使用Tess4J和TesseractOCR实现对图片文字的识别提取
背景:OCR场景识别主要使用 TesseractOCR和tess4J,Tesseract主要优势表现在中文文字识别的准确度和速率,tess4J识别英文的效果较好,且可移植性较高(中文识别效果可经训练后达到较好的效果),本次主要记录Tess4J和tesseractOCR的使用方法
TesseractOCR的简易使用:
1、安装tesseractOCR(安装包下载地址: http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe)
2、下载完成后进行安装(可根据自己需要下载所需语言包,这里我下载的是中英文的语言包)如果有其它语言的要求可以去github上自行下载(https://github.com/tesseract-ocr/tessdata)下载完成后放入tessdata目录下
3、配置环境变量:
path:C:Program Files (x86)Tesseract-OCR
新增系统变量:
TESSDATA_PREFIX
C:Program Files (x86)Tesseract-OCRtessdata
4、配置完成后,控制台 tesseract --version可查看对应版本
5、使用 tesseract xxx.jpg test -l chi_sim命令实现文字的提取和识别(不过这个识别成功率不是很好,可以通过训练字库的方式提高准确率 ->Todo)
Tess4J的使用
1、官网下载 tess4J 官网链接
2、下载完成解压后的目录
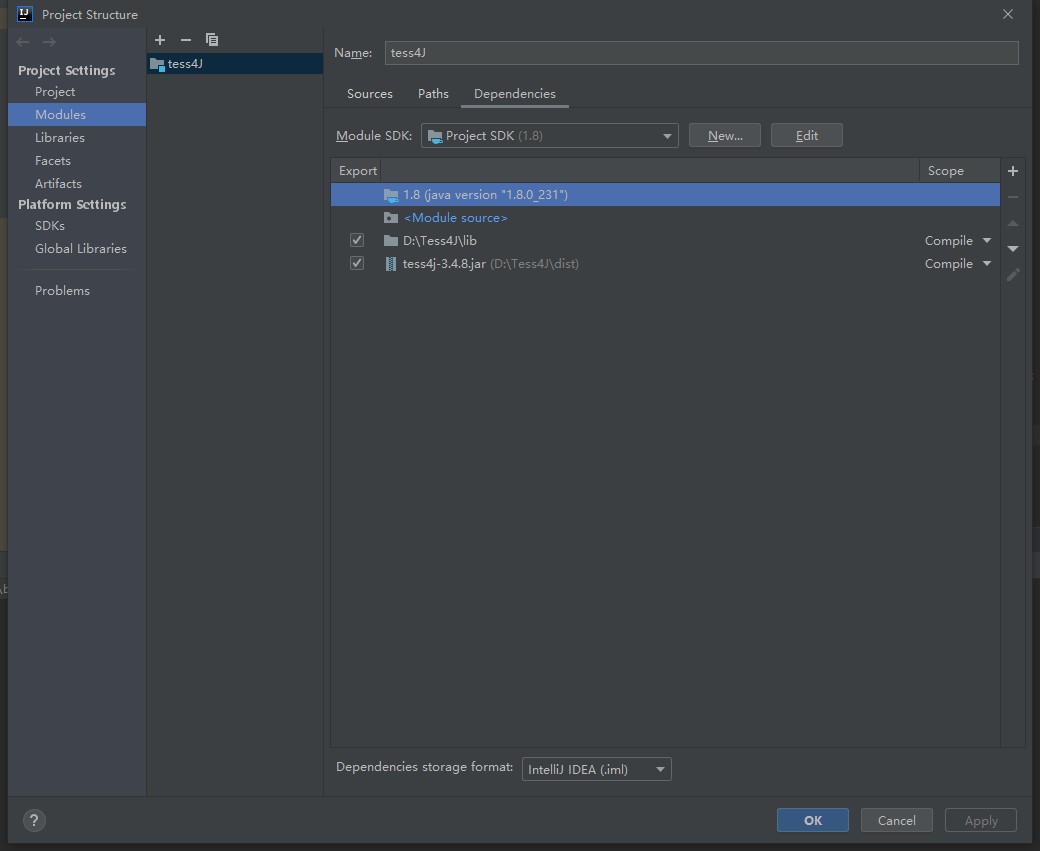
3、使用Idea,新建一个java工程,将dist目录和lib目录下的jar包导入项目
File -> Project Structure -> Module ->Dependencies -> add JARs and directorys
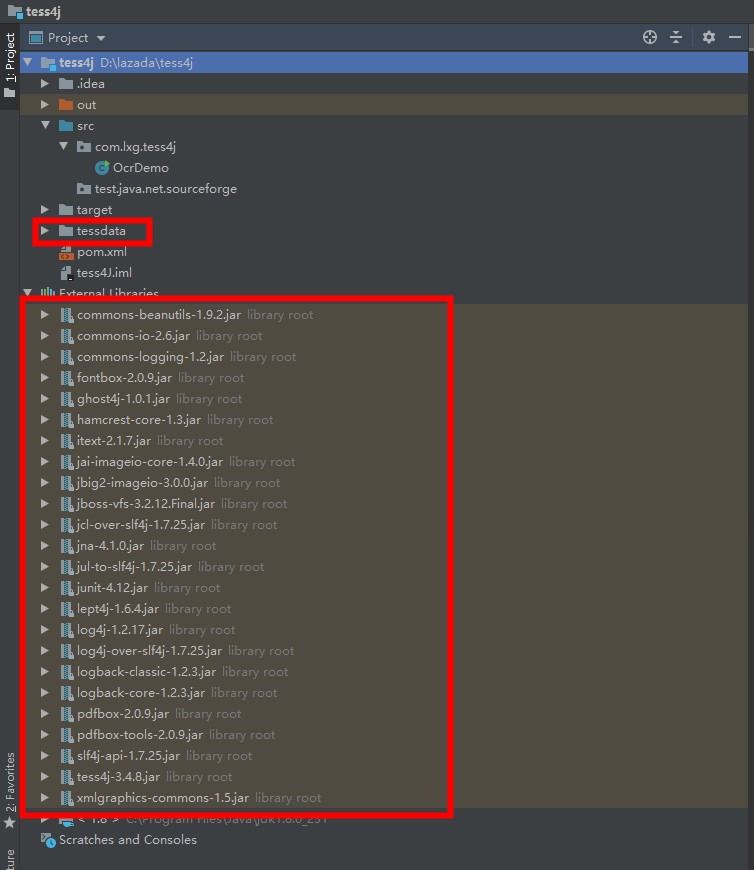
4、导入完成后,将tessdata目录copy到与src同级的目录下
5、该软件默认的识别的是英文,如果相要能识别中文,需要将中文的训练文本chi_sim.traineddata存放到C:Program Files (x86)Tesseract-OCRtessdata中。可以编写测试类进行识别效果检验(Todo.可以针对场景进行训练提高识别效果)
package net.sourceforge.tess4j.example;
import java.io.File;
import net.sourceforge.tess4j.*;
public class TesseractExample {
public static void main(String[] args) {
// ImageIO.scanForPlugins(); // for server environment
File imageFile = new File("eurotext.tif");
ITesseract instance = new Tesseract(); // JNA Interface Mapping
// ITesseract instance = new Tesseract1(); // JNA Direct Mapping
// instance.setDatapath("<parentPath>"); // replace <parentPath> with path to parent directory of tessdata
// instance.setLanguage("eng");
try {
String result = instance.doOCR(imageFile);
System.out.println(result);
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
}
}
最后
以上就是受伤钢笔最近收集整理的关于Tess4J和TesseractOCR简易使用教程的全部内容,更多相关Tess4J和TesseractOCR简易使用教程内容请搜索靠谱客的其他文章。








发表评论 取消回复