Learning temporal regularity in video sequences
论文地址链接
Abstract
由于视频中有意义活动(指异常)具有模糊的定义以及视频中场景混乱,因此作者通过学习规则运动模式(称为regularity)的生成模型来解决这个问题。
作者主要构建了两个模型①首先利用传统手工制作的时空局部特征,并在其上学习一个完全连接的自动编码器。②建立了一个完整的卷积前馈自动编码器来学习局部特征和分类器作为一个端到端学习框架。
作者从多个数据集训练捕获regularity。通过实验证明了作者的方法取得了竞争性的性能。
Conlusion
与abstract内容类似
Introduction
学习有意义或显著时刻的时间视觉特征(异常)是非常具有挑战性的,因为这些时刻的定义是不明确的,即视觉上没有边界。学习普通时刻的时间视觉特征相对容易,因为它们经常表现出时间规律的动态,如周期性的人群运动。所以仅使用只包含普通时刻即正常帧的数据集进行训练以学习规则时间模式。作者使用多个不同数据集训练一个模型然后用于多个视频数据集的测试。
之前通过利用仅包含正常样本视频进行训练的方法涉及到稀疏编码和词袋的组合,但是单词袋不保留单词的时空结构,需要关于单词数量的先验信息,而且用于训练和测试的稀疏编码优化计算成本很高,特别是对于视频等大数据。
作者提出了一种基于自动编码器的方法。它的目标函数比稀疏编码具有更高的计算效率,并且在动态编码的同时保留了时空信息,通过只包含正常样本的训练集以获取小的重构误差为目的训练自编码器,在测试阶段自编码器对正常样本会产生较小的重构误差而对于异常样本会产生较大的重构误差。
作者基于两种类型特征学习两个自编码器,一个是之前SOTA方法使用的手工特征,但是这种特征不是为该任务专门设定的所以可能是次优的,所以作者设定了端到端的模型。作者在Avenue、Subway、ped1和ped2数据集上进行了训练。作者通过从视频中合成最规则的帧,描绘涉及不规则运动的对象,从单个帧中预测过去和未来的规则运动展示了他们的方法在各种应用中发现视频的时间规则的外观变化模式。
作者的贡献概述如下:①展示了自编码器能有效学习长持续视频中的动态规律并用于鉴别视频中的异常。②使用全卷积自编码器学习低层次的运动特征③将该模型应用于各种应用,包括学习时间规律性,检测与不规则运动相关的对象,过去和未来帧预测,以及异常事件检测。
PS:主要亮点在于使用卷积自编码器端到端训练模型,在此之前应该无人尝试过,自编码器最初是用来提取特征的,15年BMVC那篇就是仅使用它提取特征,但这个朴素的想法16年才有人尝试或许是因为视频异常检测当时过于小众。此外本文的实验很丰富。
Method
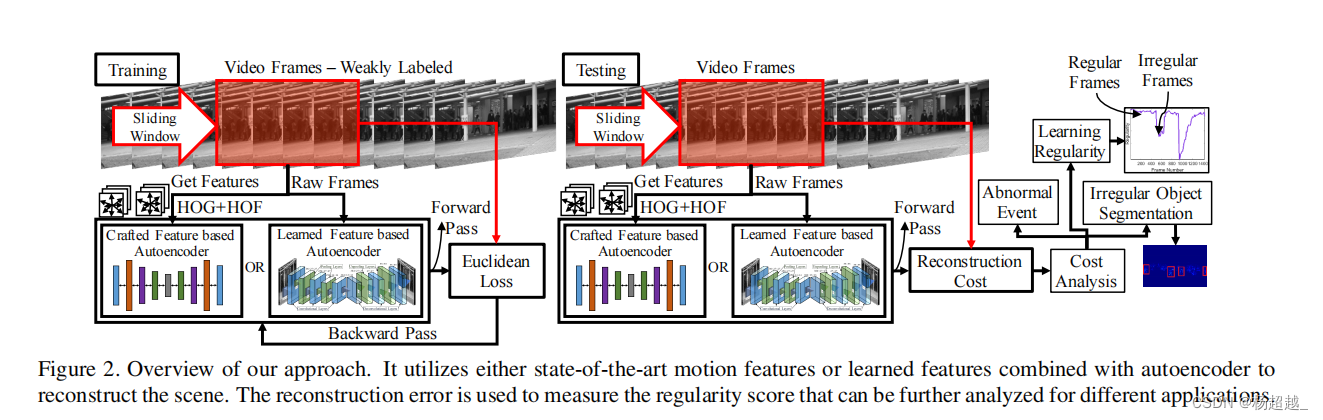
基于手工特征
首先从视频帧中提取手工制作的外观和运动特征。然后,使用提取的特征作为输入到一个全连接神经网络的自动编码器,以学习视频中的时间规律性。手工特征包括HOG、HOF,涉及到了时间和空间的特征,因手工特征目前基本已不再使用,具体细节可见论文。输入最后为204维,编码器结构如下图:
较小的中间层用于学习紧凑的语义和减少噪声信息,输入和重构的均为HOG和HOF所以值的范围为0到1因此使用tanh或者sigmoid激活函数,Relu对于连接很多神经元的话值加起来可能会变得非常大,因为是全连接的网络。此外针对大的接受野,使用了稀疏权重初始化技术,在初始化步骤中,每个神经元连接到前一层随机选择的k个单位,其权值由一个零偏置高斯单位得到。因此,每个神经元的输入总数是一个常数,这就避免了大的输入问题。
训练目标函数如下:
X
i
X_i
Xi表示输入的特征,通过自编码器
f
W
f_W
fW产生重构计算均方误差,N为batch大小。
端到端学习
模型结构
作者使用全卷积的自编码器学习,输入为视频片段,网络不包含全连接层因为其会损失空间信息。
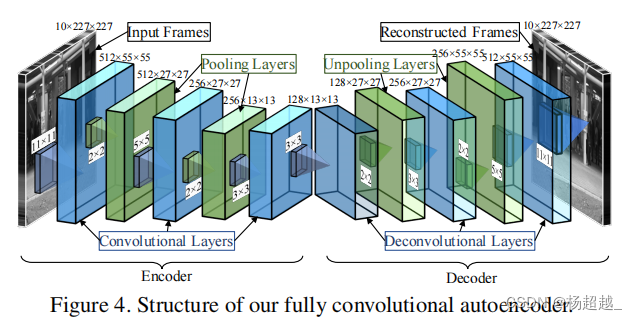
结构如上图编码器三个卷积层两个池化层解码器对称有三个反卷积层和两个上池化层,作者使用滑动窗口构建输入,将T帧堆叠在一起,并将它们用作自动编码器的输入,其中T是滑动窗口的长度,作者的实验表明,随着T的增加,由于它包含了较长的运动或时间信息,其结果具有更强的识别力如下图所示。
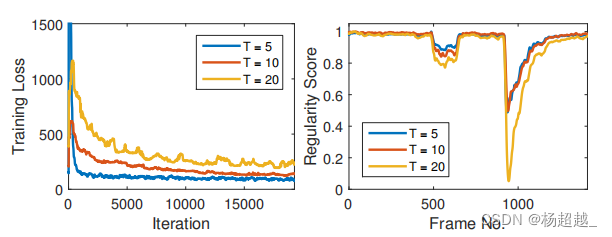
随着T的增加,训练损失需要更多的迭代才能收敛,因为更多通道的输入更有可能具有更多的不规则性,从而阻碍学习的规律性。另一方面,一旦学习了模型,规则区域和不规则区域之间的规则性评分更容易区分。
数据增强
模型参数多需要大量数据进行训练,所以作者尝试了数据增强。主要方法是用各种跳跃的步长拼接帧来构造T帧大小的的输入长方体。作者从视频序列中采样三种类型的长方体stride-1、stride-2、stride-3。对1,2,3,4,5 stride-1采样为1,2,3,4,5. stride-2采样为1,3,5。作者还用预先计算的光流进行了实验。给定两帧之间光流的梯度和大小,通过线性组合梯度和大小来计算一个灰度帧。它将输入长方体的时间维度从T增加到2T。通道1… T包含灰度视频帧,而通道T + 1,…, 2T包含灰度光流信息。作者的实验表明,上述操作对效果影响不显著。
卷积和反卷积
池化和上池化
池化采用最大池化,上池化采用最大上池化
目标函数
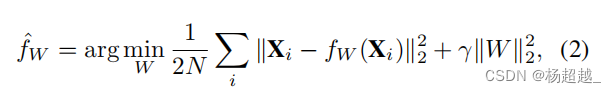
与上述利用手工特征方法类似,只是输入与输出变为了图片
异常分数
训练好模型后,计算视频帧中每个空间位置
(
x
,
y
)
(x,y)
(x,y)的像素的重构误差:
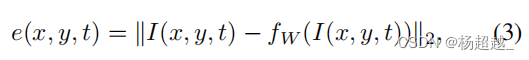
然后将一帧中所有位置重构误差加起来作为该帧的重构误差
e
(
t
)
=
∑
(
x
,
y
)
e
(
x
,
y
,
t
)
e(t)=sum_{(x,y)}e(x,y,t)
e(t)=∑(x,y)e(x,y,t),然后通过以下公式计算规律分数:
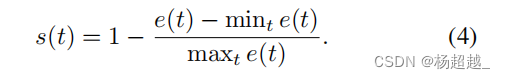
上式max和min表示针对一个视频片段中的所有帧取最大和最小。对于改进轨迹特征上的自编码器,我们只需将
I
(
x
,
y
)
I(x, y)
I(x,y)替换为
p
(
x
,
y
)
p(x, y)
p(x,y),其中
p
(
⋅
)
p(·)
p(⋅)是覆盖了
(
x
,
y
)
(x, y)
(x,y)位置的patch的改进轨迹特征描述符。
实验
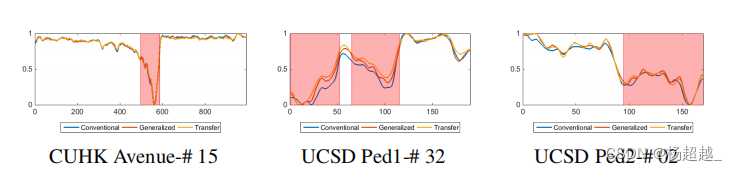
实验AdaGrad优化器,同时使用多个数据集训练模型,下图展示了使用不同数据集训练的损失曲线。对于基于轨迹特征的学习率从0.001开始,batch为1024,weight decay为0.0005.对于全卷积自编码器。batch为32,初始学习率为0.01.当损失停止下降将会减少学习率。使用Xavier初始化模型参数。本文使用的数据集包括Avenue、UCSD pedestrian、Subway。
使用不同数据集训练
作者探究了使用特定目标的数据集、使用全部数据集和使用除了测试目标之外的数据集进行训练如下图,比较前两个结果表示效果并没有因为加入其他数据集而降低,通过比较最后一个与前两个发现该模型对给定数据集没有太过拟合可以推广到未见过的视频。作者认为所提出的网络结构在过拟合和欠拟合之间有很好的平衡。
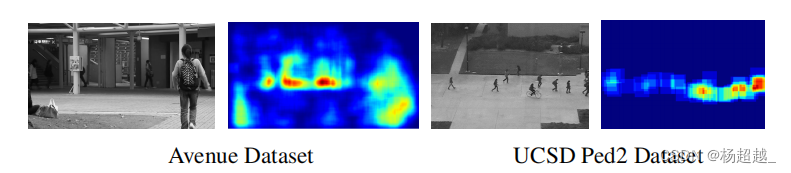
可视化时间规律性
学习的模型从像素精度衡量外观规律性。我们通过卷积自动编码器和改进轨迹的自动编码器收集规律性分数最高的像素,从测试视频中合成最规则的帧。下图的第一列显示了包含不规则运动的样本图像。第二列显示合成的规则帧。合成图像的每个像素沿时间维对应于重建代价最小的像素。最右边的一列显示相应的规律性得分。蓝色代表高分,红色代表低分。

下图显示了使用提高轨迹自动编码器的结果。左列显示视频序列的不规则帧样本,右列显示像素级的规律性分数。它捕捉不规则到补丁精度,因为提取轨迹特征是利用patch的;因此,空间位置不像卷积自编码器那样精确。
预测正常的过去帧和未来帧
使用除中心帧外空白的clip,我们可以预测给定中心帧附近的规律视频clip的过去和未来的帧。给定一幅图像,构造一个时间立方体作为网络的输入,方法是用零值填充其他帧。然后输出产生预测。
异常事件检测
实验结果:

在规律性分数的时间序列中找到局部极小值来检测异常事件。然而,这些局部极小值噪声很大,并不是所有的都是有意义的局部极小值。使用persistence1D算法来识别有意义的局部极小值,并使用固定的时间窗(50帧)跨越该区域,当它们重叠时对附近的扩展局部极小值区域进行分组,以获得最终的异常时间区域。具体地说,如果两个局部极小值彼此在50帧内,它们被认为是同一异常事件的一部分。如果检测到的异常区域与地面真实值至少有50%的重叠,认为它是正确的检测。
作者的模型比最先进的异常事件检测方法性能更好,但有一些误报因为作者的方法能够识别出任何偏离规则的情况,其中许多情况并没有在这些数据集中被标注为异常事件,而其他方法则专注于识别异常事件。
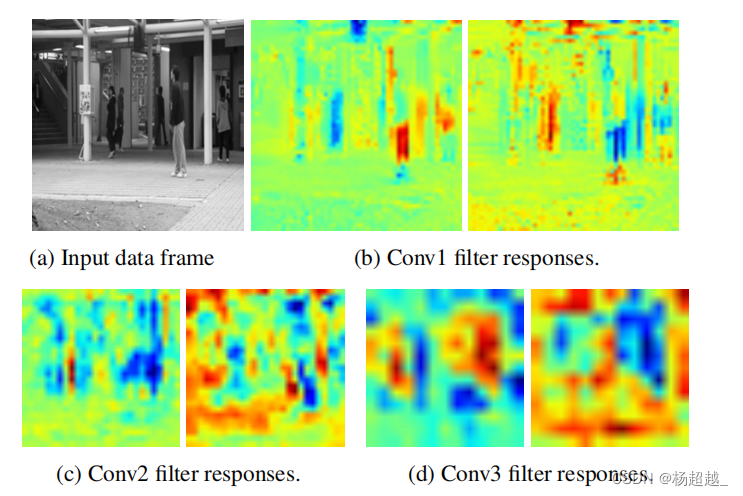
可视化卷积核结果
作者在下图中可视化了模型在Avenue数据集上学习的一些过滤器响应。第一行显示输入数据的一个通道和conv1层的两个滤波器响应。这两个过滤器对不规则物体——框架顶部的袋子的反应完全相反。第一个过滤器提供非常低的响应(蓝色),而第二个过滤器提供非常高的响应(红色)。第一个过滤器可以被描述为检测规律性的过滤器,而第二个过滤器检测。不规则性。所有其他过滤器显示类似。第二行分别显示了conv2层和conv3层滤波器的响应。早期的层(conv1)捕获细粒度的规则运动模式,而较深的层(conv3)捕获更高级别的信息。
最终帧级别 AUC:
ped1(81%)
ped2(90%)
Avenue(70.2%)
Discussion:
1.通过输入连续多帧然后利用二维卷积学习时空特征,是否能学习到时间特征?时序特征非常重要,多帧堆到一起通过卷积核卷积后多帧相加得到最后卷积结果,应该可以学到一定的时序特征。此外时序特征到底是什么?
2.本文的异常分数计算,如何确定一帧的异常分数文中没有详细介绍,目前该文章代码也没有找到。
以上个人理解,希望与大家一起交流~
最后
以上就是时尚小馒头最近收集整理的关于【论文精读】2016-CVPR-Learning temporal regularity in video sequencesLearning temporal regularity in video sequences的全部内容,更多相关【论文精读】2016-CVPR-Learning内容请搜索靠谱客的其他文章。


![[文献阅读]——Prefix-Tuning: Optimizing Continuous Prompts for Generation前言任务介绍Prefix-Tuning实验其它](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)





发表评论 取消回复