文本生成 (一) --- Seq2Seq理论笔记
- 一 结构
- 二 训练
- 三 解码
- 四 历史
- 五 杂记:
- 六 参考
一 结构
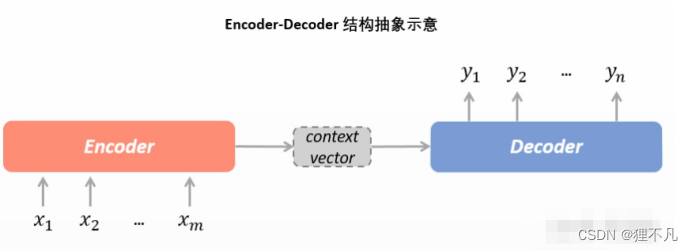
1.seq2seq结构,又称encoder-decoder结构。
二 训练
2.根据标准答案来decode的方式为「teacher forcing」,而根据上一步的输出作为下一步输入的decode方式为「free running」。
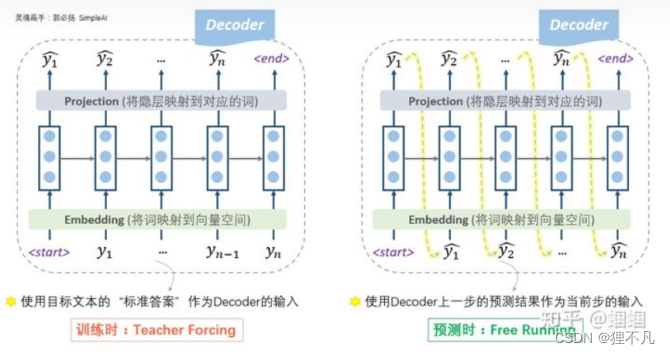
3.teacher forcing,这种操作的目的就是为了使得训练过程更容易。
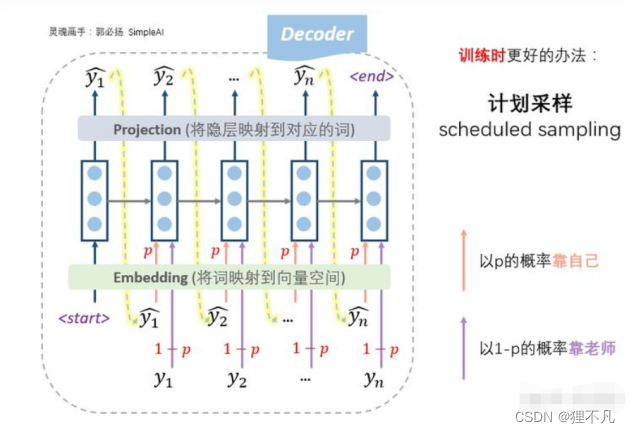
4.「计划采样」(scheduled sampling),我们设置一个概率p,每一步,以概率p靠自己上一步的输入来预测,以概率1-p根据老师的提示来预测
三 解码
5.贪心解码「Greedy Decoding」,即每一步,都预测出概率最大的那个词,然后输入给下一步。但是缺点是,每一步最优不代表全局最优。
6.我们可以使用Beam Search来优化解码

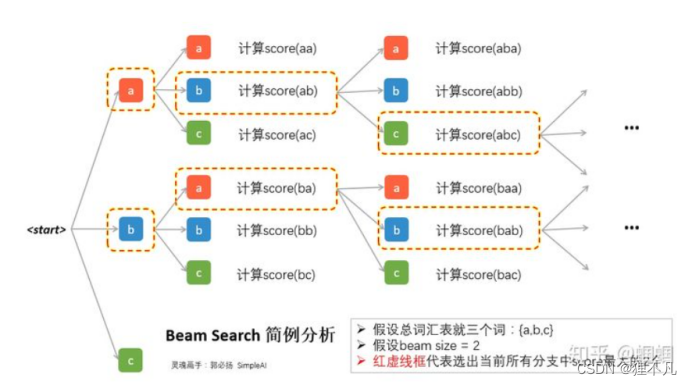
(1)在每一步,我们都会去对所有的可能输出,计算一次score,假设beam size为k,词汇量为V,那么每一步就需要分出k×V个分支并逐一计算score。所以在图中我们可以看到除了第一步,后面每一步都是分出来2×3=6支。然后综合这k×V个score的结果,只选择其中最大的k个保留。
(2)由于会有多个分支,所以很有可能我们会遇到多个标识,由于分支较多,如果等每一个分支都遇到才停的话,可能耗时太久,因此一般我们会设定一些规则,比如已经走了T步,或者已经积累了N条已完成的句子,就终止beam search过程。
(3)在search结束之后,我们需要对已完成的N个序列做一个抉择,挑选出最好的那个,如果直接使用score来挑选的话,会导致那些很短的句子更容易被选出。因为score函数的每一项都是负的,序列越长,score往往就越小。因此我们可以使用长度来对score函数进行细微的调整:对每个序列的得分,除以序列的长度。根据调整后的结果来选择best one。
四 历史
Seq2seq模型多么复杂,最后都是用类似softmax的结构输出概率向量,然后映射到词典中某个词的的index,所以词表中没有的oov是无法被预测的。
2014年NLP界有两份重要的成果,Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation和Sequence to Sequence Learning with Neural Networks。虽然在Decoder的输入上有差别,但结构上两者都将Encoder-Decoder结构应用在翻译场景中,并由此开始,seq2seq框架在机器翻译,对话生成等领域中占据重要位置。另外,前者首次提出GRU结构,后者采用Beam Search改善预测结果,这些都成为如今seq2seq框架的基础技术元素。
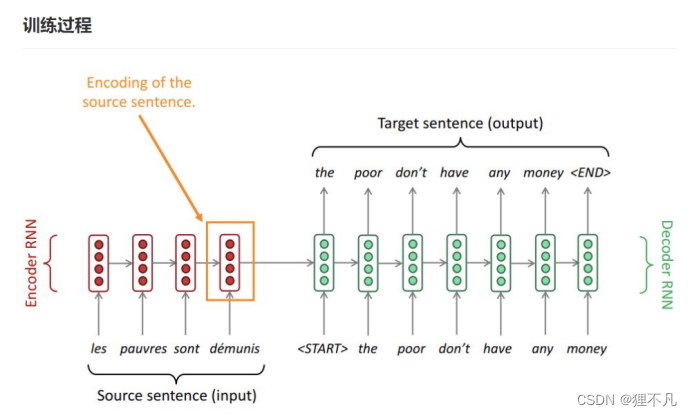
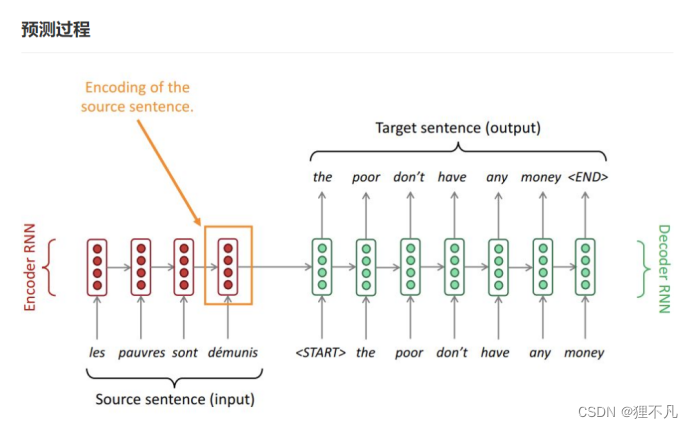
随后,Bahdanau在Neural Machine Translation by Jointly Learning to Align and Translate中提出了融合attention和seq2seq结构的NMT模型结构,至此,由Encoder-Attention-Decoder组成的seq2seq框架正式形成。
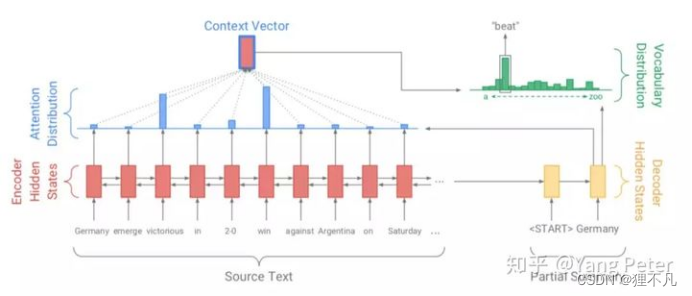
atention-seq2seq如图所示,红色部分为Encoder模块,用于编码输入文本,计算状态值作为黄色的Decoder模块的初始状态;蓝色部分是Attention机制,结合Encoder模块和Decoder输入计算Context向量;最终Decoder部分结合Encoder的输入状态,Context向量,以及Decoder的历史输入,预测当前输出对应于词典的概率分布。
五 杂记:
1.对齐方式alignment,,对应关系有一对一,一对多,多对一,多对多.
2.机器翻译的效果如何评价呢?——「BLEU」指标。
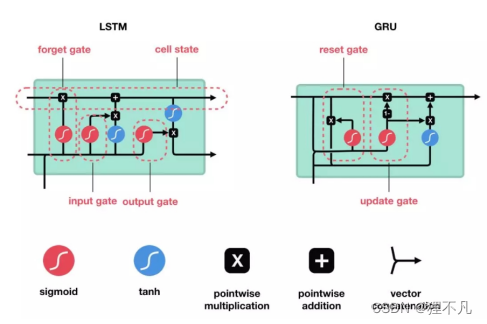
3.RNN,LSTM ,GRU
RNN
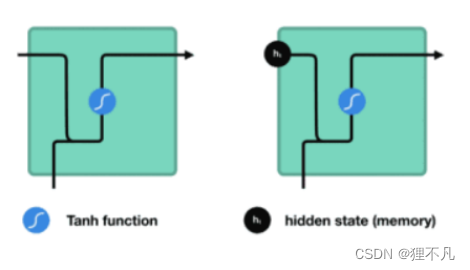
LSTM&GRU
六 参考
【1】https://zhuanlan.zhihu.com/p/71695633 Seq2seq框架下的文本生成
【2】https://zhuanlan.zhihu.com/p/147310766 CS224n笔记[7]:整理了12小时,只为让你20分钟搞懂Seq2seq
【3】https://zhuanlan.zhihu.com/p/359686439 Seq2Seq解码策略-概念
最后
以上就是单身美女最近收集整理的关于文本生成(一)---Seq2Seq理论笔记的全部内容,更多相关文本生成(一)---Seq2Seq理论笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复