论文笔记
A Frustratingly Easy Approach for Joint Entity and Relation Extraction
原文链接
github
概述
本文是陈丹琦博士关于实体识别与关系抽取的一篇论文,文本使用了一种pipeline的方式而非joint learning的方式超越了之前的一众模型,在数据集ACE04/05、SciERC达到SOTA。
- NER采用span-based的模型,其实也是解决嵌套实体的问题。
- 在RE的输入端加上了实体类型。(最大的亮点)
(pipeline 指的是使用两个不同的模型去做NER(实体识别),RE(关系抽取,joint 是指使用一个模型完成两个任务,近年来的研究结果joint 的模型往往效果更好,但是这篇论文采用的是pipeline的形式实现结果超过了以往的所有joint的模型,算是打破了近年来joint一定比pipeline好的观点。)
模型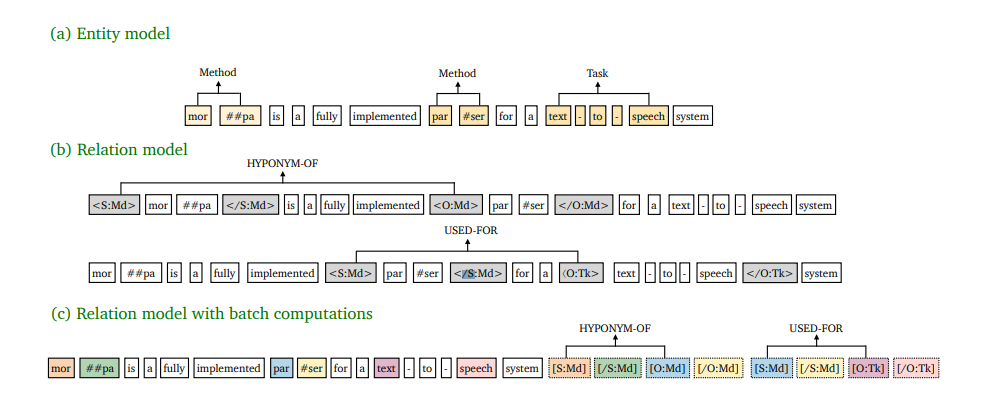
上文我们就提过了,在关系模型的输入端添加了实体类型信息,<s:md>表示实体开始,</s:md>表示实体结束 ,其中s代表subject,md是实体名。在c部分中颜色一样代表一样的position embeding.
新的改变
Cross-sentence context:其实是引入上下句信息
encoder:采用了bert,ALbert
Efficient Batch Computations:采用了近似计算节省开销
- 位置信息共享,可以理解成,<s:md>与实体的第一个字表示一致,</s:md>与实体的走后一个字表示一致。
- attention约束:在一个span里所有text只与text做attention,而实体字符(就是人为加入的<s:md>)即于实体字符做attention,也与text做attention.
这样在同一个句子里的所有的所有span都能复用text的attention
实验结果
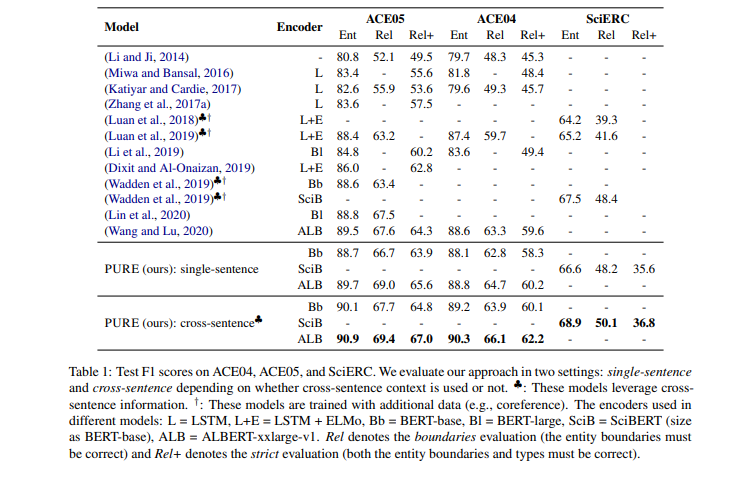
在数据集ACE04/05、SciERC达到SOTA。
上下文信息对比,近似计算(Approx)
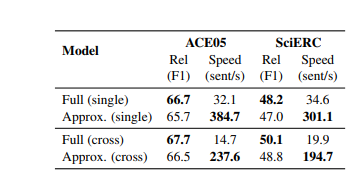
加入上下文信息明显更好,Approx提高了10倍以上的速度
Maker对比
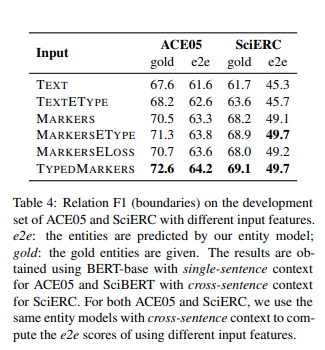
Text:原来的纯文本信息
TYPEDMarkers :本文采取的方式
增加实体类型确实对实验效果有较大帮助。
共享encoder
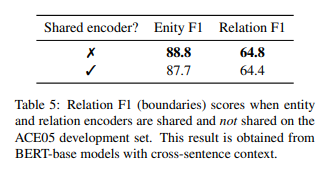
共享了encoder反而效果变差,怎么理解呢,ner和re需要的输入格式就有差别,完成的任务也不同,共享encoder反而增加了噪声(希望大家一起探讨)。
最后
以上就是无辜冬日最近收集整理的关于2021-07-06论文笔记的全部内容,更多相关2021-07-06论文笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复