相信大家在开发一些程序会有识别图片上文字(即所谓的OCR)的需求,比如识别车牌、识别图片格式的商品价格、识别图片格式的邮箱地址等等,当然需求最多的还是识别验证码。如果要完成这些OCR的工作,需要你掌握图像处理、图像识别的知识,需要用到图形形态学、傅里叶变换、矩阵变换、贝叶斯决策等很多复杂的理论,这让绝大部分人都会望而却步。
Tesseract这个开源项目的出现让我们普通人也可以涉足OCR的开发。Tesseract可以从图片中识别出文字内容,但不要以为Tesseract可以智能的识别出各种奇形怪状、复杂的图片文字,Tesseract默认只能识别非常标准字体、清晰无干扰的图片文字,刚接触Tesseract的人很多都会发出这样的评价“Tesseract吹的挺厉害,但是识别率很低呀,不好用”。其实我们要识别的内容千奇百怪,Tesseract是需要去训练才能比较高准确率的识别的,我们需要把一批样本图片让Tesseract去尝试识别,然后对他识别出的错误结果进行校正,告诉他“这个图片你识别错了,应该识别为某某某”,这样Tesseract慢慢的就“学会了”怎么样进行识别。也就是如下一个训练过程:
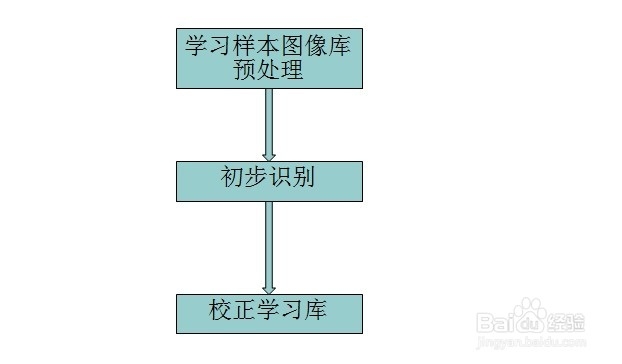
看到上图有一个“预处理”,这是什么意思呢?我们知道,很多验证码都是加了一些干扰处理的,比如说有的验证码加了噪音点、有的验证码加了干扰线、有的验证码加了干扰背景、有的验证码做了文字扭曲。如下图:
最后
以上就是紧张泥猴桃最近收集整理的关于C#识别验证码技术-Tesseract的全部内容,更多相关C#识别验证码技术-Tesseract内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复