网络爬虫遇到的验证码
在写网络,爬虫时,遇到很多网站存在验证码的情形,有其是比较烦的是,爬取数据的每一页都有验证码,如果只有登陆时,存在验证码,这个很好解决,只需将验证码获取后手动输入就行。
但对于每页都有的,这种方式就不能够解决了,最简单的方式,是自动识别验证码,如果验证码识别成功,能过获得数据,则进行解析,如果验证码没办法识别,则刷新一次验证码,继续识别,直到识别验证码成功,并获得数据。
类似,如下网站:
https://gsqcdzhdjpt.yyhj.zjzwfw.gov.cn/pda.do?method=enterPdajdcx
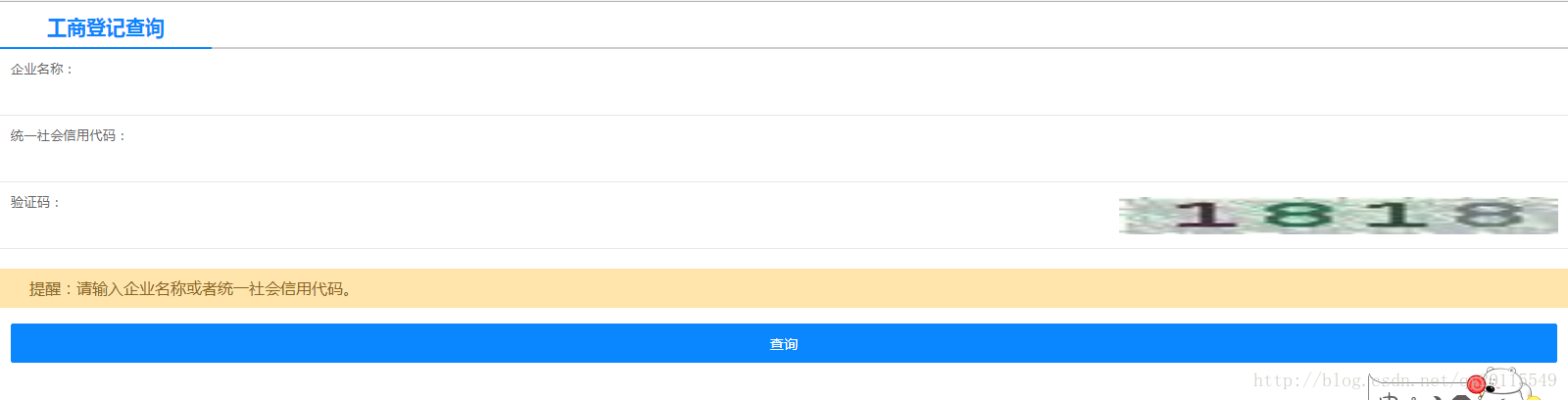
该网站查询一次,就需要输入验证码一次,很烦人。
解决办法
目前验证码自动识别,无非就是自己写算法,利用一些开源工具,或者使用第三方收费的接口。
根据自己所爬数据的网站,选择不同的方式,如对于简单的验证码,完全就可以使用开源软件,如tess4j。


针对这种简单的验证码,是完全可以高效的识别的。
tess4j的使用
首先,在该网站中下载tess4j的安装包。
https://sourceforge.net/projects/tesseract-ocr-alt/files/?source=navbar
比如,我下载的。
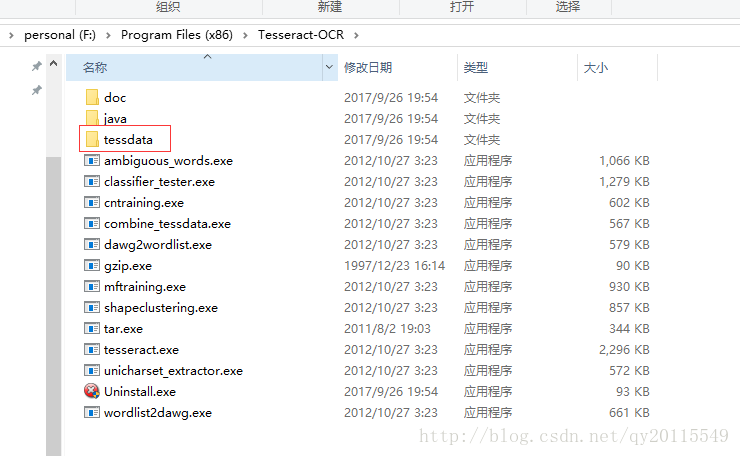
下载之后,点击安装就行了,其实我们最想要的是安装之后的这个文件夹,如下截图。
接着,在maven中添加依赖jar包。
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.4.1</version>
</dependency>等该jar包及其相关依赖jar包下载完成后,使用一下程序便可以识别相关验证码。
package yanzhengma;
import java.io.File;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
public class Test {
public static void main(String[] args) {
try {
File imageFile = new File("e:\login.jpg");//图片位置
ITesseract instance = new Tesseract(); // JNA Interface Mapping
instance.setDatapath("F:\Program Files (x86)\Tesseract-OCR\tessdata");//设置tessdata位置
instance.setLanguage("osd");//选择字库文件(只需要文件名,不需要后缀名)
String result = instance.doOCR(imageFile);//开始识别
System.out.println("图片实际为:7588"+"t图片识别结果为:"+result);//打印图片内容
} catch (TesseractException e) {
e.printStackTrace();
}
}
}
如下,为程序运行结果:
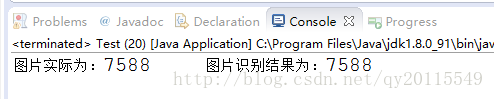
所以,使用该程序对于简单的验证码,识别效果是很好的,但对于复杂度高一些的验证码,则效果并不是很理想。
最后
以上就是酷酷大神最近收集整理的关于网络爬虫中的验证码识别网络爬虫遇到的验证码解决办法tess4j的使用的全部内容,更多相关网络爬虫中内容请搜索靠谱客的其他文章。








发表评论 取消回复