补充第一篇生成向量部分:
正态分布函数rnorm();
泊松分布函数rpois();
指数分布函数rexp();
Gamma分布函数rgamma();
均匀分布函数runif();
二项分布函数rbinom();
几何分布函数rgeom();
四舍五入函数:round()
文章目录
- 1、生成一组数据框
- 2、简单分析数据
- 3、数据可视化
- 3.1 直方图
- 3.2 散点图
- 3.3柱状图
- 3.4 饼图
- 3.5 箱线图
- 3.6 星相图
- 3.7 茎叶图
- 3.8 qq图
1、生成一组数据框
首先,为了方便后面进行数据可视化,我们生成一组数据,在这里就100个同学数学分析、高等代数、概率统计三门课的成绩编一组数据,再通过一系列的可视化来分析。
> num=seq(1823079001,1823079100) #生成100个同学的学号
> num
[1] 1823079001 1823079002 1823079003 1823079004 1823079005 1823079006
[7] 1823079007 1823079008 1823079009 1823079010 1823079011 1823079012
[13] 1823079013 1823079014 1823079015 1823079016 1823079017 1823079018
[19] 1823079019 1823079020 1823079021 1823079022 1823079023 1823079024
[25] 1823079025 1823079026 1823079027 1823079028 1823079029 1823079030
[31] 1823079031 1823079032 1823079033 1823079034 1823079035 1823079036
[37] 1823079037 1823079038 1823079039 1823079040 1823079041 1823079042
[43] 1823079043 1823079044 1823079045 1823079046 1823079047 1823079048
[49] 1823079049 1823079050 1823079051 1823079052 1823079053 1823079054
[55] 1823079055 1823079056 1823079057 1823079058 1823079059 1823079060
[61] 1823079061 1823079062 1823079063 1823079064 1823079065 1823079066
[67] 1823079067 1823079068 1823079069 1823079070 1823079071 1823079072
[73] 1823079073 1823079074 1823079075 1823079076 1823079077 1823079078
[79] 1823079079 1823079080 1823079081 1823079082 1823079083 1823079084
[85] 1823079085 1823079086 1823079087 1823079088 1823079089 1823079090
[91] 1823079091 1823079092 1823079093 1823079094 1823079095 1823079096
[97] 1823079097 1823079098 1823079099 1823079100
> x1=round(runif(100,min=70,max=100)) #生成100位同学的数学分析成绩
> x1
[1] 94 75 78 76 78 90 74 87 80 75 76 90 73 74 93 74 97 79 98 71 72 91 70 81
[25] 95 71 71 88 79 93 94 79 97 81 75 71 92 89 71 78 92 75 71 84 86 85 79 73
[49] 80 88 94 84 79 99 81 99 80 78 83 77 97 86 75 93 94 86 90 80 75 83 74 86
[73] 82 93 92 74 74 73 94 99 86 71 99 80 88 94 74 96 95 82 89 96 99 73 74 86
[97] 72 93 96 83
> x2=round(rnorm(100,mean=80,sd=5)) #生成100位同学的高等代数成绩
> x2
[1] 84 82 77 89 69 80 88 79 77 85 77 84 78 80 78 85 79 76 72 86 85 85 87 88
[25] 82 79 82 82 87 85 82 86 84 79 78 83 82 75 84 77 88 76 81 79 80 89 94 85
[49] 81 76 83 74 86 81 75 77 83 81 79 92 94 81 78 84 73 81 78 75 89 76 84 90
[73] 82 80 77 82 84 83 81 83 88 84 74 77 74 83 72 75 76 82 76 78 81 77 84 74
[97] 71 85 82 80
> x3=round(rnorm(100,mean=85,sd=10)) #生成100位同学的概率统计成绩
> x3
[1] 78 83 75 105 84 81 84 98 72 80 99 70 114 96 84 106 93 84
[19] 77 100 92 91 90 92 78 89 82 74 80 90 90 78 85 81 91 91
[37] 92 88 73 107 79 75 75 84 86 92 93 86 82 71 83 89 77 87
[55] 66 71 63 74 95 87 91 78 72 95 88 103 102 93 89 77 91 75
[73] 83 83 86 86 90 82 65 91 102 92 102 96 90 74 83 102 80 92
[91] 83 77 80 70 85 85 89 72 96 90
> x3[which(x3>100)]=100 #由于正态分布最大值有超过100的,令超过100的取100
> x3
[1] 78 83 75 100 84 81 84 98 72 80 99 70 100 96 84 100 93 84
[19] 77 100 92 91 90 92 78 89 82 74 80 90 90 78 85 81 91 91
[37] 92 88 73 100 79 75 75 84 86 92 93 86 82 71 83 89 77 87
[55] 66 71 63 74 95 87 91 78 72 95 88 100 100 93 89 77 91 75
[73] 83 83 86 86 90 82 65 91 100 92 100 96 90 74 83 100 80 92
[91] 83 77 80 70 85 85 89 72 96 90
> x=data.frame(num,x1,x2,x3)
> x
num x1 x2 x3
1 1823079001 94 84 78
2 1823079002 75 82 83
3 1823079003 78 77 75
4 1823079004 76 89 100
5 1823079005 78 69 84
6 1823079006 90 80 81
7 1823079007 74 88 84
8 1823079008 87 79 98
9 1823079009 80 77 72
10 1823079010 75 85 80
11 1823079011 76 77 99
12 1823079012 90 84 70
13 1823079013 73 78 100
14 1823079014 74 80 96
15 1823079015 93 78 84
16 1823079016 74 85 100
17 1823079017 97 79 93
18 1823079018 79 76 84
19 1823079019 98 72 77
20 1823079020 71 86 100
21 1823079021 72 85 92
22 1823079022 91 85 91
23 1823079023 70 87 90
24 1823079024 81 88 92
25 1823079025 95 82 78
26 1823079026 71 79 89
27 1823079027 71 82 82
28 1823079028 88 82 74
29 1823079029 79 87 80
30 1823079030 93 85 90
31 1823079031 94 82 90
32 1823079032 79 86 78
33 1823079033 97 84 85
34 1823079034 81 79 81
35 1823079035 75 78 91
36 1823079036 71 83 91
37 1823079037 92 82 92
38 1823079038 89 75 88
39 1823079039 71 84 73
40 1823079040 78 77 100
41 1823079041 92 88 79
42 1823079042 75 76 75
43 1823079043 71 81 75
44 1823079044 84 79 84
45 1823079045 86 80 86
46 1823079046 85 89 92
47 1823079047 79 94 93
48 1823079048 73 85 86
49 1823079049 80 81 82
50 1823079050 88 76 71
51 1823079051 94 83 83
52 1823079052 84 74 89
53 1823079053 79 86 77
54 1823079054 99 81 87
55 1823079055 81 75 66
56 1823079056 99 77 71
57 1823079057 80 83 63
58 1823079058 78 81 74
59 1823079059 83 79 95
60 1823079060 77 92 87
61 1823079061 97 94 91
62 1823079062 86 81 78
63 1823079063 75 78 72
64 1823079064 93 84 95
65 1823079065 94 73 88
66 1823079066 86 81 100
67 1823079067 90 78 100
68 1823079068 80 75 93
69 1823079069 75 89 89
70 1823079070 83 76 77
71 1823079071 74 84 91
72 1823079072 86 90 75
73 1823079073 82 82 83
74 1823079074 93 80 83
75 1823079075 92 77 86
76 1823079076 74 82 86
77 1823079077 74 84 90
78 1823079078 73 83 82
79 1823079079 94 81 65
80 1823079080 99 83 91
81 1823079081 86 88 100
82 1823079082 71 84 92
83 1823079083 99 74 100
84 1823079084 80 77 96
85 1823079085 88 74 90
86 1823079086 94 83 74
87 1823079087 74 72 83
88 1823079088 96 75 100
89 1823079089 95 76 80
90 1823079090 82 82 92
91 1823079091 89 76 83
92 1823079092 96 78 77
93 1823079093 99 81 80
94 1823079094 73 77 70
95 1823079095 74 84 85
96 1823079096 86 74 85
97 1823079097 72 71 89
98 1823079098 93 85 72
99 1823079099 96 82 96
100 1823079100 83 80 90
> write.table(x,file="F:/R/score.txt",row.name=F,col.name=F,quote=F)
2、简单分析数据
round()函数为取整函数;
有了一组数据后,我们开始对其分析:
colMeans(x):对每一列求平均值
colMeans(x)[c(“x1”,“x2”,“x3”)]:对指定列求平均值
apply(x,2,mean):x为数据框,2表示对列操作,mean表示求平均值,即每列求平均值
apply(x,2,max):对每一列求最大值
apply(x,2,min):对每一列·求最小值
apply(x[c(“x1”,“x2”,“x3”)],1,sum):对每行求和,1表示在行上操作,即对每一位同学三门成绩求总分
which.max(apply(x[c(“x1”,“x2”,“x3”)],1,sum)):返回总分最高人的序号
x$num[which.max(apply(x[c(“x1”,“x2”,“x3”)],1,sum))]:返回成绩最高的人的学号
> colMeans(x)
num x1 x2 x3
1.823079e+09 8.363000e+01 8.105000e+01 8.529000e+01
> 8.363e+01
[1] 83.63
> colmeans(x)[c("x1","x2","x3")]
Error in colmeans(x) : 没有"colmeans"这个函数
> colMeans(x)[c("x1","x2","x3")]
x1 x2 x3
83.63 81.05 85.29
> apply(x,2,mean)
num x1 x2 x3
1.823079e+09 8.363000e+01 8.105000e+01 8.529000e+01
> apply(x,2,max)
num x1 x2 x3
1823079100 99 94 100
> apply(x,2,min) #x为数据框,2表示在列上进行操作,min表示取最小值。即每一列取最小值
num x1 x2 x3
1823079001 70 69 63
> apply(x[c("x1","x2","x3")],1,sum) #对每行求和,1表示在行上操作。即对每一位同学求总分
[1] 256 240 230 265 231 251 246 264 229 240 252 244 251 250 255 259 269 239
[19] 247 257 249 267 247 261 255 239 235 244 246 268 266 243 266 241 244 245
[37] 266 252 228 255 259 226 227 247 252 266 266 244 243 235 260 247 242 267
[55] 222 247 226 233 257 256 282 245 225 272 255 267 268 248 253 236 249 251
[73] 247 256 255 242 248 238 240 273 274 247 273 253 252 251 229 271 251 256
[91] 248 251 260 220 243 245 232 250 274 253
> which.max(apply(x[c("x1","x2","x3")],1,sum))
[1] 61
> x$num[which.max(apply(x[c("x1","x2","x3")],1,sum))]
[1] 1823079061
3、数据可视化
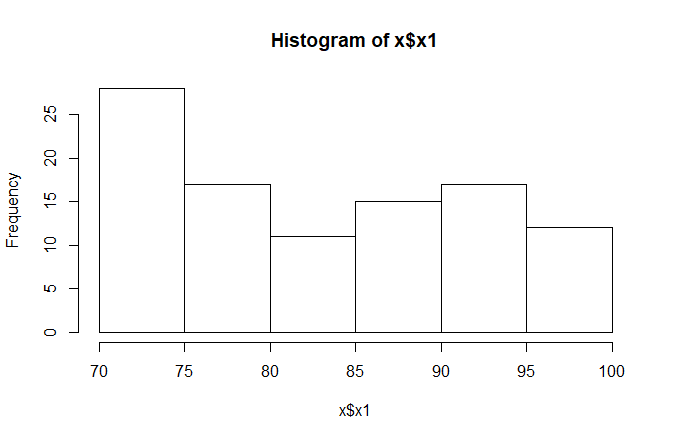
3.1 直方图
> hist(x$x1) #绘出x1的直方图
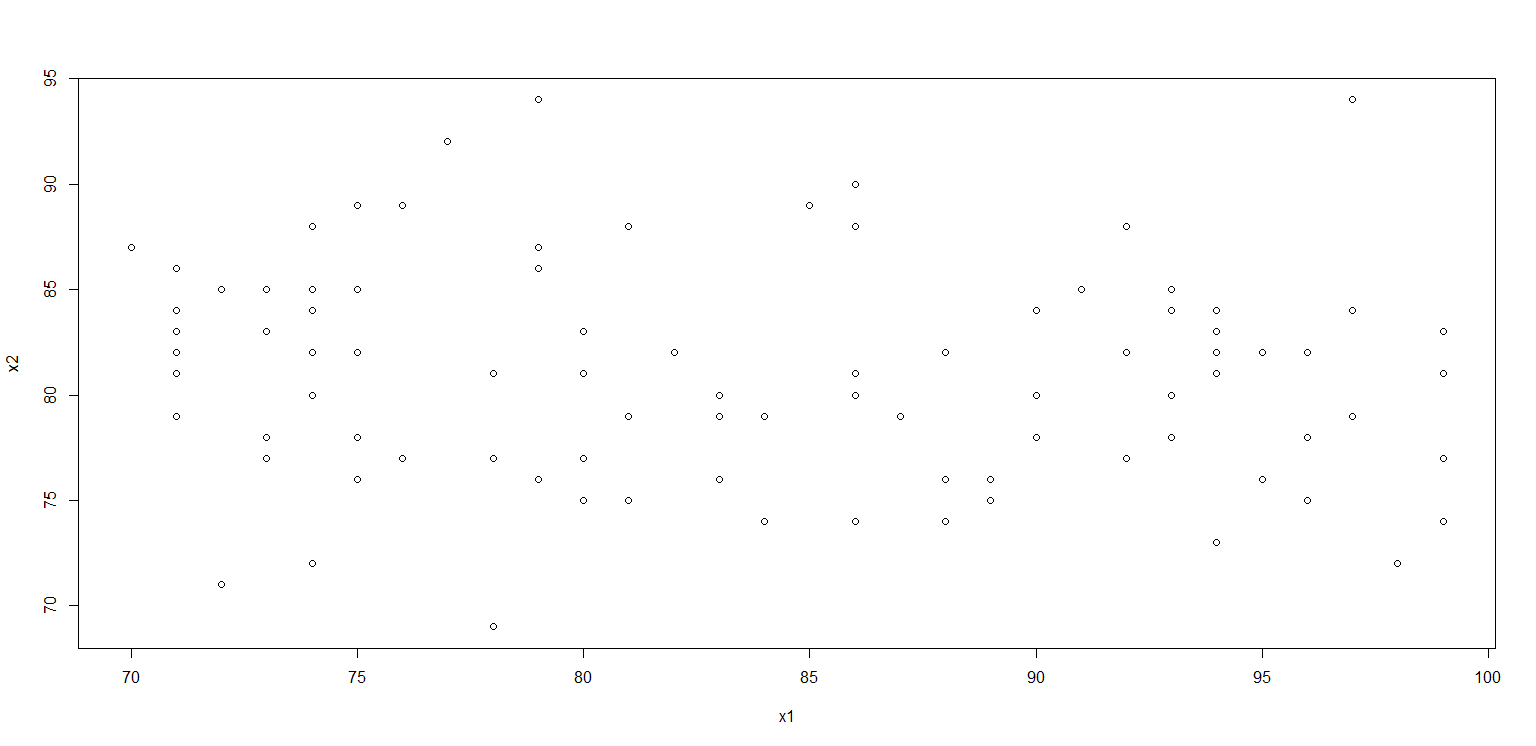
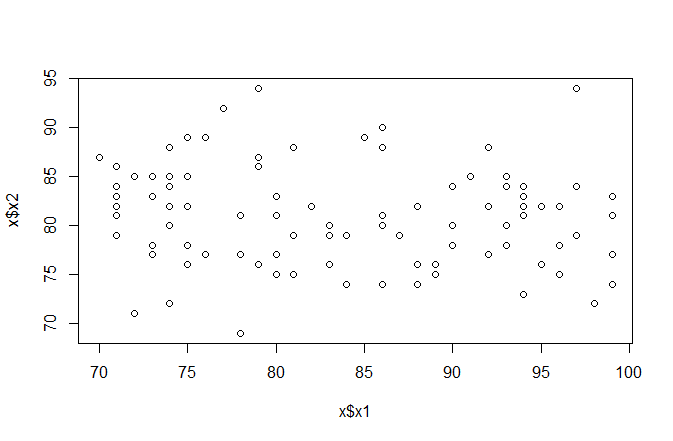
3.2 散点图
> plot(x1,x2)
> plot(x$x1,x$x2)
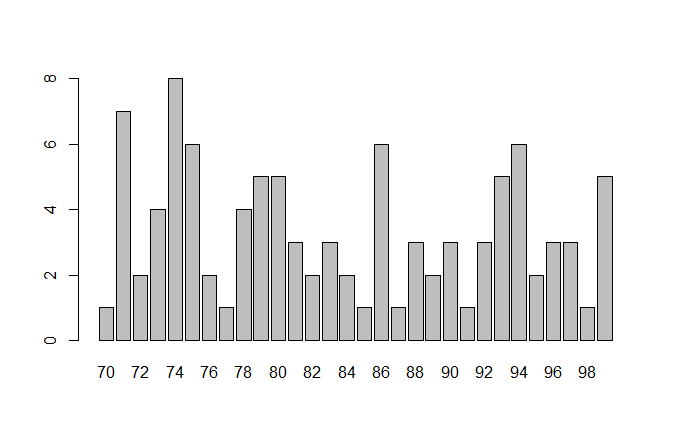
3.3柱状图
> table(x$x1) #统计各个分数有几个人
70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94
1 7 2 4 8 6 2 1 4 5 5 3 2 3 2 1 6 1 3 2 3 1 3 5 6
95 96 97 98 99
2 3 3 1 5
> barplot(table(x$x1))
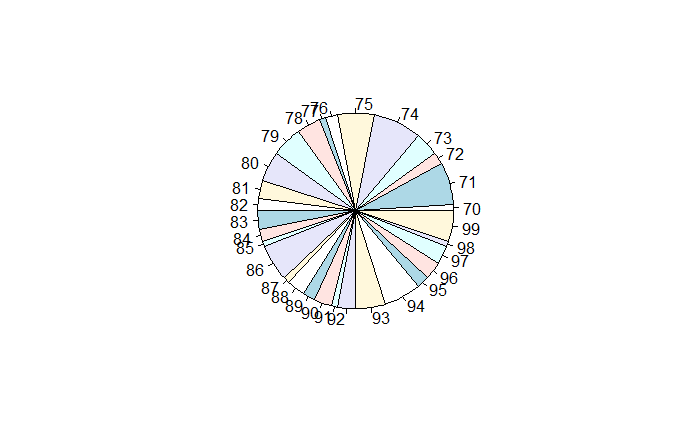
3.4 饼图
> pie(table(x$x1))
3.5 箱线图
> boxplot(x$x1,x$x2,x$x3)
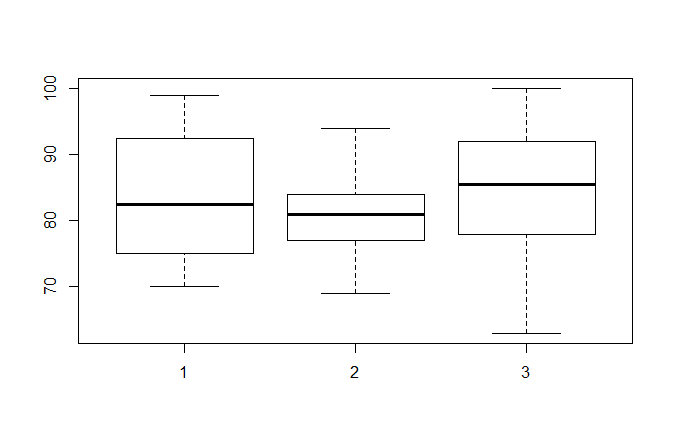
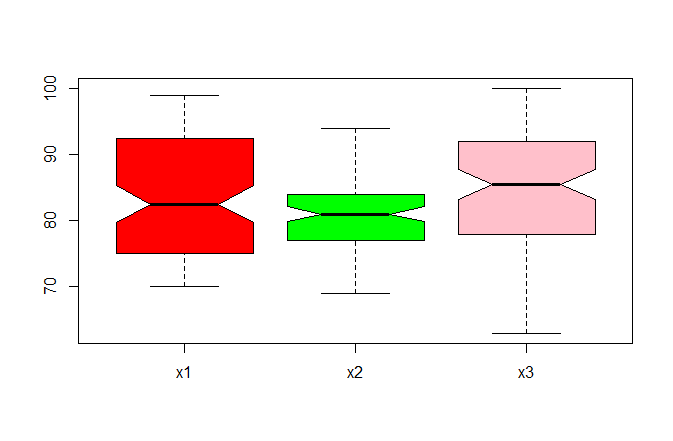
> boxplot(x[2:4],col=c("red","green","pink"),notch=T) #notch为缺口,突出中位线
> boxplot(x$x1,x$x2,x$x3,horizontal=T)
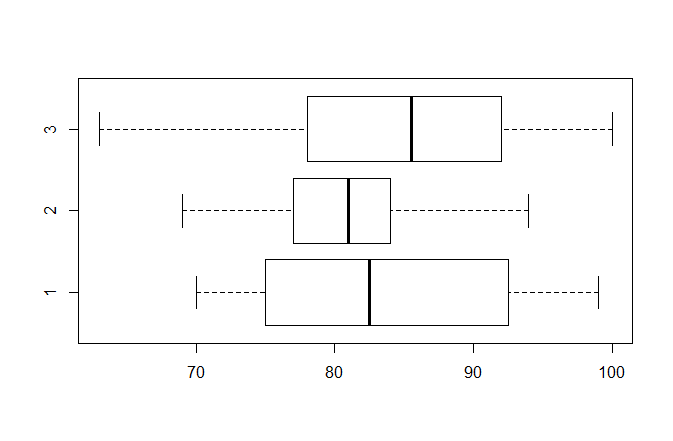
3.6 星相图
> stars(x[c("x1","x2","x3")]) #每一个样本的星相图,三角形里面的三条线分别代表三科成绩
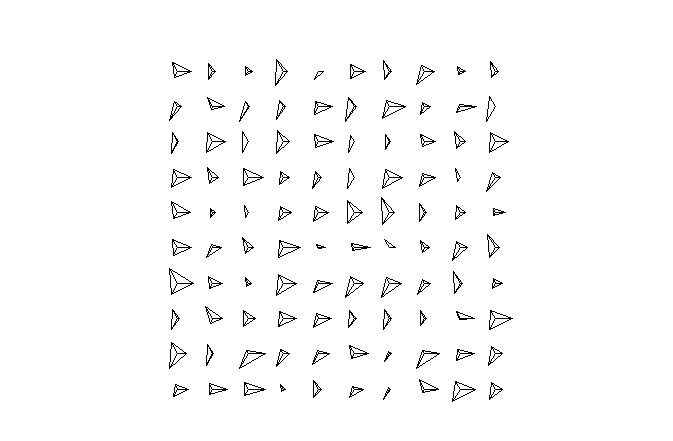
> stars(x[c("x1","x2","x3")],full=T,draw.segment=T) #扇形半径越小成绩越差;darw.segment控制是否画成扇形

> stars(x[c("x1","x2","x3")],full=F,draw.segment=T)

3.7 茎叶图
> stem(x$x1)
The decimal point is 1 digit(s) to the right of the |
7 | 0111111122333344444444
7 | 555555667888899999
8 | 000001112233344
8 | 5666666788899
9 | 000122233333444444
9 | 55666777899999
3.8 qq图
> qqnorm(x1) #判断x1是否为正态分布
> qqline(x1) #直线的斜率是标准差,截距是均值
Error in int_abline(a = a, b = b, h = h, v = v, untf = untf, ...) :
plot.new has not been called yet
> qqline(x2)
Error in int_abline(a = a, b = b, h = h, v = v, untf = untf, ...) :
plot.new has not been called yet
> qqnorm(x3)
> qqnorm(x2)
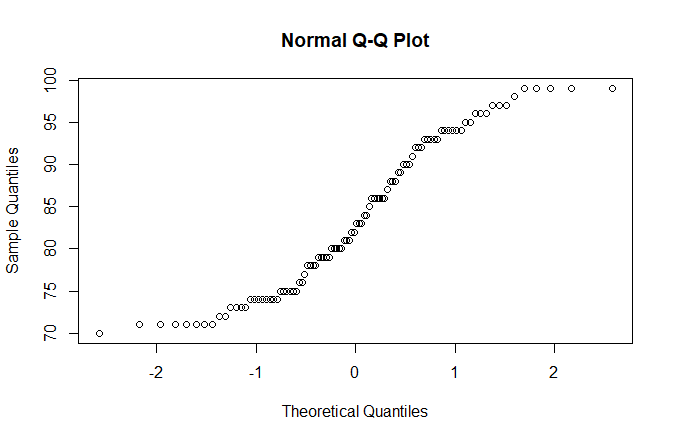
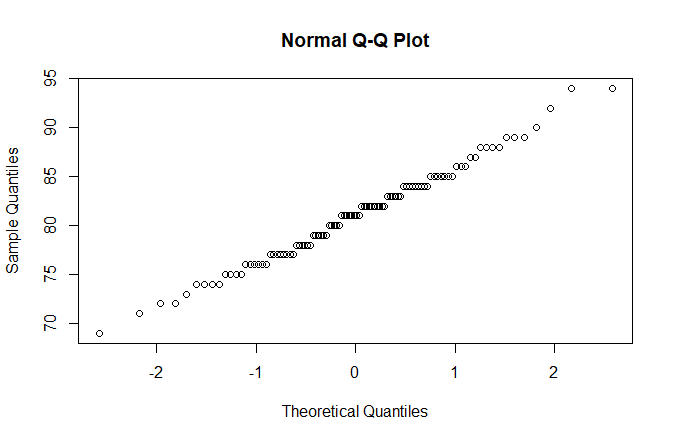
越接近1、3象限角平分线越接近正态分布,如图,x2就较x1更接近正态分布
最后
以上就是忧心白云最近收集整理的关于R语言学习(三)--数据可视化(一)1、生成一组数据框2、简单分析数据3、数据可视化的全部内容,更多相关R语言学习(三)--数据可视化(一)1、生成一组数据框2、简单分析数据3、数据可视化内容请搜索靠谱客的其他文章。








发表评论 取消回复