题目
基于非线性扩展的在线多实例学习的早期表情检测(Early Expression Detection via Online Multi- Instance Learning With Nonlinear Extension)
摘要
基于视频的面部表情识别在过去十年中受到了广泛关注,而早期表情检测(EED)仍然是一个相对较新且具有挑战性的问题。EED 的目标是在表情开始之后和结束之前尽快识别表情。这种及时的能力有许多潜在的应用,从人机交互到安全。最大余量早期事件检测器(MMED)是用于早期事件检测的众所周知的排名模型。它可以实现具有竞争力的EED性能,但受到几个关键限制:1)MMED在提取有用信息进行段比较时缺乏灵活性,导致在探索段对之间的排序关系时性能较差;
2)由于约束较多,训练过程较慢,内存需求通常也难以满足;
3)MMED本质上是线性的,因此可能不适合非线性特征空间中的数据。
为了克服这些限制,我们提出了一个用于 EED 的在线多实例学习 (MIL) 框架。特别是,首次引入 MIL 技术对 MMED 进行泛化,提出了基于 MIL 的 EED(MIED),它比 MMED 更通用、更灵活,因为可以采用各种实例构建和组合策略。为了加快训练过程,我们在在线环境中重新制定 MIED,并为 EED开发在线多实例学习框架 (OMIED) 。为了进一步利用数据分布的非线性结构,我们在 OMIED 中加入了核方法,从而提出了用于早期表达检测的在线核多实例学习。在两个流行的和一个具有挑战性的基于视频的表情数据集上的实验证明了所提出方法的效率和有效性。
Bib
@article{Xie:2018:14861496,
author = {Li Ping Xie and Da Cheng Tao and Hai Kun Wei},
title = {Early expression detection via online multi-instance learning with nonlinear extension},
journal = {{IEEE} transactions on neural networks and learning systems},
volume = {30},
pages = {1486--1496},
year = {2018}
}
符号系统
| 符号 | 含义 |
|---|---|
| V i , i = 1 , … , n boldsymbol {V}^i,i=1,dots,n Vi,i=1,…,n | 表情的视频序列 |
| I i = [ s i , e i ] boldsymbol {I}^i=[s^i,e^i] Ii=[si,ei] | 表情的标签信息 |
| s i s^i si | 表情的开始 |
| e i e^i ei | 表情的结束 |
| L i boldsymbol {L}^i Li | V i boldsymbol {V}^i Vi的长度 |
| t = 1 , 2 , … , L i t=1,2,dots,boldsymbol {L}^i t=1,2,…,Li | 时间 |
| I t i = I i ∩ [ 1 , t ] boldsymbol {I}_t^i=boldsymbol {I}^i cap [1,t] Iti=Ii∩[1,t] | 已发生的部分表情 |
| L ( t ) ] = { I ∈ N 2 mathcal {L}(t)]={boldsymbol {I} in mathbb{N}^2 L(t)]={I∈N2| I ⊂ [ 1 , t ] } ∪ { ∅ } boldsymbol {I}subset[1,t]}cup{empty} I⊂[1,t]}∪{∅} | 所有可能发生的时间间隔集合 |
| V I boldsymbol {V}_boldsymbol {I} VI | 视频片段 |
| B I i , I ∈ L ( L i ) ] boldsymbol {B}_boldsymbol {I}^i ,boldsymbol {I}inmathcal {L}(boldsymbol {L}^i)] BIi,I∈L(Li)] | 视频片段 |
方法概述
- List item
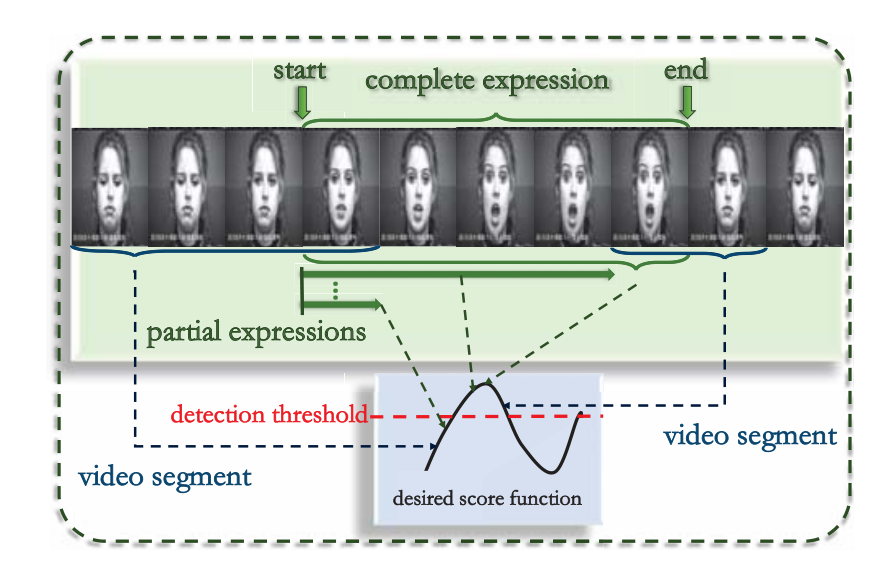
EED指在表情开始之后和结束之前尽快检测到表情,每一部分都有对应的分数,当分数达到阈值检测到Surprise的表情。
背景:
自动面部表情识别(FER):大多数方法使用整个视频序列来训练识别模型,并且只有在视频结束时才能进行预测,不及时。
EED:机器人交互、预防犯罪等方面需要及时性。
两者区别:
(1)FER 旨在将表情分为几个典型的类别;EED 希望尽早检测到某种类型的表情,本文专注于确定视频中是否出现表情
(2)FER 无法确定视频中某个表情的开始和结束, EED 可以实现。
MMED(最大边际早期事件检测器):它在训练中直接比较两个完整的片段,片段中包含的一些有用信息可能会被丢弃或稀释;
多示例联系:
每个完整的视频片段——包
B
I
i
=
{
V
I
,
1
i
,
…
,
V
I
,
n
I
i
i
}
boldsymbol {B}_boldsymbol {I}^i={boldsymbol {V}_{boldsymbol {I},1}^i,dots,boldsymbol {V}_{boldsymbol {I},n_boldsymbol {I}^i}^i}
BIi={VI,1i,…,VI,nIii}
一些候选子集(较短视频片段)——实例
V
I
,
j
i
boldsymbol {V}_{boldsymbol {I},j}^i
VI,ji
算法:
(1)基于MIL的EED——MIED
为每个实例提取特征,bag 的输出是实例输出的组合;可以采用各种实例构造和组合策略。
(2)为了减少了内存消耗和训练时间,在在线环境中重新制定 MIED——在线多实例学习框架OMIED
每次都考虑一个视频序列,使用视频序列一个一个地更新模型
(3)考虑数据分布的非线性结构,将 OMIED 内核化——OKMIED
待解决的问题
所提出的方法可能不适用于微表情识别,因为这样的表情极难观察,并且可能被伪造的表情完全掩盖。在变化不明显或包含的帧数太少的情况下,所提出的方法可能不是一个好的选择。
实验
FER视频数据集:Cohn–Kanade (CK+)、CASIA、UvA-NEMO
CK+ 和 CASIA 数据集包含六个原型表达式:愤怒、厌恶、恐惧、快乐、悲伤和惊讶
UvA-NEMO 数据集用于分析自发/摆姿势的微笑
最后
以上就是着急指甲油最近收集整理的关于【论文泛读】2018-1-Early Expression Detection via Online Multi- Instance Learning With Nonlinear Extension的全部内容,更多相关【论文泛读】2018-1-Early内容请搜索靠谱客的其他文章。








发表评论 取消回复