摘要
语法错误纠正(GEC)是一种很有前途的自然语言处理(NLP)应用,其目的是将具有语法错误的句子更改为正确的句子。神经机器翻译(NMT)方法已被广泛应用于这种类似于翻译的任务。但是,这种方法需要相当大的带有错误注释句子对的平行语料库,这在汉语语法错误纠正领域尤其不容易获得。在本文中,我们提出了一种简单而有效的方法,通过动态MASK来改进基于NMT的GEC模型。通过在训练过程中将随机MASK动态添加到原始源句子中,可以生成更多种错误纠正的句子对实例,以增强语法错误纠正模型的泛化能力,而无需其他数据。NLPCC 2018任务2上的实验表明,我们的MaskGEC模型提高了神经GEC模型的性能。此外,在没有任何额外知识的情况下,我们针对中国GEC的单一模型就优于NLPCC 2018 Task 2中的当前最先进的集成系统。
1.介绍
近年来,语法错误校正(GEC)作为自然语言处理(NLP)应用引起了人们的极大兴趣。语法错误纠正任务的定义是:给定一个可能包含语法错误的句子,需要检测和纠正该句子中出现的错误,并返回其无错误的自然语言表示形式。对于不正确的句子作为源语言,而将更正的句子作为目标语言,可以将GEC任务视为机器翻译(MT)任务。 例如,可以将英语GEC转换为从“不良”英语到“良好”英语的翻译。
随着深度学习的飞速发展,基于序列到序列(seq2seq)模型的神经机器翻译(NMT)方法已成为机器翻译领域的主流。最近,相当多的工作将神经seq2seq模型应用于语法纠错任务并取得了一些进展。但是,这些基于NMT的GEC模型面临一个问题。由于经过纠错的句子对的平行语料库的大小有限,因此通常不足以训练通常包含数百万个参数的GEC的seq2seq模型。因此,即使测试用例句子与训练实例仅稍有不同,模型也可能无法纠正它。
为了克服上面提到的神经语法错误校正模型的缺点,我们提出了一种简单而有效的动态MASK方法来增强神经GEC模型的性能。
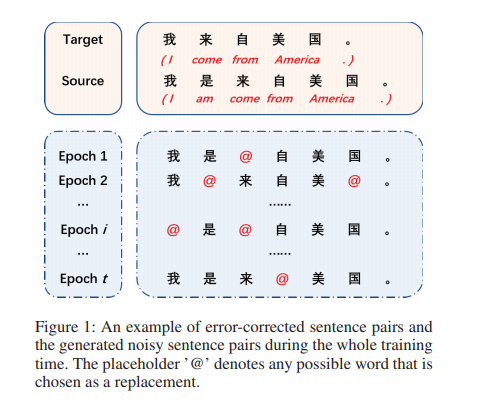
在训练过程中,我们通过MASK将各种随机噪声添加到输入中,以动态生成嘈杂的源语句,但保持目标语句不变。通过将新的源句子与相应的目标句子配对,我们可以获得更丰富的纠错句子对,如图1所示。为了方便起见,我们称呼这种新构建的纠错句子对为噪声句子对。我们不是使用前面提到的噪声句子对作为额外的训练实例,而是将原始句子直接替换为源方端的嘈杂句子。这样,我们的语法错误校正模型可以在整个训练过程中获得更多的错误校正后的句子对样本,而无需增加训练集的大小。通过引入噪声,我们的方法增强了语法错误校正模型的泛化能力。
实验表明,采用动态MASK方法的语法错误校正模型的性能优于基线seq2seq模型,并在中文GEC任务中取得了最新的成果。
简而言之,本文做出了以下贡献:
- 我们提出了一种简单而有效的动态MASK方法来解决中文神经GEC模型的局限性。据我们所知,这是将动态MASK技术引入中文GEC任务的第一项工作。
- 我们的模型无需额外的资源即可在NLPCC 2018任务2中获得最先进的结果,这证明了我们的方法在中文GEC任务中的有效性。
2.模型
2.1 神经GEC模型
seq2seq模型基本上由编码器-解码器体系结构组成。Seq2seq模型已被证明在许多NLP任务中都是有效的,例如机器翻译,文本摘要,对话系统等。为了纠正潜在的错误,GEC系统必须理解句子的含义。这对模型来说可能很难,因为自然语言句子中的单词之间可能存在长距离依赖关系。循环神经网络(RNN)擅长对单词序列进行建模并捕获句子的上下文。因此,RNN通常被以前的GEC神经模型采用,尤其是其变种门控循环单元(GRU)网络。因为大多数语法错误是局部的,并且取决于附近的单词,所以GEC系统捕获局部上下文至关重要。卷积神经网络(CNN)能够通过窗口操作有效地捕获局部信息。通过分层的多层卷积网络,远距离单词之间的更广泛上下文也可以被更高层捕获。注意力机制目前已在序列学习任务上取得了巨大成就。最近的神经语法错误校正模型引入了注意机制,使模型集中于句子中语法错误的相关部分。
大多数以前的神经GEC模型都使用RNN或CNN作为编码器和解码器,而Transformer是一种新型的编码器解码器框架。Google最近提出的Transformer完全基于注意力机制。Transformer已展示出强大的单词序列建模能力,并在机器翻译任务中取得了最佳性能。
我们的语法错误校正模型采用了Transformer作为NMT框架。值得一提的是,NMT框架的选择不是本文的重点。我们希望其他seq2seq模型将从我们的方法中受益。
给定一个源序列:
X
=
(
x
1
,
x
2
,
.
.
.
x
m
)
(1)
X=(x_1,x_2,...x_m)tag{1}
X=(x1,x2,...xm)(1)
以及与之相对应的正确序列:
Y
=
(
y
1
,
y
2
,
.
.
.
,
y
n
)
(2)
Y=(y_1,y_2,...,y_n)tag{2}
Y=(y1,y2,...,yn)(2)
其中
m
m
m和
n
n
n分别是序列
X
X
X和
Y
Y
Y的长度,语法错误校正模型需要估计以下条件概率:
P
(
Y
∣
X
)
=
∏
i
=
1
n
P
(
y
i
∣
y
1
,
.
.
.
,
y
i
−
1
,
X
;
Θ
)
(3)
P(Y|X)=prod^n_{i=1}P(y_i|y_1,...,y_{i-1},X;Θ)tag{3}
P(Y∣X)=i=1∏nP(yi∣y1,...,yi−1,X;Θ)(3)
其中
Θ
Θ
Θ是模型参数。通过最大似然估计(MLE)对模型进行训练,即最大程度地减少对数对数似然(NLL)损失:
l
(
Θ
)
=
−
∑
i
=
1
n
l
o
g
(
P
(
y
i
∣
y
1
,
.
.
.
,
y
i
−
1
,
X
;
Θ
)
)
(4)
l(Θ)=-sum^n_{i=1}log(P(y_i|y_1,...,y_{i-1},X;Θ))tag{4}
l(Θ)=−i=1∑nlog(P(yi∣y1,...,yi−1,X;Θ))(4)
2.2 动态MASK
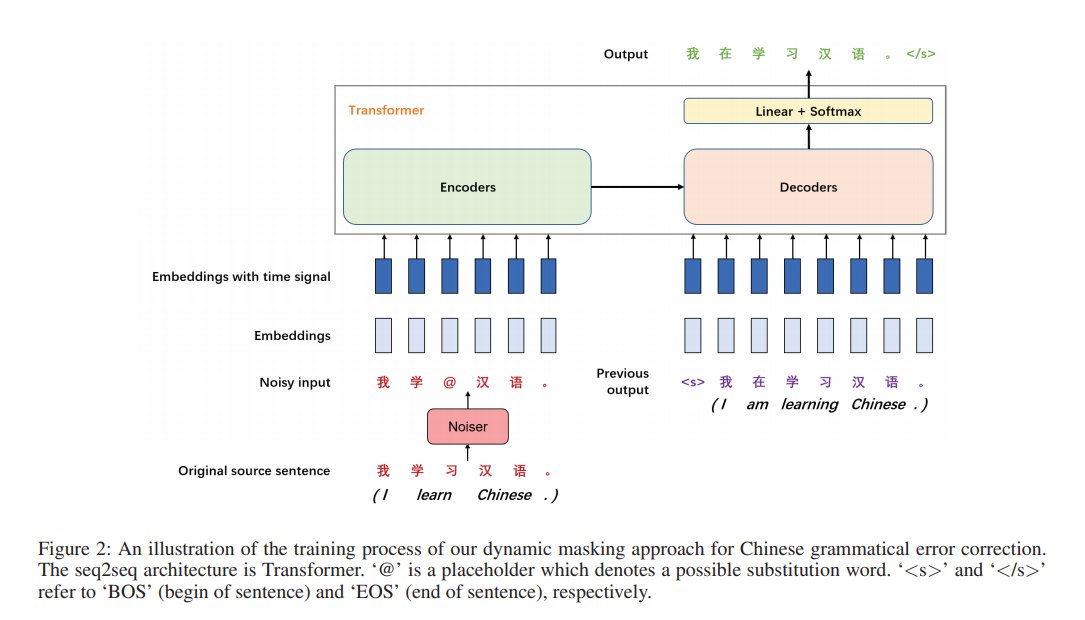
对于神经网络模型,训练语料库的大小通常是模型性能的关键因素之一。为了方便,高效地获取更多的训练样本,我们在训练过程的第
j
j
j个epoch以一定的概率将噪声添加到源句子
X
X
X中(图2),从而获得噪声的文本:
X
~
(
j
)
=
(
x
~
1
(
j
)
,
.
.
.
,
x
~
i
(
j
)
,
.
.
.
,
x
~
m
(
j
)
)
(5)
tilde X^{(j)}=(tilde x^{(j)}_1,...,tilde x^{(j)}_i,...,tilde x^{(j)}_m)tag{5}
X~(j)=(x~1(j),...,x~i(j),...,x~m(j))(5)
其中,
X
~
(
j
)
tilde X^{(j)}
X~(j)中的第
i
i
i个单词由下式给出:
x
~
i
(
j
)
=
{
f
(
x
i
)
,
p
≤
δ
x
i
,
p
>
δ
tilde x^{(j)}_i=begin{cases} f(x_i), & ple delta\ x_i, & pgt delta end{cases}
x~i(j)={f(xi),xi,p≤δp>δ
其中
f
f
f是单词替换函数,
p
p
p是间隔
[
0.0
,
1.0
]
[0.0,1.0]
[0.0,1.0]上的均匀分布生成的随机数,
δ
δ
δ是替换概率的阈值(我们设置
δ
=
0.3
δ=0.3
δ=0.3)。
在
t
t
t轮迭代期间,产生一组有噪声的源文本
{
X
~
(
1
)
,
X
~
(
2
)
,
.
.
.
,
X
~
(
t
)
}
{tilde X^{(1)},tilde X^{(2)},...,tilde X^{(t)}}
{X~(1),X~(2),...,X~(t)}。需要我们的GEC模型将这组有噪声的文本映射到目标句子
Y
Y
Y。我们在算法1中描述了我们的噪声训练方法,其中
S
S
S是训练语料库中原始的纠错句子对的集合,而
S
(
t
)
S^{(t)}
S(t) 是epoch
t
t
t中的噪声句子对的集合。

不同的噪声方案可能会对模型性能产生不同的影响。我们考虑以下噪声方案,并进行一系列实验以进行比较:
(1)Padding Substitution
源句子中的每个单词都有一定的概率
δ
δ
δ被选择,并用填充符号“
<
p
a
d
>
<pad>
<pad>”代替。通过填充替换,我们可以在GEC模型的训练过程中以指数方式增加训练样本,并减少训练实例的重复。此外,我们可以通过用填充符号替换某些单词来减少GEC模型对特定单词的依赖性。通过这种方式,GEC模型被迫从隐藏层的上下文中学习替换单词的含义,这有助于提高性能。
(2)Random Substitution
与填充替换类似,GEC模型从源句子中以概率
δ
δ
δ随机抽取一些单词。但是,该模型使用词汇表
V
V
V中的随机词代替填充符号来替换它们。替换词是从词汇表V中以
1
/
∣
V
∣
1/|V|
1/∣V∣的概率均匀采样的,其中
∣
V
∣
|V|
∣V∣是
V
V
V的大小。随机替换比填充更适合GEC任务,因为它可以使模型生成更接近真实错误文本的噪声样本。
(3)Word Frequency Substitution
通常,自然语言中的语法错误倾向于将高频单词误认为低频单词。因此,我们认为,频率较高的单词应以更频繁的替换错误出现在错误的源句子中。因此,我们提出了一种基于词频的替代方法。我们的GEC模型对训练语料库中目标句子中每个单词的出现次数进行计数,以获取单词频率。然后,计算词汇量
V
V
V的概率分布
P
r
o
b
(
V
)
Prob(V)
Prob(V)。在训练过程中,GEC模型根据单词频率而不是均匀地采样单词进行替换。
(4)Homophone Substitution
由谐音现象引起的错误在中文文本的语法错误中占很大比例。有很多汉字同音字。它们的发音相同,但形状和含义不同。图3演示了由这种现象引起的一些语法错误。我们使用pypinyin库获取字符的对应拼音,这是标准中文的正式罗马化系统。然后,我们根据目标句子中的拼音对单词进行分类,并根据拼音类别对单词频率进行计数。因此,我们可以获得每种拼音类型的单词的概率分布。在训练模型时,我们通过前面介绍的方法选择要替换的单词。然后,我们查询这些单词的拼音,并根据相应的单词频率分布选择同音字进行替换。
(5)Mixed Substitution
除了上述单个加噪方案外,我们还提出了一种混合替代方法。对于每个训练实例,我们的中文GEC模型都会随机选择一个加噪方案或空方案(保持不变),并将其应用于训练过程。这样,我们整合了所有的单个噪声方案,并获得了更多不同的噪声句子对。
最后
以上就是贪玩睫毛膏最近收集整理的关于MaskGEC: Improving Neural Grammatical Error Correction via Dynamic Masking翻译摘要1.介绍2.模型的全部内容,更多相关MaskGEC:内容请搜索靠谱客的其他文章。








发表评论 取消回复