文章目录
- 1 引入
- 1.1 题目
- 1.2 代码
- 1.3 摘要
- 1.4 Bib
- 2 RTFM
- 2.1 理论动机
- 2.2 多尺度时间特征学习
- 2.3 特征量级学习
- 2.4 RTFM帧级分类器
- 3 实验
- 3.1 数据集和度量标准
- 3.2 实现细节
1 引入
1.1 题目
2021CVPR:用于弱监督视频异常检测的健壮性时间特征量级学习 (Weakly-supervised video anomaly detection with robust temporal feature magnitude learning)
1.2 代码
Torch:https://github.com/tianyu0207/RTFM
1.3 摘要
弱监督视频级别异常检测是一个典型的多示例学习 (Multi-instance learning, MIL) 问题,每一个视频看作是一个包含多个帧的包,目的是判断包中是否包含异常片段。目前的检测方法性能优异,但它们对正实例,即异常视频中罕见的异常片段的识别,在很大程度上受到了支配性负实例的影响,特别是当异常事件是与正常事件相比时只有很小差异的细微异常时。在许多忽略重要视频时间依赖性的方法中,这个问题更加严重。
为了解决这个问题,提出了健壮性时间特征量级学习:
1)训练了一个特征量级学习函数来有效地识别正实例,大大提高了MIL方法对异常视频负实例的鲁棒性;
2)采用空洞卷积 (Dilated convolutions) 和自注意力机制来捕获长距离和短距离的时间依赖性,从而更可靠地学习特征量级。
1.4 Bib
@inproceedings{Tian:2021:49754986,
author = {Yu Tian and Guan Song Pang and Yuan Hong Chen and Rajvinder Singh and Johan W Verjans and Gustavo Carneiro},
title = {Weakly-supervised video anomaly detection with robust temporal feature magnitude learning},
booktitle = {{IEEE/CVF} International Conference on Computer Vision},
pages = {4975--4986},
year = {2021},
url = {https://openaccess.thecvf.com/content/ICCV2021/html/Tian_Weakly-Supervised_Video_Anomaly_Detection_With_Robust_Temporal_Feature_Magnitude_Learning_ICCV_2021_paper.html}
}
2 RTFM
RTFM的目的是基于弱标记视频来最大程度地区分异常视频和正常视频。给定训练视频的集合
D
=
{
(
F
i
,
y
i
)
}
i
=
1
∣
D
∣
mathcal{D}={(mathbf{F}_i,y_i)}_{i=1}^{|mathcal{D}|}
D={(Fi,yi)}i=1∣D∣,其中
F
∈
F
⊂
R
T
×
D
mathbf{F}inmathcal{F}subsetmathbb{R}^{Ttimes D}
F∈F⊂RT×D是
T
T
T个视频帧的
D
D
D维预计算特征,例如I3D和C3D;
y
∈
Y
=
{
0
,
1
}
,
1
yinmathcal{Y}={0,1},1
y∈Y={0,1},1表示异常,
0
0
0反之。令
r
θ
,
ϕ
(
F
)
=
f
ϕ
(
s
θ
(
F
)
)
r_{theta,phi}(mathbf{F})=f_{phi}(s_theta(mathbf{F}))
rθ,ϕ(F)=fϕ(sθ(F))表示RTFM模型,其将返回一个
T
T
T维特征
[
0
,
1
]
T
[0,1]^T
[0,1]T以表示视频帧是否异常。
模型的训练包括包括端到端多尺度时间特征学习、特征量级学习,以及MIL 分类器。损失函数如下:
min
θ
,
ϕ
∑
i
,
j
=
1
∣
D
∣
ℓ
s
(
s
θ
(
F
i
)
,
s
θ
(
F
j
)
,
y
i
,
y
j
)
+
ℓ
f
(
f
ϕ
(
s
θ
(
F
i
)
)
,
y
i
)
,
min_{theta,phi}sum_{i,j=1}^{|mathcal{D}|}ell_s(s_theta(mathbf{F}_i),s_theta(mathbf{F}_j),y_i,y_j)+ell_f(f_phi(s_theta(mathbf{F}_i)),y_i),
θ,ϕmini,j=1∑∣D∣ℓs(sθ(Fi),sθ(Fj),yi,yj)+ℓf(fϕ(sθ(Fi)),yi),其中
s
θ
:
F
→
X
⊂
R
T
×
D
s_theta: mathcal{F}rightarrowmathcal{X}subsetmathbb{R}^{Ttimes D}
sθ:F→X⊂RT×D是时间特征提取器、
f
ϕ
:
X
→
[
0
,
1
]
T
f_phi: mathcal{X}rightarrow[0,1]^T
fϕ:X→[0,1]T是一个帧级分类器、
ℓ
s
(
⋅
)
ell_s(cdot)
ℓs(⋅)表示最大化正常与异常视频top-
k
k
k个帧特征之间的差异性的损失函数,以及
f
ϕ
(
⋅
)
f_phi(cdot)
fϕ(⋅)是一个使用以上top-
k
k
k个特征的训练损失。
2.1 理论动机
Top-
k
k
k中的基本假设为,正包中包含最少数量的正实例,负包也包含正实例只是数量更少,它进一步假设分类器可以分离正实例和负实例。我们的问题与其不同,因此负包中并不包含正实例,当然也没有其分类器假设。
遵循先前的命名规则,令
X
=
s
θ
(
F
)
mathbf{X}=s_theta(mathbf{F})
X=sθ(F)表示提取的视频时间特征,其中每一个帧特征
x
t
mathbf{x}_t
xt对应
X
mathbf{X}
X的每一行。令
x
+
∼
P
x
+
(
x
)
mathbf{x}^+sim P_x^+(mathbf{x})
x+∼Px+(x)和
x
−
∼
P
x
−
(
x
)
mathbf{x}^-sim P_x^-(mathbf{x})
x−∼Px−(x)分别表示异常帧和正常帧。一个异常视频
X
+
mathbf{X}^+
X+包含
μ
mu
μ个来自
P
x
+
(
x
)
P_x^+(mathbf{x})
Px+(x)的帧,余下
(
T
−
μ
)
(T-mu)
(T−μ)来自
P
x
−
(
x
)
P_x^-(mathbf{x})
Px−(x),正常视频中的所有帧则均来自
P
x
−
(
x
)
P_x^-(mathbf{x})
Px−(x)。
为了学习一个能够区分视频和帧是否异常的函数,定义了一个使用帧的特征量级进行分类的函数,对此定义一个更加温和的假设如下:
E
[
∥
x
+
∥
2
]
≥
E
[
∥
x
−
∥
2
]
.
mathbb{E}[|mathbf{x}^+|_2]geqmathbb{E[}|mathbf{x}^-|_2].
E[∥x+∥2]≥E[∥x−∥2].这意味着通过学习来自
X
mathbf{X}
X的帧级别特征,正常帧的应当有相较于异常帧更小的特征量级。基于以上假设和视频中的top-
k
k
k特征的平均特征量级的优化定义如下:
g
θ
,
k
(
X
)
=
max
Ω
k
(
X
)
⊆
{
x
t
}
t
=
1
T
1
k
∑
x
t
∈
Ω
k
(
X
)
∥
x
t
∥
2
,
(2)
tag{2} g_{theta,k}(mathbf{X})=max_{Omega_k(mathbf{X})subseteq{mathbf{x}_t}_{t=1}^T}frac{1}{k}sum_{mathbf{x}_tinOmega_k(mathbf{X})}|mathbf{x}_t|_2,
gθ,k(X)=Ωk(X)⊆{xt}t=1Tmaxk1xt∈Ωk(X)∑∥xt∥2,(2)其中
g
θ
,
k
(
⋅
)
g_{theta,k}(cdot)
gθ,k(⋅)是由
θ
theta
θ参数化的函数、
Ω
k
(
X
)
Omega_k(mathbf{X})
Ωk(X)是
{
x
t
}
{mathbf{x}_t}
{xt}的大小为
k
k
k的子集。异常视频与正常视频的可分离性 (separability) 定义为:
d
θ
,
k
(
X
+
,
X
−
)
=
g
θ
,
k
(
X
+
)
−
g
θ
,
k
(
X
−
)
.
(3)
tag{3} d_{theta,k}(mathbf{X}^+,mathbf{X}^-)=g_{theta,k}(mathbf{X}^+)-g_{theta,k}(mathbf{X}^-).
dθ,k(X+,X−)=gθ,k(X+)−gθ,k(X−).(3) 定义来自
Ω
k
(
X
+
)
Omega_k(mathbf{X}^+)
Ωk(X+)帧的异常概率为:
p
k
+
(
X
+
)
=
min
(
μ
,
k
)
k
+
ϵ
,
p_k^+(mathbf{X}^+)=frac{min(mu,k)}{k+epsilon},
pk+(X+)=k+ϵmin(μ,k),其中
ϵ
>
0
epsilon>0
ϵ>0,而对于所有来自
Ω
k
(
X
−
)
Omega_k(mathbf{X}^-)
Ωk(X−)的帧,有
p
k
+
(
X
−
)
=
0
p_k^+(mathbf{X}^-)=0
pk+(X−)=0。这意味着在
k
≤
μ
kleqmu
k≤μ时,将于
Ω
k
(
X
+
)
Omega_k(mathbf{X}^+)
Ωk(X+)的top-
k
k
k个帧中找到异常帧。
定理3.1:异常与正常视频的预期可分离性 假设
E
[
∥
x
+
∥
2
]
≥
E
[
∥
x
−
∥
2
]
mathbb{E}[|mathbf{x}^+|_2]geqmathbb{E[}|mathbf{x}^-|_2]
E[∥x+∥2]≥E[∥x−∥2],其中
X
+
mathbf{X}^+
X+包含
μ
∈
[
1
,
T
]
muin[1,T]
μ∈[1,T]个异常实例和
(
T
−
μ
)
(T-mu)
(T−μ)个正常实例,以及
X
−
mathbf{X}^-
X−包含
T
T
T个正常实例。令
D
θ
,
k
(
⋅
)
D_{theta,k}(cdot)
Dθ,k(⋅)表示
d
θ
,
k
(
⋅
)
d_{theta,k}(cdot)
dθ,k(⋅)的随机变量:
1)如果
0
<
k
<
μ
0<k<mu
0<k<μ,则
0
≤
E
[
D
θ
,
k
(
X
+
,
X
−
)
]
≤
E
[
D
θ
,
k
+
1
(
X
+
,
X
−
)
]
0leqmathbb{E}[D_{theta,k}(mathbf{X}^+,mathbf{X}^-)]leqmathbb{E}[D_{theta,k+1}(mathbf{X}^+,mathbf{X}^-)]
0≤E[Dθ,k(X+,X−)]≤E[Dθ,k+1(X+,X−)] 2)对于一个有限的
μ
mu
μ,有
lim
k
→
∞
E
[
D
θ
,
k
(
X
+
,
X
−
)
]
=
0.
lim_{krightarrowinfty}mathbb{E}[D_{theta,k}(mathbf{X}^+,mathbf{X}^-)]=0.
k→∞limE[Dθ,k(X+,X−)]=0. 该定理的第一部分意味着在
k
≤
μ
kleqmu
k≤μ时,随着
k
k
k的增加,异常视频和正常视频之间的可分离性趋于增加,即使它包含一些正常样本。定理的第二部分意味着,当包含多个top实例时,由于正负包中的负实例数量过多,异常和正常视频的分数将变得无法区分。一个示意如图1,其中
score
(
X
)
=
g
θ
,
k
(
X
)
text{score}(mathbf{X})=g_{theta,k}(mathbf{X})
score(X)=gθ,k(X)、
Δ
score
(
X
+
,
X
−
)
=
d
θ
,
k
(
X
+
,
X
−
)
Deltatext{score}(mathbf{X}^+,mathbf{X}^-)=d_{theta,k}(mathbf{X}^+,mathbf{X}^-)
Δscore(X+,X−)=dθ,k(X+,X−),以及
ϵ
=
0.4
epsilon=0.4
ϵ=0.4。该定理指明:
1)当
k
≤
μ
kleqmu
k≤μ时,通过最大化正常视频与异常视频top-
k
k
k个帧之间的可分离性,能够加速异常视频与帧的分类过程;
2)使用top-
k
k
k个特征可以更有效地训练帧分类器,因为异常视频中的top-
k
k
k个实例大部分都是异常的,并且将使用top-
k
k
k个正常片段。此外,仅使用top-
k
k
k的另一个原因是所设计的方法可以在相当少的训练样本下进行。
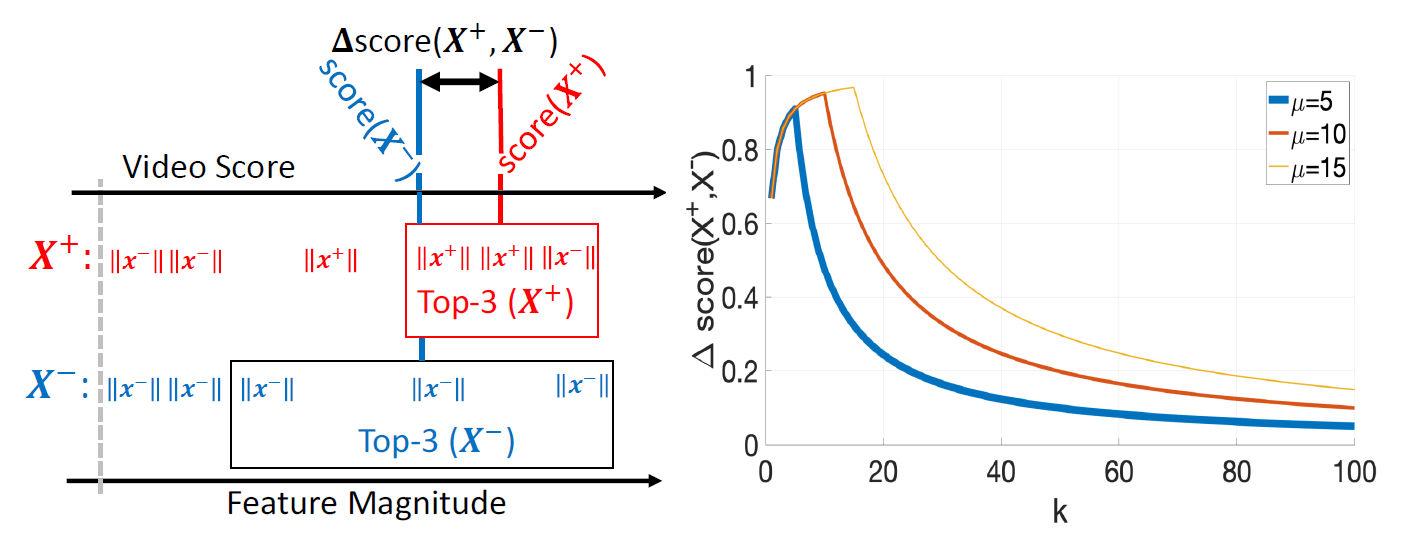
图1:RTFM训练一个特征量级学习函数来高效地检测异常帧并提升MIL方法对异常视频中正常帧的健壮性。左图:异常视频与正常视频的时间特征量级。假设
μ
=
3
mu=3
μ=3表示异常视频中异常帧的数量,将最大化异常视频与正常视频的分数差异
Δ
score
(
X
+
,
X
−
)
Deltatext{score}(mathbf{X}^+,mathbf{X}^-)
Δscore(X+,X−)。参与计算的帧为
k
≤
μ
kleqmu
k≤μ个具有最大时间特征量级帧。右图:
Δ
score
(
X
+
,
X
−
)
Deltatext{score}(mathbf{X}^+,mathbf{X}^-)
Δscore(X+,X−)在
k
≤
μ
kleqmu
k≤μ时逐渐增大,而将
k
>
μ
k>mu
k>μ时逐渐降低。这表明
k
≈
μ
kapproxmu
k≈μ时RTFM在正负视频之间提供了一个很好的差异,即使一些正常帧也具有较大的特征量级
2.2 多尺度时间特征学习
受视频理解注意力机制的启发,所提出的多尺度时间网络 (multi-scale temporal network, MTN) 可以捕捉视频帧之间的多来源局部时间依赖和全局时间依赖。MTN使用时域上的空洞卷积金字塔来学习视频帧的多尺度表示。空洞卷积通常应用于空间域,目的是在不损失分辨率的情况下扩展感受野。在这里,空洞卷积被用于时间维度,因为捕获相邻视频帧的多尺度时间依赖性以进行异常检测很重要。
MTN从预计算特征
F
=
[
f
d
]
d
=
1
D
mathbf{F}=[mathbf{f}_d]_{d=1}^D
F=[fd]d=1D上学习多尺度时间特征。对于给定特征
f
d
∈
R
T
mathbf{f}_dinmathbb{R}^T
fd∈RT,1D空洞卷积定义如下:
f
k
(
l
)
=
∑
d
=
1
D
W
k
,
d
(
l
)
∗
(
l
)
f
d
,
(4)
tag{4} mathbf{f}_k^{(l)}=sum_{d=1}^Dmathbf{W}_{k,d}^{(l)}*^{(l)}mathbf{f}_d,
fk(l)=d=1∑DWk,d(l)∗(l)fd,(4)其中
W
k
,
d
(
l
)
∈
R
W
mathbf{W}_{k,d}^{(l)}inmathbb{R}^W
Wk,d(l)∈RW表示卷积核、
k
∈
{
1
,
…
,
D
/
4
}
kin{1,dots,D/4}
k∈{1,…,D/4}、
l
∈
{
PDC
1
,
PDC
2
,
PDC
3
}
lin{text{PDC}_1,text{PDC}_2,text{PDC}_3}
l∈{PDC1,PDC2,PDC3}、
W
W
W表示卷积核大小、
∗
(
l
)
*^{(l)}
∗(l)基于索引
l
l
l的卷积操作,以及
f
k
(
l
)
mathbf{f}_k^{(l)}
fk(l)表示应用于时间维度的空间卷积的输出特征。空洞因子
{
PDC
1
,
PDC
2
,
PDC
3
}
{text{PDC}_1,text{PDC}_2,text{PDC}_3}
{PDC1,PDC2,PDC3}设置为
{
1
,
2
,
4
}
{1,2,4}
{1,2,4}。
自注意力机制用于补充视频帧之间的全局时间依赖,其已在视频理解中的长期时间依赖、图像分类,以及对象检测展现出优异性能。受到GCN中对全局时间信息的建模,空间自注意力被重写以适应时间维度并捕捉全局时间上下文,即生成一个用于评估帧之间关系的注意力图
M
∈
R
T
×
T
mathbf{M}inmathbb{R}^{Ttimes T}
M∈RT×T。
时间注意力模型 (Temporal self-attention, TSA) :
1)首先使用
1
×
1
1times1
1×1卷积减小空间维度,即
F
∈
R
T
×
D
→
F
(
c
)
=
C
o
n
v
1
×
1
(
F
)
∈
R
T
×
D
/
4
mathbf{F}inmathbf{R}^{Ttimes D}tomathbf{F}^{(c)}=Conv_{1times1}(mathbf{F})inmathbb{R}^{Ttimes D/4}
F∈RT×D→F(c)=Conv1×1(F)∈RT×D/4;
2)应用3个独立的
1
×
1
1times1
1×1卷积层,将
F
(
c
)
mathbf{F}^{(c)}
F(c)转换为
F
(
c
i
)
=
C
o
n
v
1
×
1
(
F
(
c
)
)
mathbf{F}^{(ci)}=Conv_{1times1}(mathbf{F^{(c)}})
F(ci)=Conv1×1(F(c)),其中
i
∈
{
1
,
2
,
3
}
iin{1,2,3}
i∈{1,2,3};
3)构建注意力图:
M
=
(
F
c
1
)
(
F
(
c
2
)
)
T
,
mathbf{M}=(mathbf{F}^{c1})(F^{(c2)})^T,
M=(Fc1)(F(c2))T,其用于获取
F
(
c
4
)
=
C
o
n
v
1
×
1
(
M
F
c
3
)
mathbf{F}^{(c4)}=Conv_{1times1}(mathbf{MF}^{c3})
F(c4)=Conv1×1(MFc3) 4)计算:
F
T
S
A
=
F
c
4
+
F
c
3
.
(5)
tag{5} mathbf{F}^{TSA}=mathbf{F}^{c4}+mathbf{F}^{c3}.
FTSA=Fc4+Fc3.(5) 5)MTN的输出由PDC和MTN模块的输出串联构成:
F
‾
=
[
F
(
l
)
]
l
∈
L
∈
T
×
D
,
overline{mathbf{F}}=[mathbf{F}^{(l)}]_{linmathcal{L}}inmathbf{Ttimes D},
F=[F(l)]l∈L∈T×D,其中
L
=
{
PDC
1
,
PDC
2
,
PDC
3
,
TSA
}
mathcal{L}={text{PDC}_1,text{PDC}_2,text{PDC}_3,text{TSA}}
L={PDC1,PDC2,PDC3,TSA};
6)跳跃连接以获取包含原始特征与事件特征的表示:
X
=
s
θ
(
F
)
=
F
‾
+
F
.
mathbf{X}=s_theta(mathbf{F})=overline{mathbf{F}}+mathbf{F}.
X=sθ(F)=F+F.
2.3 特征量级学习
首先提出一个关联
s
θ
(
F
)
s_theta(mathbf{F})
sθ(F)的损失函数
ℓ
s
ell_s
ℓs,其中来自正常视频的最大
k
k
k个特征量级被最小化,而来自异常视频的该特征被最大化:
ℓ
s
(
s
θ
(
F
i
)
,
s
θ
(
F
j
)
,
y
i
,
y
j
)
=
{
max
(
0
,
m
−
d
θ
,
k
(
X
i
,
X
j
)
)
,
y
i
=
1
,
y
j
=
0
0
,
o
t
h
e
r
w
i
s
e
,
(6)
tag{6} ell_s(s_theta(mathbf{F}_i),s_theta(mathbf{F}_j),y_i,y_j)= left{ begin{array}{ll} maxleft(0,m-d_{theta,k}(mathbf{X}_i,mathbf{X}_j)right)&,y_i=1,y_j=0\ 0&,otherwise, end{array} right.
ℓs(sθ(Fi),sθ(Fj),yi,yj)={max(0,m−dθ,k(Xi,Xj))0,yi=1,yj=0,otherwise,(6)其中
m
m
m是预定义间隔、
X
i
=
s
θ
(
F
i
)
,
X
j
mathbf{X}_i=s_theta(mathbf{F}_i),mathbf{X}_j
Xi=sθ(Fi),Xj分别表示异常和正常视频,以及
d
θ
,
k
(
⋅
)
d_{theta,k}(cdot)
dθ,k(⋅)表示可分离性函数。
2.4 RTFM帧级分类器
二元交叉熵损失函数基于
Ω
k
(
X
)
Omega_k(mathbf{X})
Ωk(X)来学习一个帧级分类器:
ℓ
f
(
f
ϕ
(
s
θ
(
F
)
,
y
)
)
=
∑
x
∈
Ω
k
(
X
)
−
(
y
log
(
f
ϕ
(
x
)
)
+
(
1
−
y
)
log
(
1
−
f
ϕ
(
x
)
)
)
,
ell_f(f_phi(s_theta(mathbf{F}),y))=sum_{mathbf{x}inOmega_k(mathbf{X})}-(ylog(f_phi(mathbf{x}))+(1-y)log(1-f_phi(mathbf{x}))),
ℓf(fϕ(sθ(F),y))=x∈Ωk(X)∑−(ylog(fϕ(x))+(1−y)log(1−fϕ(x))),其中
x
=
s
θ
(
f
)
mathbf{x}=s_theta(mathbf{f})
x=sθ(f)。注意
ℓ
f
(
⋅
)
ell_f(cdot)
ℓf(⋅)通过时间平滑 (强制向量帧的异常得分相似)
(
f
ϕ
(
s
θ
(
f
t
)
)
−
f
ϕ
(
s
θ
(
f
t
−
1
)
)
)
(f_phi(s_theta(mathbf{f_t}))-f_phi(s_theta(mathbf{f_{t-1}})))
(fϕ(sθ(ft))−fϕ(sθ(ft−1)))和稀疏正则 (强加一个先验,表明异常事件在每个异常视频中都很少见)
∑
t
=
1
T
∣
f
ϕ
(
s
θ
(
f
t
)
)
∣
sum_{t=1}^T|f_phi(s_theta(mathbf{f_t}))|
t=1∑T∣fϕ(sθ(ft))∣来实现。
3 实验
3.1 数据集和度量标准
四个多场景基准数据集被使用:
1)UCF-Crime是一个大规模异常检测数据集,包含来自真实街道和室内监控摄像头的1900个未修剪视频,总时长为128小时。与ShanghaiTech中的静态背景不同,UCF-Crime的背景更为复杂多样。训练集和测试集包含同样数量的异常和正常视频,其中训练集包含视频级标注,共1610,异常事件共13类;测试集包含帧级标注,共290。
2)XD-Violence是一个近期提出的大规模多场景数据集,收集了现实生活电影、在线视频、体育视频流、监控摄像机,以及CCTV。数据集的总时长为217小时,包含4754 个未修剪视频,训练集具有视频级标签,测试集具有帧级标签。它是目前最大的公开视频异常检测数据集。
3)ShanghaiTech是一个来自固定角度视频监控的中型数据集,包含307个正常视频和130个异常视频。原始数据集是异常检测任务的常用基准,其假设正常训练数据的可用性。Zhong等人通过选择异常测试视频的子集到训练数据中,以重组数据集并构建弱监督训练集,使训练集和测试集覆盖所有13个背景场景。
4)UCSD-Peds是一个包含两个子数据集的小型数据集。Ped1和Ped2分别包含70和28个视频。通过随机选择6个异常视频和4个正常视频到训练集中,重新制定用于弱监督异常检测的数据集,其余的作为测试集。最终展示该过程10 次以上的平均结果。
度量标准:帧级AUC作为所有数据集的衡量标准。XD-Violence额外使用平均精度 (Average precision, AP)。
3.2 实现细节
1)每个视频被划分为32个帧;
2)对于所有的数据集,设置公示6中的
m
=
100
m=100
m=100,
k
=
3
k=3
k=3;
3)三个全连接层FC的节点分别设置为512、128,以及1,其后接ReLU函数,且设置丢弃率为0.7;
4)预训练I3D和C3D的mix_5c和fc_6层分别提取2048维与4096维特征;
5)空洞卷积的空洞率分别设置维1、2,以及4;
6)每个空洞卷积分支使用
3
×
1
3times1
3×1Conv1D;
7)自注意力快使用
1
×
1
1times1
1×1Conv1D;
8)优化方法使用Adam,权重衰减设置为0.0005,批次大小64 (32异常32正常),训练轮次50;
9)ShanghaiTech和UCF-Crime学习率设置为0.001,XD-Violence设置为0.0001;
10)使用Pytorch实现;
11)对比方法的结果使用其与本方法网络骨架一致的发表结果。
最后
以上就是野性金毛最近收集整理的关于论文阅读 (64):Weakly-supervised Video Anomaly Detection with Robust Temporal Feature Magnitude Learning1 引入2 RTFM3 实验的全部内容,更多相关论文阅读内容请搜索靠谱客的其他文章。








发表评论 取消回复