目录
Video-Sentence Alignment
Matching Score.
Multi-Instance Learning.
Cross-Sentence Relations Mining
Temporal Consistency.
Semantic Consistency.
Model Training
这篇论文的Task是视频定位
只有视频文本的对应关系,但是没有ground truth的时间边界,因此是弱监督的
现有的弱监督解决方案首先分别定位不同的MoIs,但这不是最优的方案,因为它忽略了段落中的跨句子关系在时间定位中发挥了重要作用。
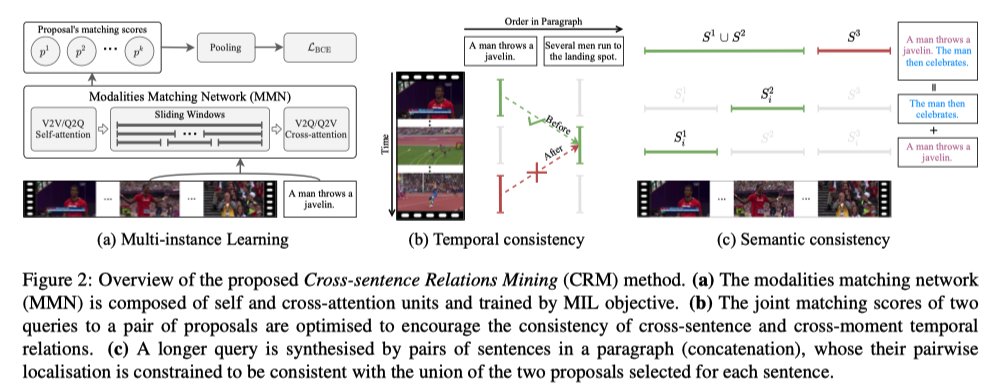
Video-Sentence Alignment
将video V 和 query Qj输入到一个Modalities Matching Network (MMN),--》得到每一个proposal和query的matching score,具体来说:
MMN由堆叠的attention units组成
Attention units由自注意组成,
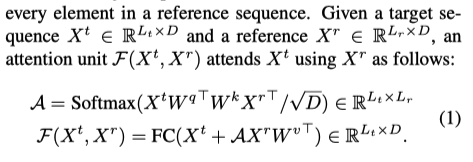
这里计算self attention 和 cross-attention
![]()
![]()
Matching Score.
将视频V通过sliding window strategy随机划分为Ls个proposals
![]()
将文本特征沿句子数量维度进行最大池化,得到Qj,文本向量
![]()
将文本特征和proposal特征融合在一起

将联合特征输入到一个线性分类器中

Multi-Instance Learning.
由于没有明确的时间边界的annotation,因此作者进行了video-level的优化,将得到的proposal score进行maxpooling,作为video query的matching score
随机采样其他两个视频作为negative,并使用相同的方式计算matching score


Cross-Sentence Relations Mining
Temporal Consistency.
视频帧自然地按照时间顺序展示给观众,不同MoIs的时间关系本质上应该按照它们在段落中的描述顺序进行编码
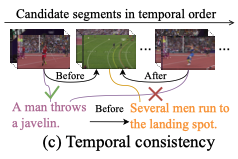
segments的发生的时间顺序应该和对应的sentence的时间顺序是一致的

即 将时间一致的联合概率分数视为positive,反之negative

Semantic Consistency.
两个单个sentence和segment所对应的时间边界的交集 应该和联合的sentence和segment所对应的时间边界应该保持一致
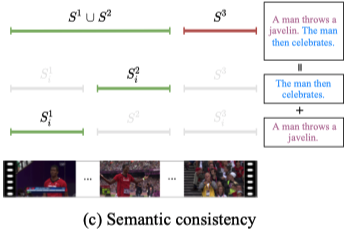

即将重合概率小于某一阈值的视为positive,反之negative
Model Training
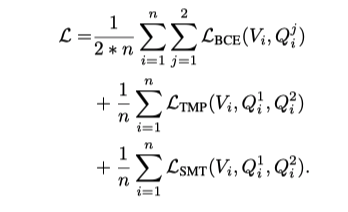
最后
以上就是超帅期待最近收集整理的关于Cross-Sentence Temporal and Semantic Relations in Video Activity Localisation----ICCV2021论文阅读Video-Sentence AlignmentCross-Sentence Relations MiningModel Training的全部内容,更多相关Cross-Sentence内容请搜索靠谱客的其他文章。








发表评论 取消回复