中文语法纠错任务旨在对文本中存在的拼写、语法等错误进行自动检测和纠正,是自然语言处理领域一项重要的任务。同时该任务在公文、新闻和教育等领域都有着落地的应用价值。但由于中文具有的文法和句法规则比较复杂,基于深度学习的中文文本纠错在实际落地的场景中仍然具有推理速度慢、纠错准确率低和假阳性高等缺点,因此中文文本纠错任务还具有非常大的研究空间。
达观数据在CCL2022汉语学习者文本纠错评测比赛的赛道一中文拼写检查(Chinese Spelling Check)任务中取得了冠军,赛道二中文语法纠错(Chinese Grammatical Error Diagnosis)任务中获得了亚军。本文基于赛道二中文语法纠错任务的内容,对比赛过程中采用的一些方法进行分享,并介绍比赛采用的技术方案在达观智能校对系统中的应用和落地。赛道一中文拼写检查的冠军方案会在后续的文章分享。
本次中文语法纠错任务是对给定的句子输出可能包含的错误位置、错误类型和修正答案,而最终的评测指标是假阳性、侦测层、识别层、定位层和修正层这五个维度指标的综合结果。而且本次评测任务使用的数据是汉语学习者的写作内容,与母语写作者相比汉语学习者的数据本身就具有句子流畅度欠佳、错误复杂度较高等情况。因此,本次评测的难度在于对于汉语学习者的书写内容既要保证检错和纠错的准确率和召回率,还要保证正确句子不能进行修改操作以降低模型的假阳性。本文主要从数据和模型两方面来分享本次比赛中采用的模型和策略。
数据分析
本次评测中,官方提供了CGED的历年比赛数据(41,239条)和Lang8数据(1212,457条)供模型训练,同时提供了3767条评测数据用以验证模型的效果和性能。为了解数据的错误分布以及数据的质量,我们首先对评测数据进行了分析。CGED-21验证集中的错误分布情况如图1所示,由此可以看出数据集中占绝大多数的均为用词错误,其次为缺失错误,而乱序错误的占比最少。
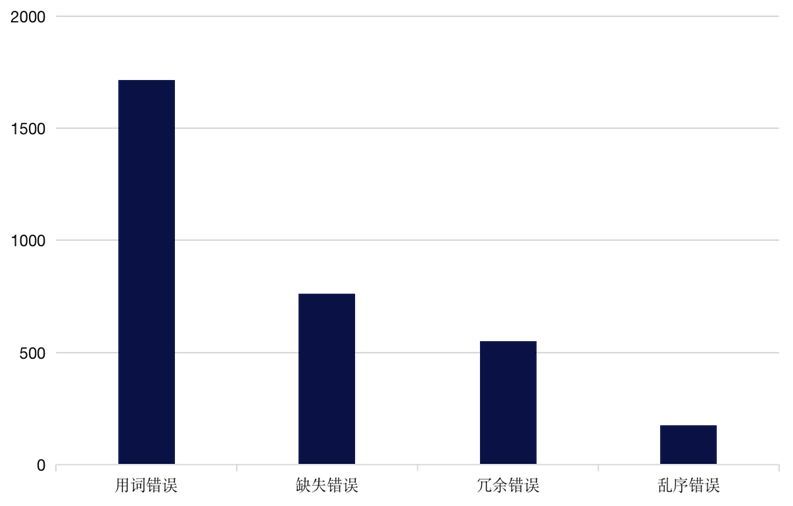
图1 验证集错误占比统计图
同时在数据测验的过程中还发现了CGED和Lang8数据集中存在的一些数据问题。
具体问题如下所示:
-
源句子与目标句子完全不相关;
-
目标句子是对源句子的批注;
-
源句子中存在错误编辑距离较大的情况;
-
数据集中末尾处存在多字的缺失错误
最后
以上就是无聊刺猬最近收集整理的关于中文语法纠错全国大赛获奖分享:基于多轮机制的中文语法纠错数据分析纠错策略实验结果技术落地方案总结展望的全部内容,更多相关中文语法纠错全国大赛获奖分享:基于多轮机制内容请搜索靠谱客的其他文章。








发表评论 取消回复