常用机器学习数据库
UCL机器学习知识库
Amazon AWS公开数据集
Kaggle
KDnuggets
0) 数据准备
在http://files.grouplens.org/datasets/movielens/ 下载用户电影评级数据,用户信息和属性信息。
1) 安装IPython和matplotlib模块
IPython是针对Python的高级交互式shell程序,包含内置一系列实用功能的pylab,如Numpy, Scipy和matplotlib.
sudo apt-get install ipython sudo apt-get install python-matplotlib2) 使用IPython shell启动PySpark终端,同时启动pylab功能
IPYTHON=1 IPYTHON_OPTS="--pylab" ./bin/pyspark
3) 导入数据,用系统文件创建RDD
user_data = sc.textFile("~/Data/ml-100k/u.user")
#查看第一行,first向驱动程序返回RDD的首个元素
user_data.first()

#或查看前k(k = 3)行,返回RDD的前k个元素
user_data.take(3)

4) 探索用户数据
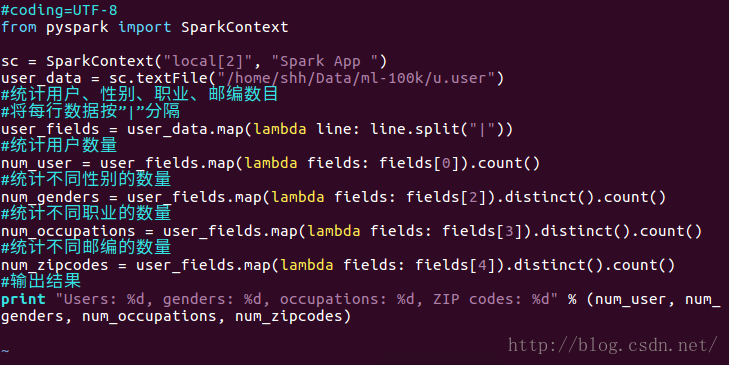
user_data = sc.textFile("/home/shh/Data/ml-100k/u.user")
#统计用户、性别、职业、邮编数目
#将每行数据按”|”分隔
user_fields = user_data.map(lambda line: line.split("|"))
#统计用户数量
num_user = user_fields.map(lambda fields: fields[0]).count()
#统计不同性别的数量
num_genders = user_fields.map(lambda fields: fields[2]).distinct().count()
#统计不同职业的数量
num_occupations = user_fields.map(lambda fields: fields[3]).distinct().count()
#统计不同邮编的数量
num_zipcodes = user_fields.map(lambda fields: fields[4]).distinct().count()
#输出结果
print "Users: %d, genders: %d, occupations: %d, ZIP codes: %d" % (num_user, num_genders, num_occupations, num_zipcodes)

加上如下三行将程序写在文件里,也可以执行得到相同结果
#coding=UTF-8
from pyspark import SparkContext
sc = SparkContext("local[2]", "Spark App ")
$SPARK_HOME/bin/spark-submit processData.py

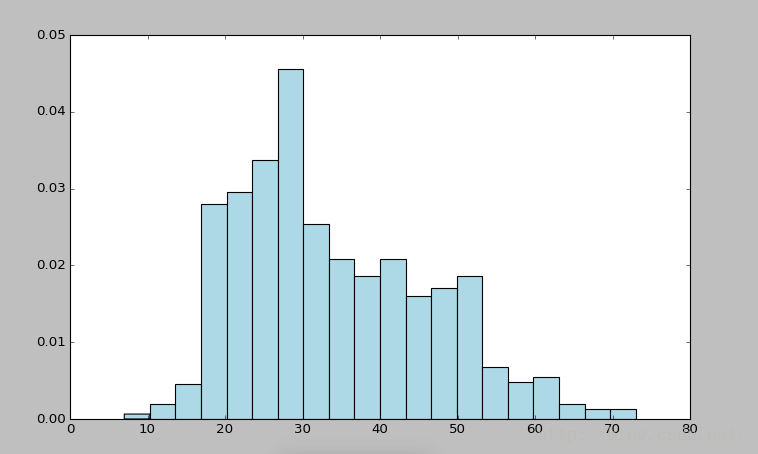
<pre name="code" class="python">#创建直方图,分析用户年龄的分布
ages = user_fields.map(lambda fields: int(fields[1])).collect()
#将直方图分为20个区间,正则化,使每个方条表示改区间的人数占总数的比。
hist(ages, bins=20, color='lightblue', normed=True)
<pre name="code" class="python">fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16, 10)
IPYTHON=1 IPYTHON_OPTS="--pylab" ./bin/pyspark3) 导入数据,用系统文件创建RDD
user_data = sc.textFile("~/Data/ml-100k/u.user")
#查看第一行,first向驱动程序返回RDD的首个元素
user_data.first()#或查看前k(k = 3)行,返回RDD的前k个元素
user_data.take(3)4) 探索用户数据
user_data = sc.textFile("/home/shh/Data/ml-100k/u.user")
#统计用户、性别、职业、邮编数目
#将每行数据按”|”分隔
user_fields = user_data.map(lambda line: line.split("|"))
#统计用户数量
num_user = user_fields.map(lambda fields: fields[0]).count()
#统计不同性别的数量
num_genders = user_fields.map(lambda fields: fields[2]).distinct().count()
#统计不同职业的数量
num_occupations = user_fields.map(lambda fields: fields[3]).distinct().count()
#统计不同邮编的数量
num_zipcodes = user_fields.map(lambda fields: fields[4]).distinct().count()
#输出结果
print "Users: %d, genders: %d, occupations: %d, ZIP codes: %d" % (num_user, num_genders, num_occupations, num_zipcodes)
加上如下三行将程序写在文件里,也可以执行得到相同结果
#coding=UTF-8
from pyspark import SparkContext
sc = SparkContext("local[2]", "Spark App ")
$SPARK_HOME/bin/spark-submit processData.py<pre name="code" class="python">#创建直方图,分析用户年龄的分布
ages = user_fields.map(lambda fields: int(fields[1])).collect()
#将直方图分为20个区间,正则化,使每个方条表示改区间的人数占总数的比。
hist(ages, bins=20, color='lightblue', normed=True)<pre name="code" class="python">fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16, 10)
最后
以上就是含糊蜡烛最近收集整理的关于Spark机器学习笔记3--探索和可视化数据的全部内容,更多相关Spark机器学习笔记3--探索和可视化数据内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复