目录
一:Transformer
自注意力机制
多头注意力机制
位置编码
二:Vision Transformer
Embedding层
Transformer Encoder
三:Swin Transformer
Swin Transformer的整体架构
Patch Partition
Patch Merging
W-MSA模块
SW-MSA滑动窗口多头注意力机制
Relative Position bias--相对位置偏移
一:Transformer
Transformer主要用于NLP(自然语言处理领域)但不过近年来随着技术的不断发展,Tramsformer也逐渐应用到了计算机视觉领域。Transformer领域最重要的就是自注意力机制和多头注意力机制。Transformer的记忆长度是可以无限长的,并且可以并行。
自注意力机制
注意力机制就是通过计算注意力权重,对特征进行重加权以达到强化有效特征,抑制无效特征的目的--简而言之就是对输入的不同元素考虑不同的权重参数,从而更加关注与输入元素相似的那一部分。自注意力机制的示意图如下:
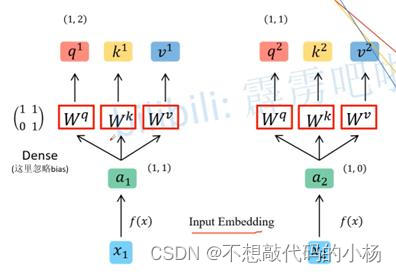
首先假设我们的输入数据为X1和X2,通过Embedding层会将数据映射到一个更高的维度得到对应的a1和a2,再通过W^q,W^k,W^v参数矩阵生成对应的q,k,v(这里的参数矩阵对所有的参数矩阵都是共享的),这里的q会去匹配每一个k,v代表的是。
使用点乘法将q和k进行匹配,计算相似度的公式如下:

其匹配过程如下图:

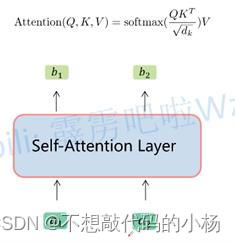
使用q1和k1进行相似度匹配得到α1,1.同理将q1与k2进行匹配运算得到α1,2,再通过Softmax函数将相似度的计算结果映射到0-1之间得到^a1,1和^α1,2,这里得到的两个变量就是针对每一个不同的v其所得到的一个权重值,这个权重值越大就代表我们需要越关注其所对应的v。最后将所得到的权重与其对应的v的值进行相乘,然后再将各个结果进行求和,将自注意力机制抽象成一个模块的话如下图所示:
多头注意力机制
多头注意力机制和自注意力机制类似,将输入的a与参数矩阵相乘得到对应的q,k,v这一步和自注意力机制相同,然后再根据Head的情况对所得的数据进行拆分(实际上就是均分操作)在下图中head的个数是两个,将所有的q,k,v都进行类似的拆分如下图所示
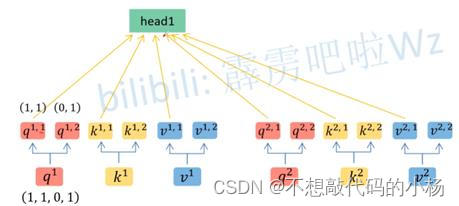
在拆分之后,将拆分所得的第二个数字为1的所有参数都归为head1这一类,同理将所有参数的第二个数字为2的全部归为head2这一类,通过此操作我们便将我们的数据分为了两个类如下所示:
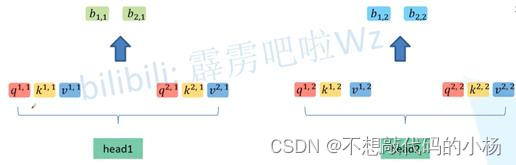
然后再对每一个Head执行自注意力机制的过程进行匹配,得到每一个head的值,然后再对每一个head的值进行拼接如下图示:

拼接的详细过程就是将所得参数下标数字一致的数据进行拼接,最后将拼接所得的矩阵与一个W0矩阵相乘进行融合,最终得到其过程示意图如下所示
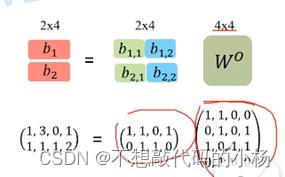
在这里乘上W矩阵是为了确保输入输出的多头注意力机制的长度保持不变
位置编码
位置编码主要是为了下面这个问题而提出的。如下图我们将a2和a3的顺序进行调换。可以发现这样操作后对b1而言是没有任何影响的,但是这种现象是不合理的
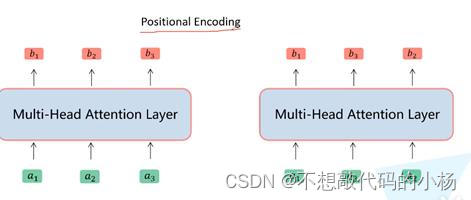
针对这一弊端使用了位置编码的方法,即在输入数据之前加入位置编码吗,这种位置编码可以通过两种方式获取:1)通过公式计算获得位置编码2)使用可训练的位置编码
完整的Transformer结构如下图所示
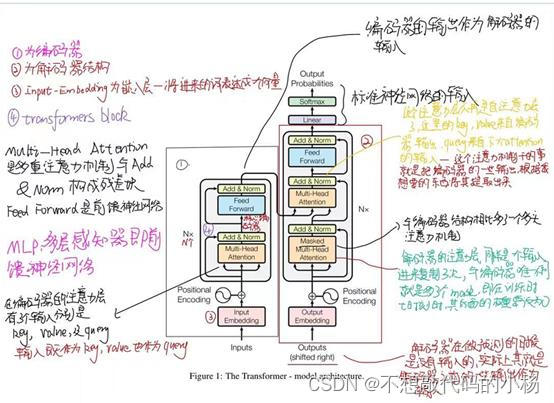
二:Vision Transformer
相比于CNN,Vision Transformer有很多不一样的特性,并且其在计算机视觉领域有着较大的提升。其核心思想就是将图片看出是很多个patch然后当做自然语言处理那样进行处理。
Vision Transformer的模型架构图如下所示:
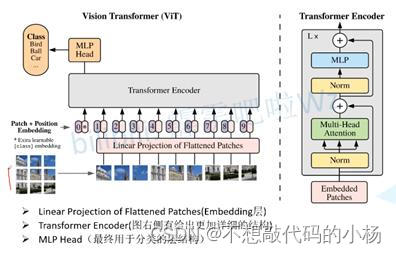
网络的流程步骤:在上图中一张图片被分成了9个patches,然后每一patches都被送入Embedding层,通过这个Embedding层得到一个个向量,我们通常将这些向量称为token。紧接着在这些Token向量上再加上一系列的分类token,再然后再在这些Token上加入有关于位置的信息,再将这些整合的Token送入Transformer的编码器中,最后再通过MLP多层感知机对其进行分类。
Embedding层
实际上Embedding层就是由一个卷积操作和一个Flatten展平操作组成的,卷积核的个数768实际上对应的就是token_dim上的维度。
在刚开始的时候输入图片的维度是224*224*3,这个RGB图片通过在Embedding层中的卷积层处理后变为了14*14*768.紧接着将高度和宽度这两个维度的信息进行展平。则由3维向量展平成2维向量变为196*768.
但是紧接着需要增加一个类别的token,这个token是可以被训练初始化的,将这个类别Token与先前得到的向量进行拼接得到一个197*768的向量。
最后通过一个相加的方式来加上一个位置编码,所以此时向量的维度是不会发生改变的。
Transformer Encoder
VIT的编码器层是由一个编码器模块和MLP多层感知机模块进行重复堆叠L次的结构。其整体结构如下图所示:
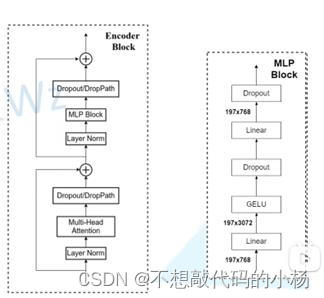
其过程是首先输入后进行一个归一化处理,紧接着再通过一个多头注意力机制,然后再通过一个Dropout层随机失活神经元来防止出现过拟合的现象。然后再与先前的输入结果残差相加,再送入另一个LayerNorm层。然后再送入一个MLP多层感知机。MLP的结构如图中右半部所示
Transformer应用于计算机视觉的难点是在于输入的序列长度过长,在CV领域输入的图片一般是224*224的,若将其展成像素进行输入的话那么序列的长度会达到5000多,这样会使得计算复杂度过高。采用的解决办法是将图片分成一个又一个的patches,将每一个patches当成元素进行输入,将图片块类比成NLP当中的单词。
三:Swin Transformer
Swin Transformer与Vision Transformer的对比图如下所示:
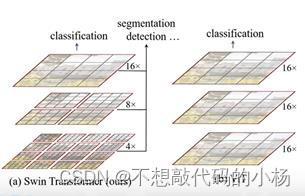
1)首先Swin Transformer所构建的特征图是具有层次结构的,随着特征层的不断加深,特征图的高和宽都是不断变小的。
2)Swin Transformer使用了一个又一个的窗口形式,将特征图分割开来,并且窗口与窗口之间是没有重叠的。相比较而言VIT中特征图是一个整体。引入了这个Windows窗口结构之后就可以在单独的窗口进行多头注意力机制的计算,独立的窗口之间是不进行信息传递的,这样也能够降低计算量,尤其是下采样的倍率比较低的情况下,更加能减少计算量。
Swin Transformer的整体架构
Swin Transformer的整体架构如下图所示:
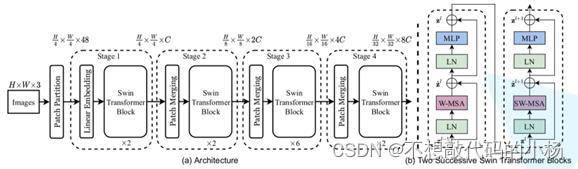
网路结构如上图所示,通过一个又一个的stage来对图像进行下采样,没进行一次下采样,图像的尺寸都会减半,但是其深度这一维度会翻倍
Patch Partition
网络结构中的patch Partition如下图所示
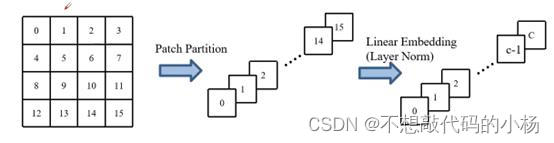
即将每个像素在深度方向上进行拼接,而图片是具有3通道的,则上图中0到15个的16个像素点总共有16*3=48个,图中的(b)都是成对进行使用的
Patch Merging
patch merging是对图像进行下采样,使用Patch Merging处理过后的图像,再送入Transformer模块进行处理,其过程如下图所示:
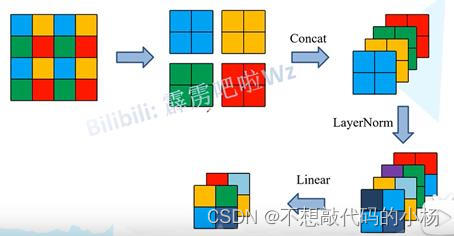
具体过程为:假设我们输入的特征图的尺寸的高和宽都是4,以2*2的大小作为窗口,在一个窗口当中存在着4个像素,将每个窗口位置的像素取出来,然后可以得到4个特征矩阵。然后再将这4个特征矩阵在深度方向上进行拼接。然后再在深度方向上进行Layer Norm处理,再通过一个全连接层进行映射,其深度就会减半。此时得到的特征矩阵就是经过Patch Merging处理过后所得的特征矩阵。
W-MSA模块
使用这个模块的目的是为了减少计算量,可是却具有窗口之间无法进行信息交互的缺点,其示意图如下所示:
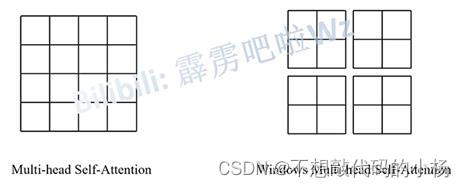
对于普通的MSA模块来说,会对每一个像素去求解它的q,k,v的值,对任意一个像素所求得的q会对特征图中其他像素的k进行一个相似度的匹配,然后再进行一系列的操作。
而在W-MSA模块当中,我们首先会将特征图分成一个又一个的Windows后再进行处理,然后再对每个窗口的内部执行多头注意力机制的计算,但是这种方法窗口与窗口之间是无法进行信息交互的,这种缺点也会使得感受野变小,无法看到全局的感受野。
SW-MSA滑动窗口多头注意力机制
使用这个滑动窗口多头注意力机制的目的是为了实现不同windows之间的信息交互。SW-MSA结构示意图如下所示:
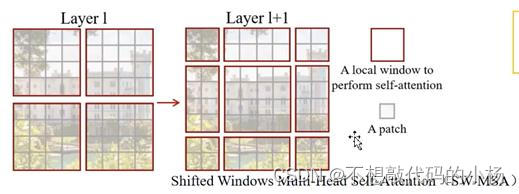
在Swin Transformer网络结构中一般是先使用了W-MSA模块后紧跟着使用SW-MSA模块的。在使用完W-MSA模块后再对特征进行分块可以理解为在上一层的基础上将每个windows分别向下后再向右移动了两个像素。经过这样处理后每个窗口都具有了特征图不同块的信息。这种方法虽然解决了不同窗口之间不能产生信息交互的缺点,却也使得窗口的数量大大的增加了。窗口的数量变为了9个从而增大了计算量。
解决办法如图所示:
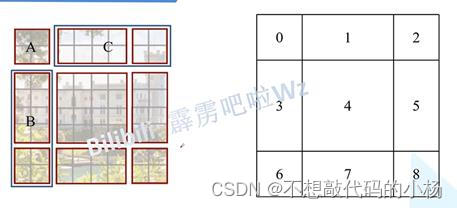
将上图中的区域对应着进行标号,首先将区域A,C移动到下面来,再将移动过后的A,B移动到右边去,这样移动完以后重新对窗口区域进行划分,将4区域看成是一个4*4的窗口,将5和3整体看成是一个4*4的窗口,将7和1整体看成一个窗口,将8,6,2,0整体看成一个窗口区域,并且以上窗口的大小都是4*4的,并对这4个窗口内部进行多头注意力机制,这样减少了计算量,这样虽然减少了计算量,却引入了一个新的问题那就是比如由5和3组成的窗口之中,5和3不是相邻的区域这样直接进行多头注意力机制的计算会出现问题。我们的最终的目标是为了在窗口独立的对5和3区域进行多头注意力的计算。
针对上述出现的问题,解决办法如下图所示:
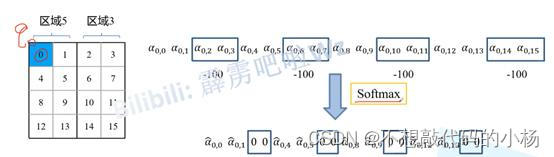
如上图所示,将区域3的像素点所得到的相似度的值减去100,再将其映射到0到1之间,此时相似度的值变为0.此时区域3的所有权重都变为了0,通过此操作就将区域3和区域5的多头注意力的计算给区分开了。另外特别需要注意的点是再进行完全的计算过程后需要将全部的数据移动回原来的位置。
另外在判断移动哪几行哪几列的时候要有M/2取整来计算,其中M是指窗口的尺寸。
Relative Position bias--相对位置偏移
相对位置偏移的示意图如下所示:
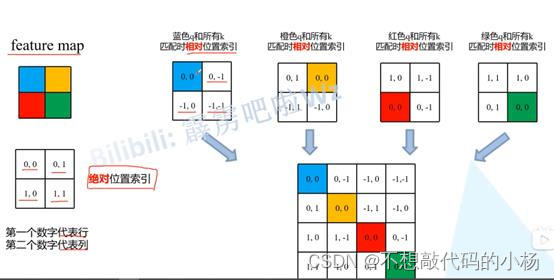
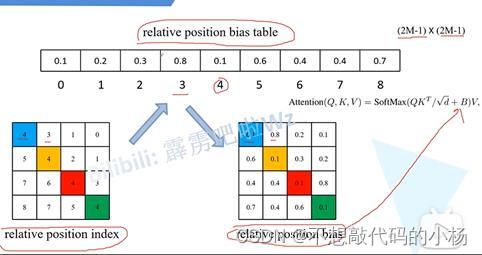
求一个像素点的相对位置索引就是求该像素的绝对位置索引与其他像素点的绝对位置索引的差,为了避免出现相同的位置索引,则采用以下方法进行解决。首先偏移从0开始,行标,列标加上M-1,其中M对应的是窗口大小。然后再以行标乘上2M-1。再将行标和列标进行相加。通过以上步骤就可以将二元坐标转换成了一元坐标。如下图所示将其一一对应即可。
最后
以上就是俊逸小蚂蚁最近收集整理的关于关于Transformer的相关概念模型的个人理解一:Transformer二:Vision Transformer三:Swin Transformer的全部内容,更多相关关于Transformer的相关概念模型的个人理解一:Transformer二:Vision内容请搜索靠谱客的其他文章。








发表评论 取消回复