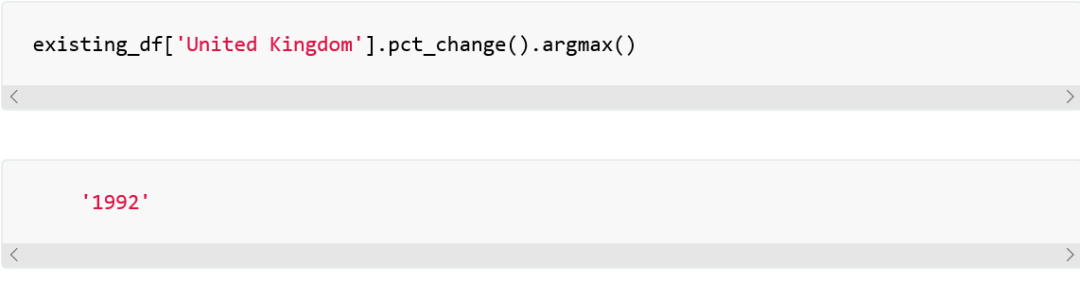
也就是说,1998年和1992年分别是西班牙和英国肺结核发病量增长最糟糕的年。
R
在R语言中基本的描述性统计方法,如我们说过的,是summary()。
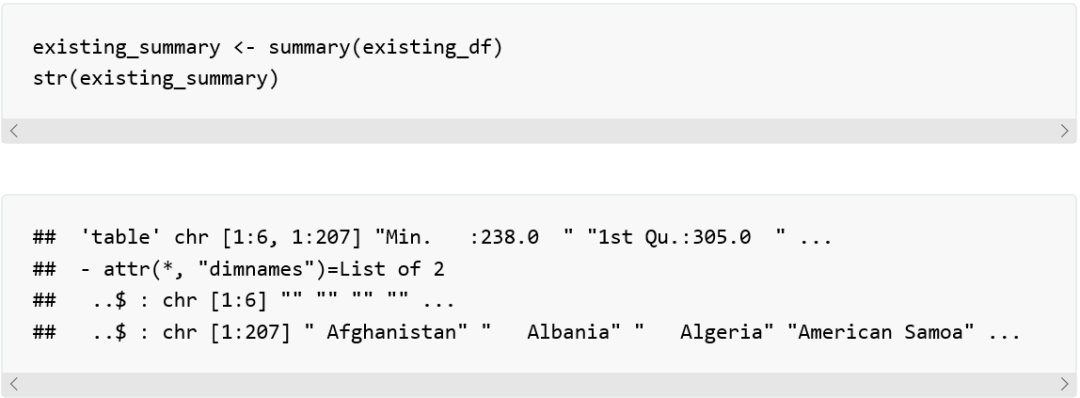
这个方法返回一个表格对象,使我们拥有了一个包含各列统计信息的数据框。表格对象有利于我们观察数据,但作为数据框却不利于我们访问和索引数据。基本上,我们是把它当作矩阵,通过坐标位来访问其中的数据。通过这种方法,如果我们要得到第一列,Afghanistan的相关数据,我们该这样做:
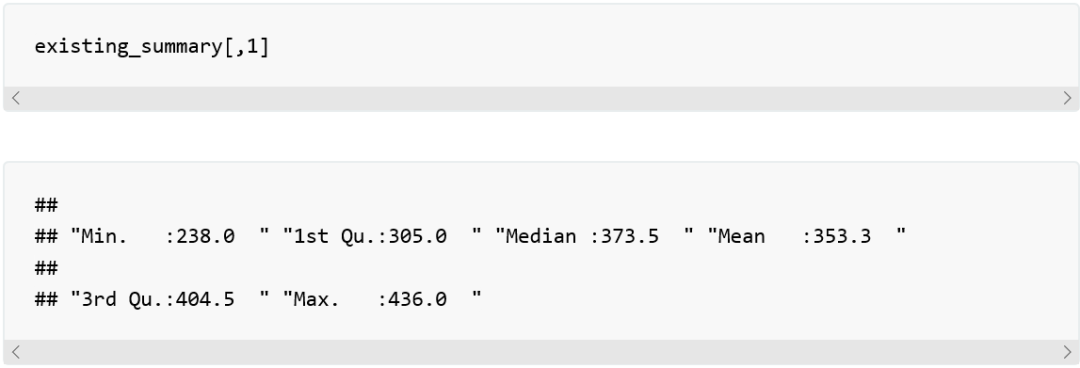
有个窍门可以通过列名访问数据,那就是将原始数据框中的列名和which()方法一起使用。我们还可以在结果集上构建一个新的数据框。
R做为一种函数式语言,我们可以对向量使用函数方法例如sum、 mean、 sd等等。记住一个数据框就是一个向量的列表(也就是说各个列都是一个值的向量),如此我们便可以很容易地用这些函数作用于列上。最终我们将这些函数和lapply或sapply一起使用并作用于数据框的多列数据上。
不管怎样,在R语言中有一家族的函数可以作用于列数据或行数据上以直接得到均值或和值。这样做比用apply函数更有效,并且还允许我们将他们不光用在列数据上,更可用在行数据上。例如,你输入‘?colSums’命令,帮助页面会弹出所有这些函数的描述性说明。
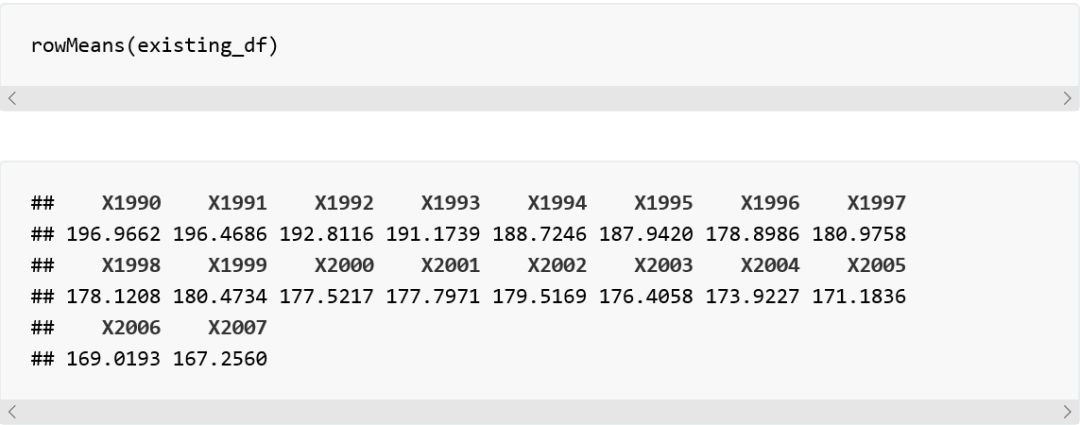
比如我们想得到每年的平均病发量,我们只需要一个简单的函数调用:
图表绘制
在这个章节中我们要看一看在Python/Pandas和R中的基本的绘图制表功能。然而,还有其它如ggplot2(http://ggplot2.org/)这样绘图功能更强大语言包可以选择。ggplot2最初是为R语言创建的,Yhat(https://yhathq.com/)的人又提供了它的Python语言的实现(http://ggplot.yhathq.com/)。
Python
Pandas包中DataFrame对象实现的即时可用的作图方法有3个之多(请参阅文档http://pandas.pydata.org/pandas-docs/stable/api.html#id11。)第一个方法是一个基本的线图绘制,作用于索引中的连续变量。当我们用IPython notebook工具绘图时,这第一条线也许我们会用得着:

或者我们可以用箱线图来得到给定连续变量的摘要视图:

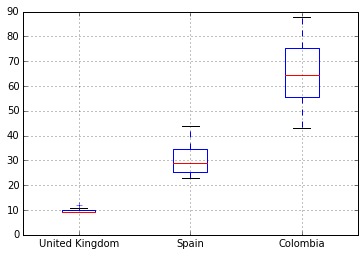
还有一个histogram()方法,但是我们现在还不能将它作用于我们这种类型的数据。
R
和ggplot2相比,R语言的基础绘图不是非常精密复杂,但它还是功能强大同时又操作便利的。它的很多数据类型都自定义并实现了plot()方法,可以允许我们简单地调用方法对它们进行绘图。然而并不总是如此便利,更多的情况是我们需要将正确的元素集传给我们的基础绘图函数。
正像之前用Python/Pandas绘制线型图,我们也从基础的线型图绘制开始:

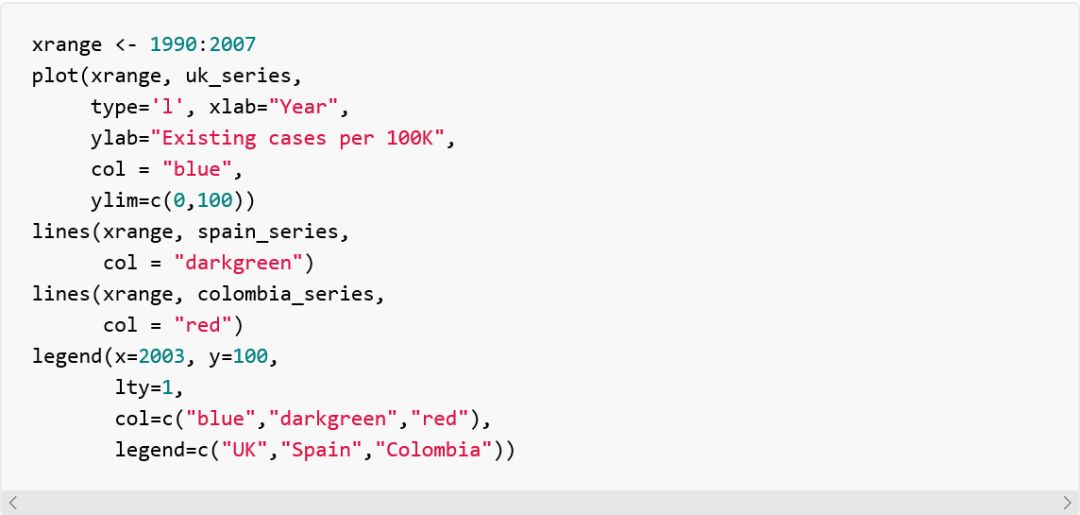
你可以比较出在Pandas中绘制三条连续变量线型图是多么容易,而用R的基础绘图绘制相同的图代码是多么冗长。我们至少需要三个函数调用,先是为了图形和线,然后还有图的标注,等等。R语言的基本绘图的真正用意就是绘制快速而不完善的图。
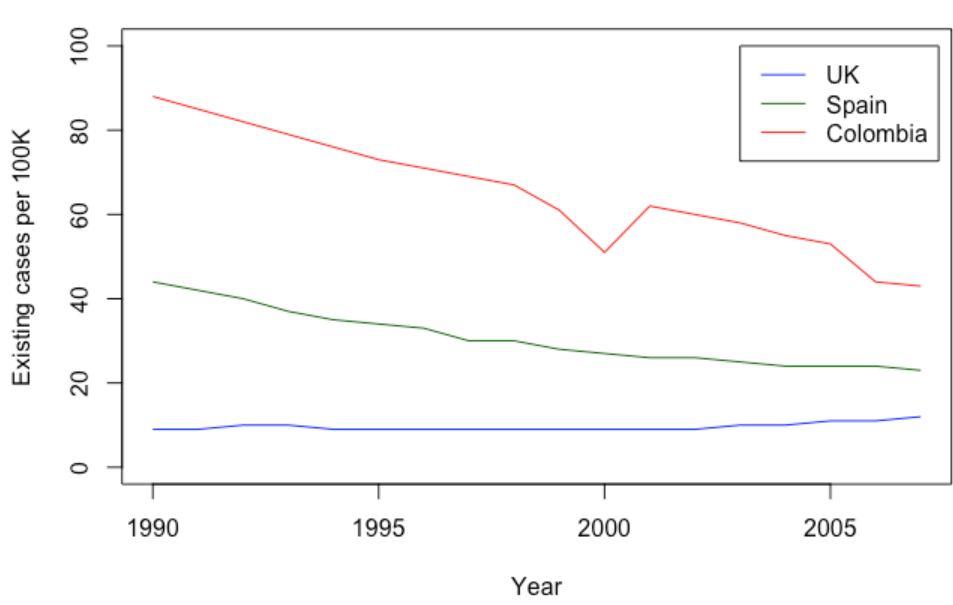
现在让我们来使用箱线图:

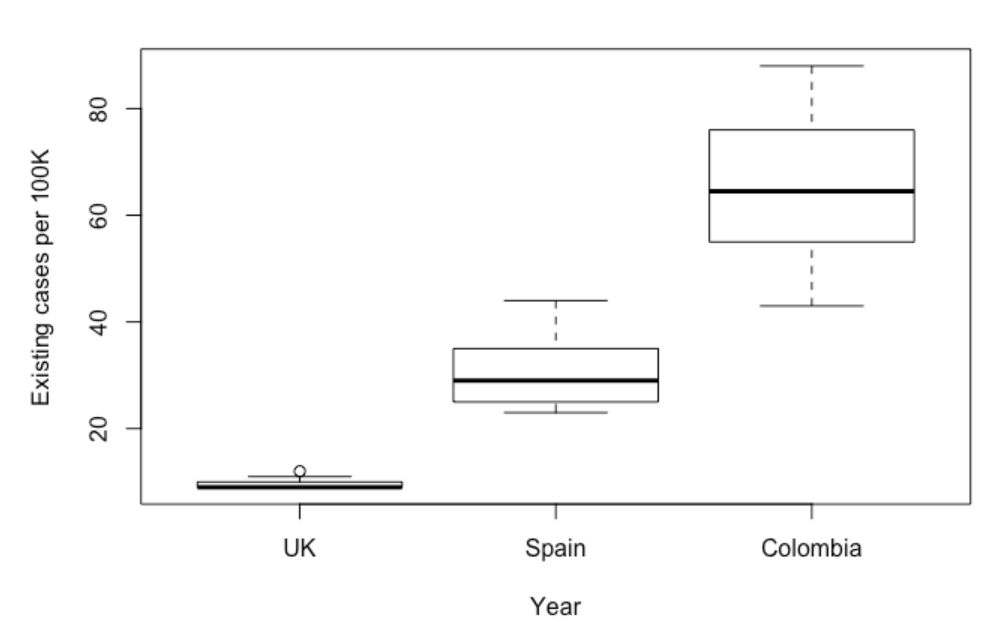
这是一段简短的箱线图代码,我们甚至没有要图的颜色和图例说明。
回答问题
现在让我们开始正真好玩的章节。一旦我们了解了我们的工具(从之前的数据框教程到当下这个教程),我们就可以用它们来回答关于传染性肺结核病在全球的发病率和盛行率的一些问题。
问题:我们想知道,每年,哪个国家存在的、新的传染性肺结核病例最多?
Python
如果我们只是想得到病例最多的国家,我们可以利用apply和argmax函数。记住,默认的,apply作用于列数据(在我们的例子里是国家列),而我们希望它作用于每一年。如此这样,我们需要在使用数据框之前颠倒它的行列位置,或传入参数axis=1。

但是这样做过分简单了。另外,我们要得到的是位于最后四分区的国家。而我们首先要做的是找出全球的总的发病趋势。
全球传染性肺结核发病趋势:
为了探索全球总趋势,我们需要对三个数据集中所有国家的每年的数据分别求和。

现在我们要创建一个新的数据框,里面包含各个之前得到的和集,然后用数据框的plot()方法进行绘图。


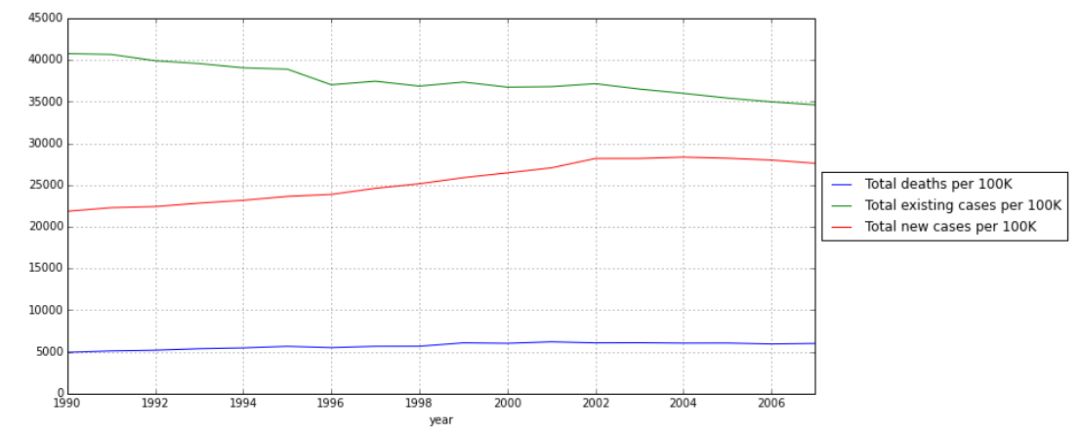
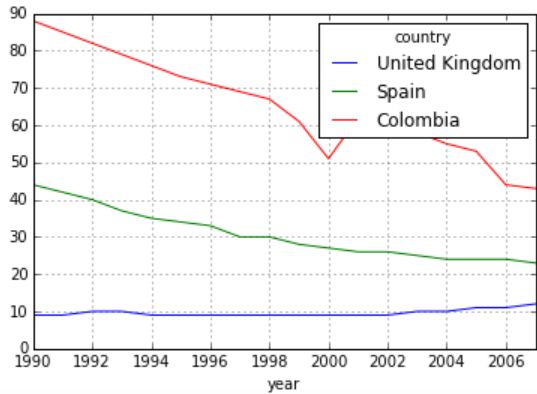
看上去全球每十万人中现存病例总数历年来呈整体下降趋势。然而新的病例总数呈上升趋势,虽然2005年后好像有所下降。所以怎么可能在新的病例总数增长的情况下现存病例总数下降呢?其中一个原因可能是我们可以在图中观察到的上升的每十万人的因病死亡人数,但是我们不得不考虑其主要原因是因为人们得到了治疗而恢复了健康。康复率加上死亡率大于新的病发率。总之,看上去新的发病率增加了,而同时我们治愈它们的水平也更好了。我们需要改进预防措施和传染病控制能力。
超出整体趋势的国家
所以之前是全球作为一个整体的总趋势。那么哪些国家呈现不同的趋势呢(更糟糕)?为了找出这些国家,首先我们需要了解每个国家平均年死亡率的分布情况。

我们可以画出这些分布图从而了解这些国家年平均分布情况。

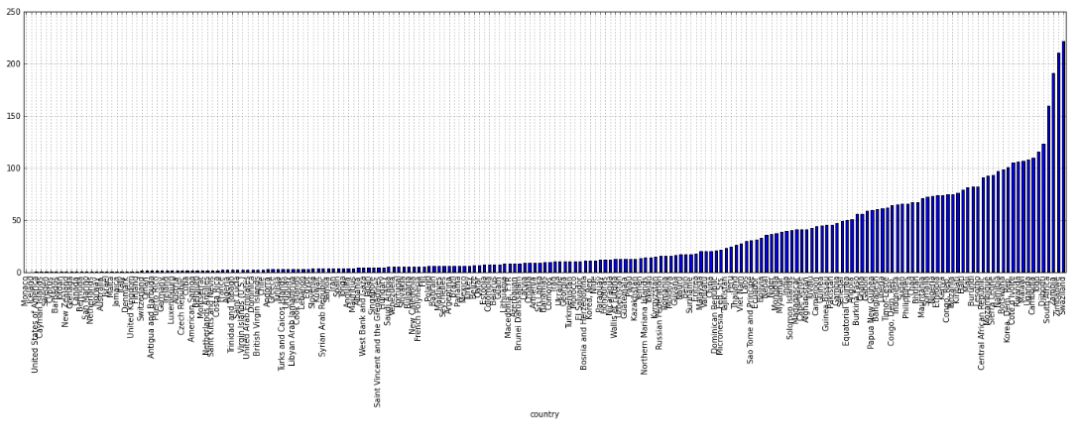
我们要得到那些概率大于四分位间距(IQR、50%)1.5倍的国家。
先得到上限值:

现在我们可以利用这些值来得到从1990年到2007年平均概率大于这些上限值的国家。

我们有多少比例的国家是超出整体趋势的?对于死亡率:


对于存在病率(患病率):


对于新病率(发生率):


现在我们可以用这些指标来对我们原始的数据框做筛选。

这是一个严肃的事情。根据传染性肺结核病的分布,我们有超过全球三分之一的国家在现存病率、新病率和死亡率上超出普遍概率。然而如果我们以四分位间距(IQR)的5倍为上限呢?让我们重复之前的过程。

那么现在的比例是多少呢?


让我们得到相应的数据框。

让我们把注意力放在传染病控制上,来看一看这个新的数据框:

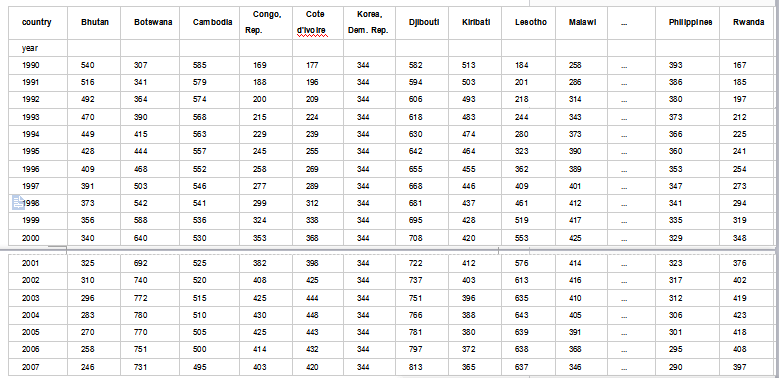
让我们生成一些图表来加深一下印象。

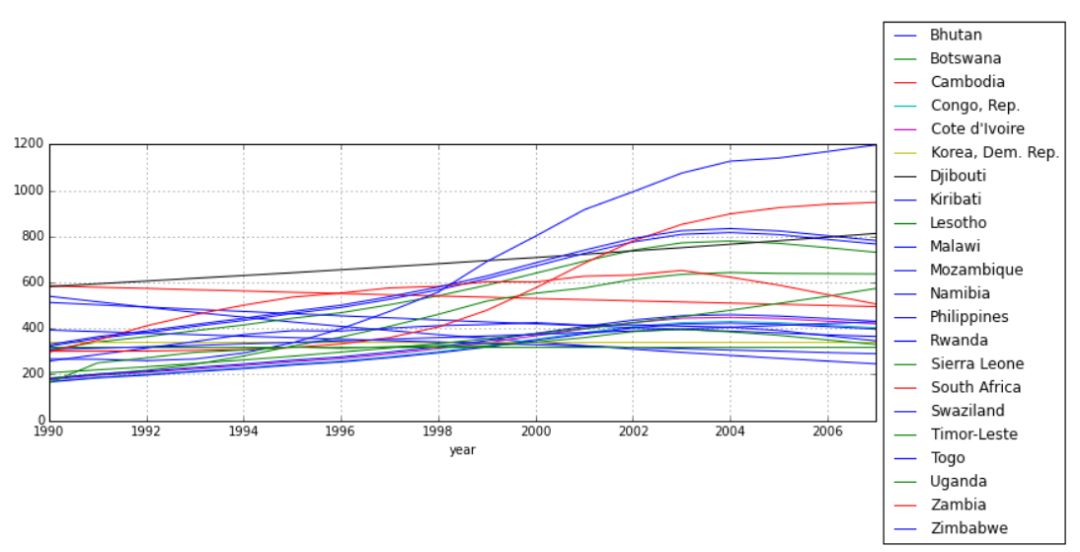
我们有了22个国家,在这些国家中新病的年平均率大于全球新病率中间值的5倍。让我们创建一个国家代表了这22个国家的平均值:

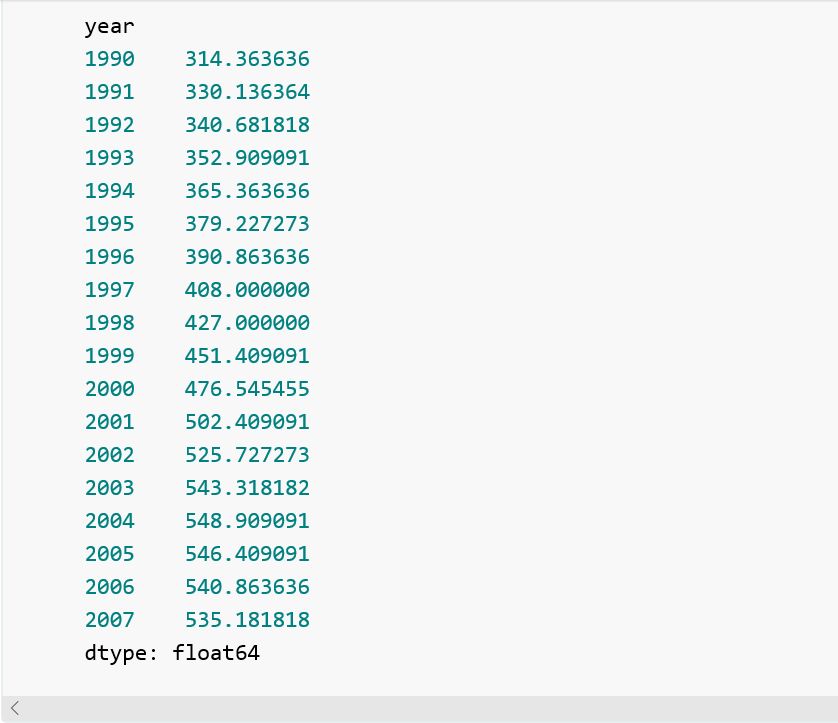
现在让我们再创建一个国家代表了其它国家的平均值:

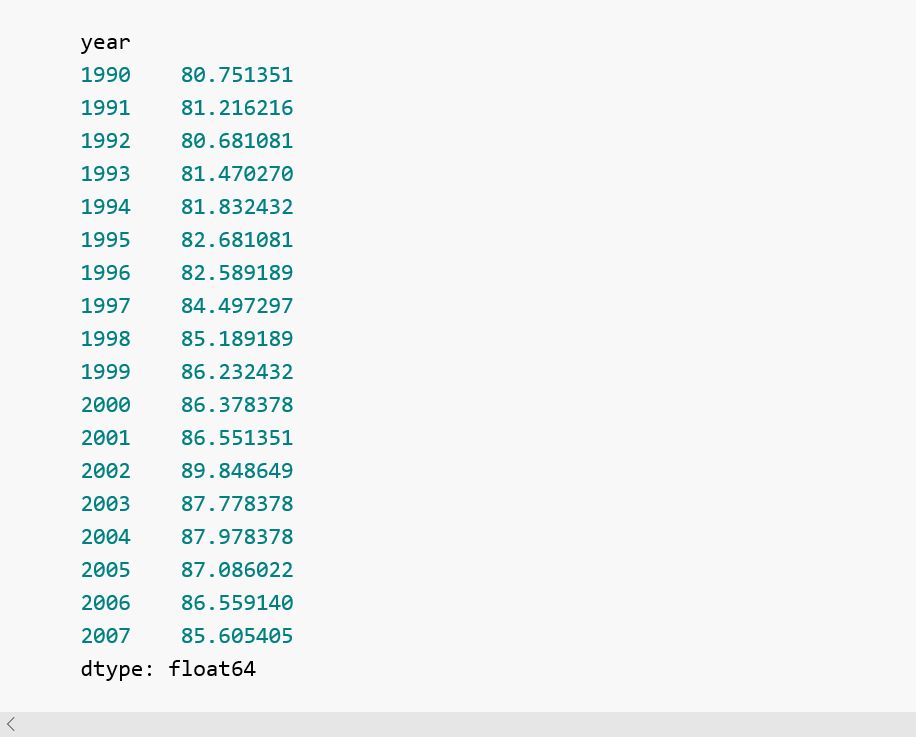
现在让我们用这两个平均国家绘图:
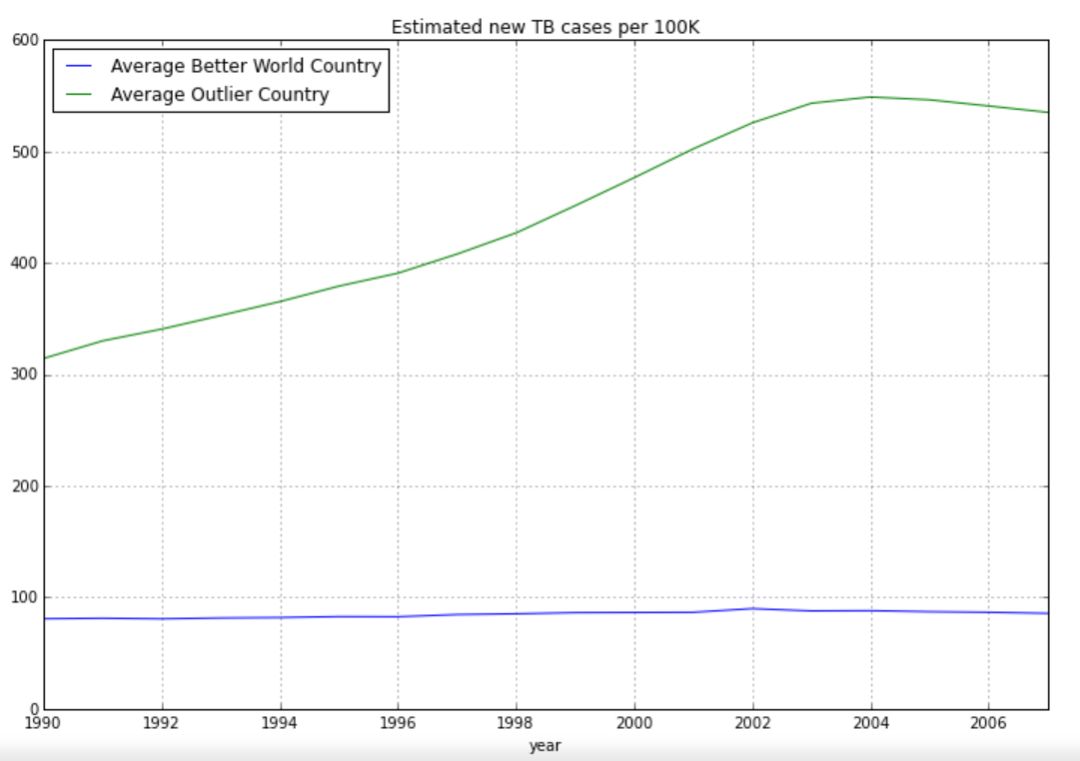
新病率的增长趋势在平均特超国家(超出上限的22个国家的平均值代表)上非常显著,这么显著的趋势很难在改善国家(22个国家之外的其它国家的平均值代表)中观察到。在90年代,这些国家的传染性肺结核病的发病数量有一个可怕的上涨。然而让我们看一下真实的数据。

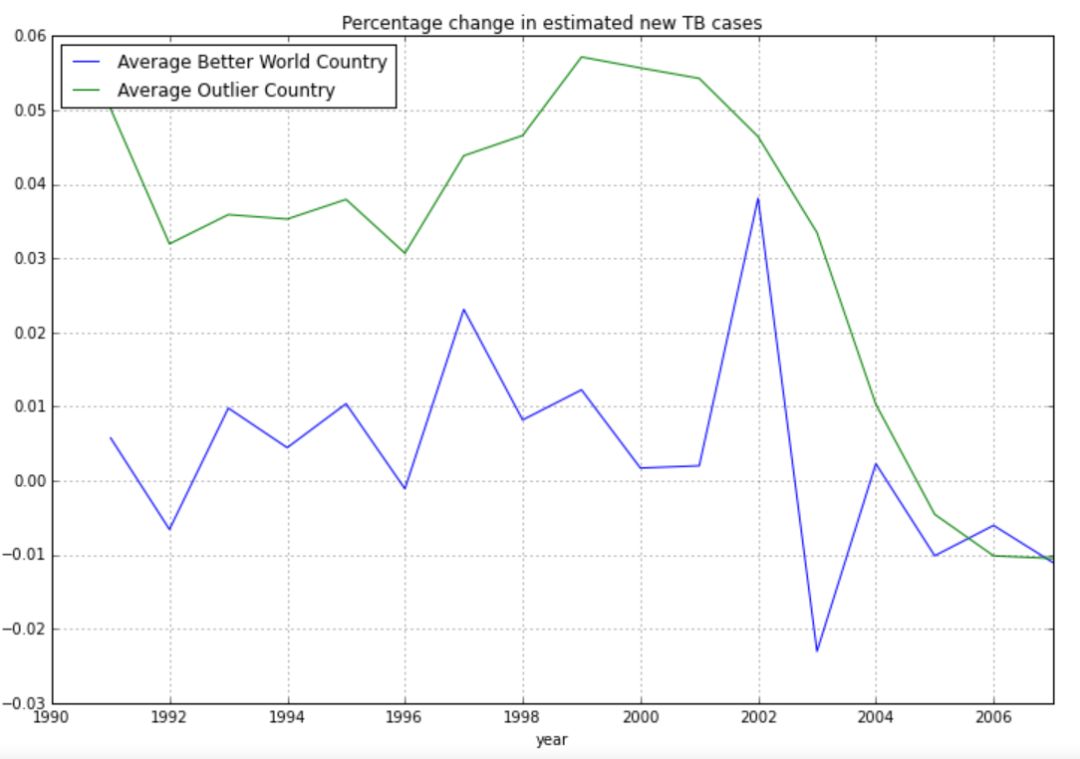
根据这张图,改善和异常国家的发病率增长趋势在同一时间发生了相同的波动和恢复,并且在大约2002年的时候有事情发生。在下一章节中我们将尝试找出到底发生了什么。
R
我们已经了解到在R中我们可以用max函数作用于数据框的列上以得到列的最大值。额外的,我们还可以用which.max来得到最大值的位置(等同于在Pandas中使用argmax)。如果我们使用行列换位的数据框,我们可以用函数lapply或sapply对每一个年列进行操作,然后得到一列表或一向量的指标值(我们将会用sapply函数返回一个向量)。我们只需要做一点微调,利用一个包含国家名的向量来使操作返回国家名而不是国家所在的位置。

全球传染性肺结核发病趋势:
再次,为了探索全球的总趋势,我们需要将三个数据集中的所有国家的数值按年相加。
但是首先我们需要加载另外两个数据集以得到死亡数量和新病数量。
以下截图数据下载链接不完整,分别为:https://docs.google.com/spreadsheets/d/12uWVH_IlmzJX_75bJ3IH5E-Gqx6-zfbDKNvZqYjUuso/pub?gid=0&output=CSV
https://docs.google.com/spreadsheets/d/1Pl51PcEGlO9Hp4Uh0x2_QM0xVb53p2UDBMPwcnSjFTk/pub?gid=0&output=csv
同时现在是按行求和。我们需要将返回的数字向量转化为数据框。

现在我们可以用目前我们已经学到的技巧来绘出各线图。为了得到一个包含各总数的向量以传给每个绘图函数,我们使用了以列名为索引的数据框。
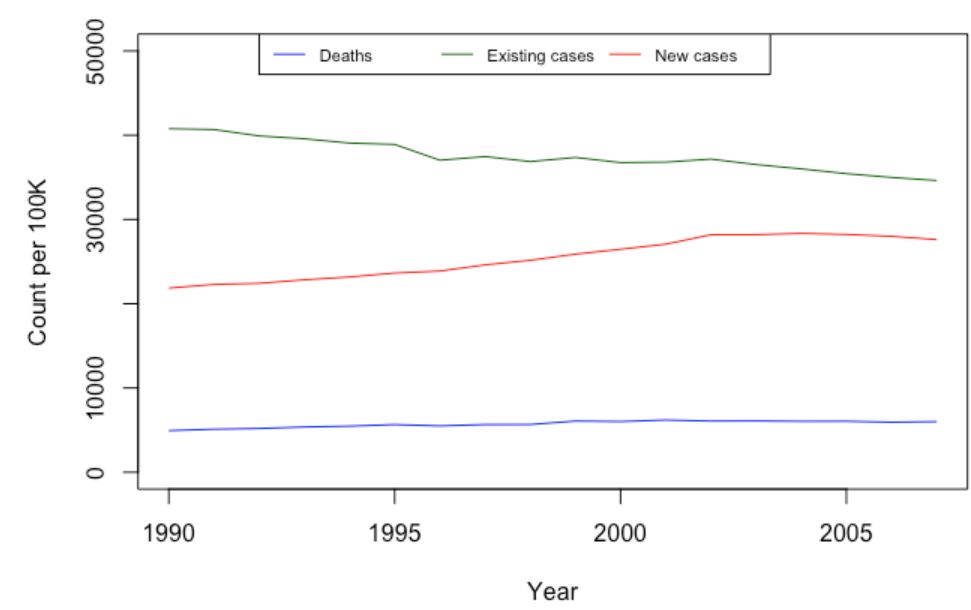
从上图中得到的结论显然和我们用Python时得到的相同。
超出整体趋势的国家:
所以哪些国家是超出整体趋势的呢(更糟糕)?再一次,为了找出答案,我们首先需要了解每个国家的年平均分布情况。我们用函数colMeans 以达到目的。

我们可以绘制出分布图以对各个国家的年平均值的分布情况有所了解。我们对单个国家不是非常感兴趣,我们感兴趣的是分布情况本身。

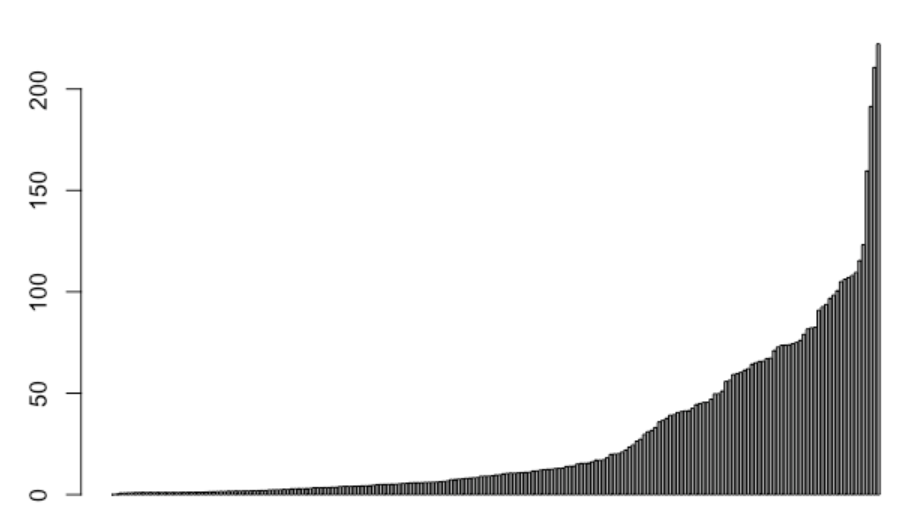
再一次我们可以在图上看到有三部分走势,开始部分缓慢地上升,接下来第二部分上升走势,最后一个尖起的峰值明显地不同于其它部分。
这次让我们跳过1.5倍的四分位间距部分,直接来到5倍四分位间距。在R语言中,我们要采用不同的方法。我们将使用函数quantile()来得到四分位间距从而判断离群值的临界值。
因为我们已经从Python章节中知道了结果,让我们只对新病率找出离群国家,如此一来我们要再次绘制之前的图。

离群比例:


让我们从中得到一个数据框,只包含离群的国家信息。

现在我们已经准备好了绘制图形。
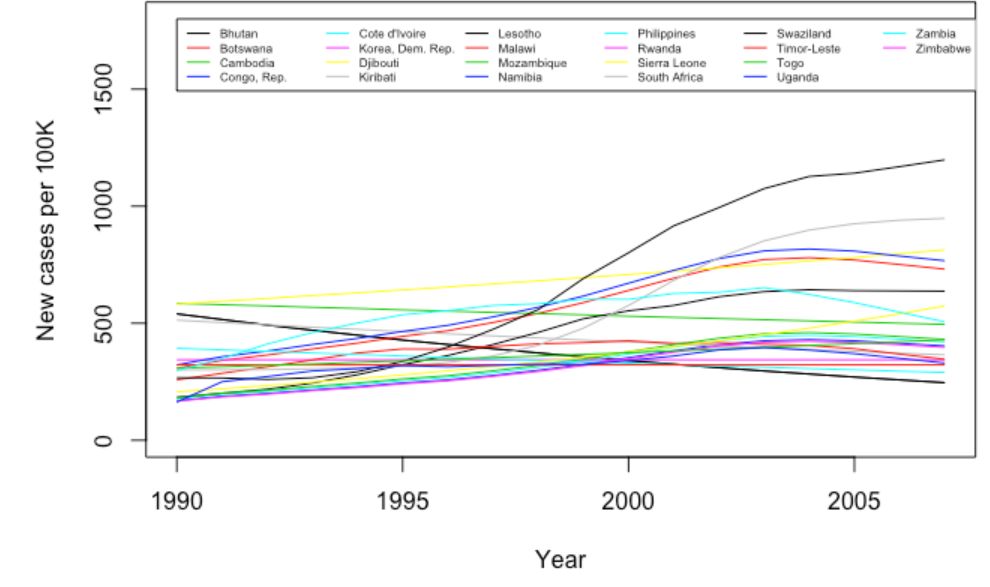
我们可以明显看到使用Pandas基本绘图与R基本绘图的优势!
到目前为止结果是相符的。我们有22个国家,平均每年的新病例数大于分布中值的5倍。让我们来创建一个国家代表这个平均值,在这里我们使用rowMeans()。

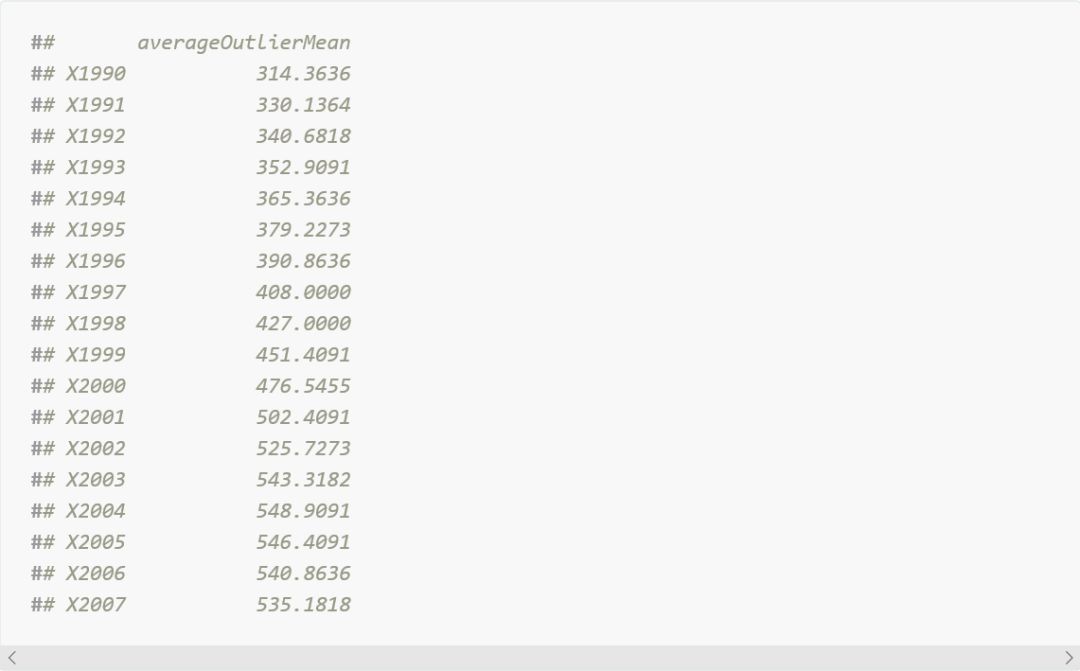
现在让我们创建一个国家代表其他国家。

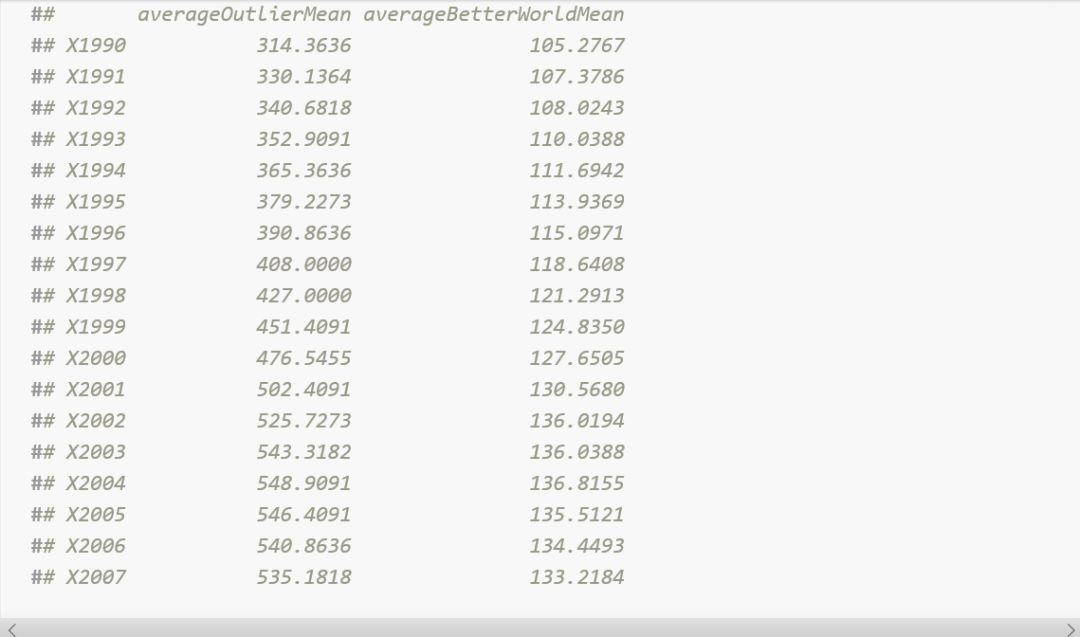
现在将这两个国家放在一起。

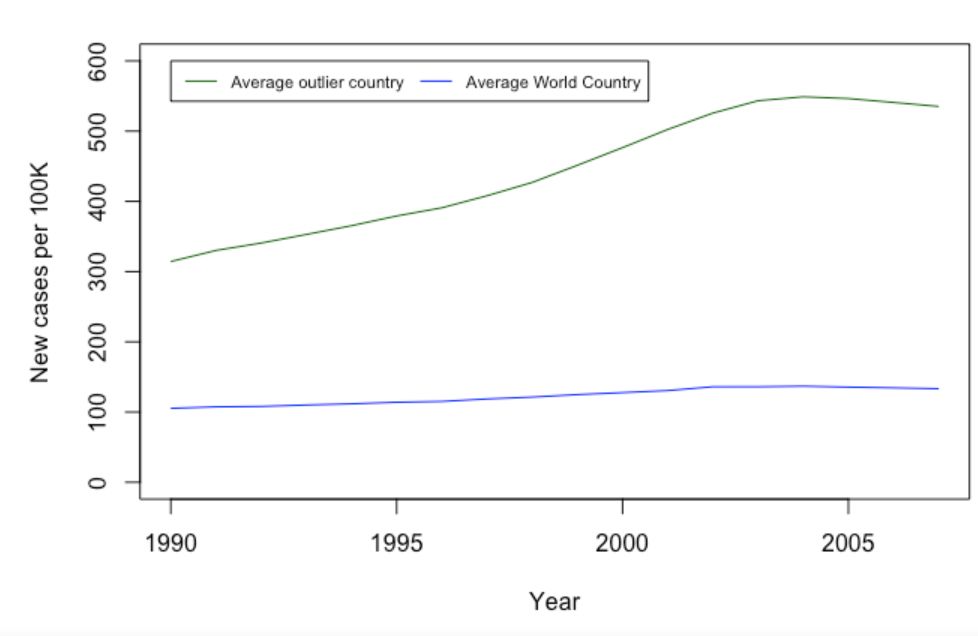
谷歌一下关于肺结核病的事件以及日期
在此章节中我们只用Python来分析。关于谷歌检索,其实我们只是直接访问维基百科关于这个疾病的目录(https://en.wikipedia.org/wiki/Tuberculosis#Epidemiology)。
在疫情章节我们可以找到如下内容:
肺结核病的发病总数从2005年开始下降,而新病发现量则从2002年开始就已经下降了。
这一点已经被我们之前的分析证实了。
中国取得了尤其显著的进展,从1990年到2010年,传染性肺结核病的死亡率下降了大约80%。让我们来看一下:

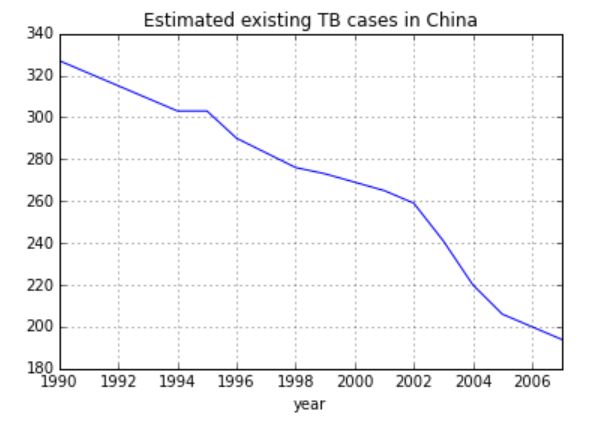
在2007年,预估传染性肺结核病的新病发生率最高的国家是斯威士兰,10万人中有1200起病例。


在维基百科中还有更多的发现是我们可以通过分析这些Google数据或其它Gapminder提供的数据来证实的。例如,传染性肺结核病和艾滋病经常被关联起来,同它们一起关联起来还有贫困水平。将它们相关的数据集关联起来,探索它们各自的变化趋势将会很有意思。读者们可以去试着分析一下并和我们分享你们的发现。
探索其它网页
除Gapminder网站之外的关于结核病其它有趣的资源:
盖茨基金会网站:
http://www.gatesfoundation.org/What-We-Do/Global-Health/Tuberculosis
http://www.gatesfoundation.org/Media-Center/Press-Releases/2007/09/New-Grants-to-Fight-Tuberculosis-Epidemic
总结
探索性数据分析是数据分析的一个关键步骤。在此阶段我们开始使接下来的工作逐渐成型。它发生于任一数据可视化或机器学习工作之前,向我们展示我们的数据或假设的好坏。
传统上,R语言是大多数探索性数据分析工作选择的武器,虽然使用其它的展示能力更佳的绘图程式库是相当方便的,如gglot2。事实上,当我们用Python时,Pandas中所包含的基本的绘图功能使这个步骤更加清晰和便捷。不管怎样,我们这里回答的这些问题都非常简单而且没有包含多变量和数据编码。在这种复杂的情况下,一个进阶的程式库如ggplot2将大放光彩。除了能给我们更漂亮的绘图之外,它的丰富的变现手法和重用性将大大地节省我们的时间。
尽管我们的分析和图表都如此简单,我们依然能够证明一个论点,那就是像肺结核这样的疾病引发的人道危机是多么严重,特别是考虑到这种疾病在更加发达的国家被相对更好地控制了。我们已经看到了一些编程技巧和大量的求知欲,从而允许我们在此之上建立一些认知和其它的全球化问题。
请记住这系列教程的所有代码和应用程序可以从GitHub(https://github.com/jadianes/data-science-your-way)中得到。
你可以随意参与并同我们分享你的进度!
原文标题:
Data Science with Python & R: Exploratory Data Analysis
原文链接:
https://www.codementor.io/jadianes/data-science-python-r-exploratory-data-analysis-visualization-du107jjms
译者简介

季洋,苏州某IT公司技术总监,从业20年,现在主要负责Java项目的方案和管理工作。对大数据、数据挖掘和分析项目跃跃欲试却苦于没有机会和数据。目前正在摸索和学习中,也报了一些线上课程,希望对数据建模的应用场景有进一步的了解。不能成为巨人,只希望可以站在巨人的肩膀上了解数据科学这个有趣的世界。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织
最后
以上就是单薄白开水最近收集整理的关于带你和Python与R一起玩转数据科学: 探索性数据分析(附代码)的全部内容,更多相关带你和Python与R一起玩转数据科学:内容请搜索靠谱客的其他文章。








发表评论 取消回复