机器学习实战笔记(2)
一、决策树
决策树的一个重要任务是为了数据中所蕴含的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,在这些机器根据数据集创建规则时,就是机器学习的过程。
工作原理:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。然后第一次划分之后,数据将被向下传递到树分支的下一个节点,在这个节点上继续划分数据,采用递归原理处理数据集。递归结束的条件:程序遍历完所有划分数据集的属性(C4.5、CART并不在每次划分都消耗属性,后续将继续学习),或者每个分支下的所有实例都具有相同的分类。
1、信息增益
划分数据集的大原则是:将无序的数据变得更加有序。组织杂乱无章数据的一种方法是使用信息论度量信息(一种理解是:信息量的度量就等于不确定性的多少),在划分数据集之前之后信息发生的变化称为信息增益,获取信息增益最高的特征就是最好的选择。
香农熵公式:
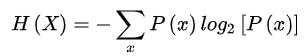
(1)计算香农熵
def calcShannonEnt(dataSet):
'''计算香农熵'''
numEntries = len(dataSet) # 数据总长度
labelCounts = {} # 存放 标签:出现次数 的字典
for featVec in dataSet:
currentLabel = featVec[-1] # 获取当前标签
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0 # 尚不存在创建
labelCounts[currentLabel] += 1 # 已存在次数+1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries # p(x)
shannonEnt -= prob * log(prob, 2) # 以2为底求对数
return shannonEnt
(2)按特征值划分数据集
def splitDataSet(dataSet, axis, value):
'''划分数据集的(待划分的数据集,划分的特征,需要返回分特征值)'''
retDataSet = [] # 待返回的新List对象
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] # 对符合划分条件的,
reducedFeatVec.extend(featVec[axis+1:]) # 去掉该特征值,
retDataSet.append(reducedFeatVec) # 进行抽取.
return retDataSet
-
注意: extend() 与append() 的区别
a = [1,2,3] b = [4,5,6]
a.extend(b) --> [1,2,3,4,5,6]
a.append(b) --> [1,2,3,[4,5,6]]
对划分功能的测试结果如下图所示:

(3)选择最好的划分特征值
def chooseBestFeatureToSplit(dataSet): numFeatures = len(dataSet[0]) - 1 # 除去最后一个labels,所有的特征值总数 baseEntropy = calcShannonEnt(dataSet) # 原始香农熵 bestInfoGain = 0.0; bestFeature = -1 for i in range(numFeatures): # 遍历所有特征值 featList = [example[i] for example in dataSet] # 创建唯一的分类标签列表 uniqueVals = set(featList) # 利用{集合}保留该特征值下唯一的属性值 newEntropy = 0.0 for value in uniqueVals: # 用唯一的属性值,对数据集划分一次 subDataSet = splitDataSet(dataSet, i, value) prob = len(subDataSet)/float(len(dataSet)) newEntropy += prob * calcShannonEnt(subDataSet) # 对所有唯一特征值得到的熵求和 infoGain = baseEntropy - newEntropy # 计算信息增益 if (infoGain > bestInfoGain): bestInfoGain = infoGain # 选择最好的并更新 bestFeature = i return bestFeature对myDat数据选择一次,结果如下:

返回结果为0,说明经过计算后能确定该属性可获得当前最大的信息增益,是划分的最好属性。
(4)递归构建决策树
def createTree(dataSet, labels): '''递归构建决策树''' classList = [example[-1] for example in dataSet] if classList.count(classList[0]) == len(classList): # 当前剩余的数据类别完全相同 return classList[0] # 停止划分 if len(dataSet[0]) == 1: # 所有属性处理完仍有不是同一分类,采用多数表决方法定义该分类 return majorityCnt(classList) bestFeat = chooseBestFeatureToSplit(dataSet) bestFeatLabel = labels[bestFeat] myTree = {bestFeatLabel:{}} # 存储决策树的字典 del(labels[bestFeat]) # 处理完一个属性及时删去 featValues = [example[bestFeat] for example in dataSet] uniqueVals = set(featValues) for value in uniqueVals: # 对每一个分支进行下一次递归 subLabels = labels[:] # 复制一份当前的标签,注意使用切片拷贝 myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels) return myTree
对myDat数据构建决策树,结果如下图所示:

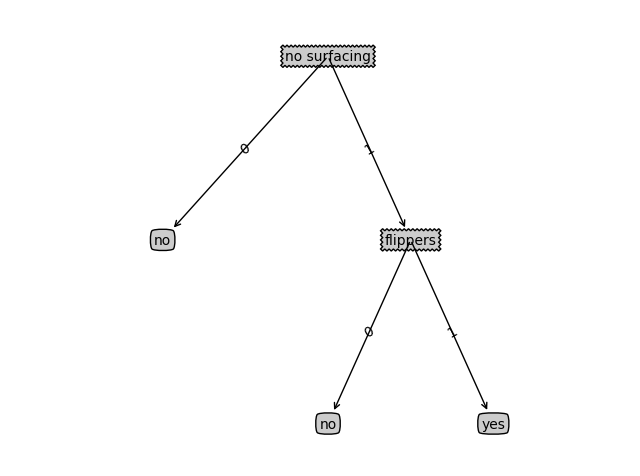
最后
以上就是无奈小馒头最近收集整理的关于机器学习实战笔记(2)机器学习实战笔记(2)的全部内容,更多相关机器学习实战笔记(2)机器学习实战笔记(2)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。



![取list中的列 即对featList = [example[i] for example in dataSet]详解](https://www.shuijiaxian.com/files_image/reation/bcimg26.png)



---循环与序列(知识点)](https://www.shuijiaxian.com/files_image/reation/bcimg3.png)
发表评论 取消回复