1.实验原理
(1)RANSAC算法
采用RANSAC算法寻找一个最佳单应性矩阵H,矩阵大小为3×3。RANSAC目的是找到最优的参数矩阵使得满足该矩阵的数据点个数最多,通常令h33=1来归一化矩阵。由于单应性矩阵有8个未知参数,至少需要8个线性方程求解,对应到点位置信息上,一组点对可以列出两个方程,则至少包含4组匹配点对。
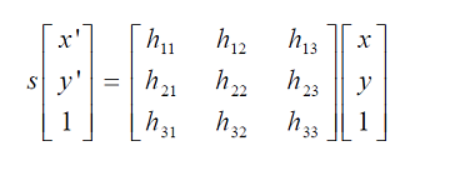
RANSAC算法从匹配数据集中随机抽出4个样本并保证这4个样本之间不共线,计算出单应性矩阵,然后利用这个模型测试所有数据,并计算满足这个模型数据点的个数与投影误差(即代价函数),若此模型为最优模型,则对应的代价函数最小。
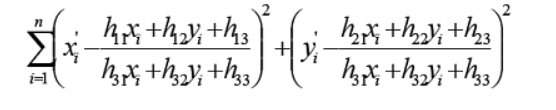
RANSAC算法步骤:
1. 随机从数据集中随机抽出4个样本数据 (此4个样本之间不能共线),计算出变换矩阵H,记为模型M;
2. 计算数据集中所有数据与模型M的投影误差,若误差小于阈值,加入内点集 I ;
3. 如果当前内点集 I 元素个数大于最优内点集 I_best , 则更新 I_best = I,同时更新迭代次数k ;
4. 如果迭代次数大于k,则退出 ; 否则迭代次数加1,并重复上述步骤;
(2)图像配准
图像配准是图像处理研究领域中的一个典型问题和技术难点,其目的在于比较或融合针对同一对象在不同条件下获取的图像,例如图像会来自不同的采集设备,取自不同的时间,不同的拍摄视角等等,有时也需要用到针对不同对象的图像配准问题。具体地说,对于一组图像数据集中的两幅图像,通过寻找一种空间变换把一幅图像映射到另一幅图像,使得两图中对应于空间同一位置的点一一对应起来,从而达到信息融合的目的。 基于特征的匹配方法是图像配准中的一类方法,首先提取图像的特征,再生成特征描述子,最后根据描述子的相似程度对两幅图像的特征之间进行匹配。图像的特征主要可以分为点、线(边缘)、区域(面)等特征,也可以分为局部特征和全局特征。区域(面)特征提取比较麻烦,耗时,因此主要用点特征和边缘特征。
具体可参考https://blog.csdn.net/gaoyu1253401563/article/details/80631601
关于Apap图像配准算法的实现流程:
1.提取两张图片的sift特征点
2.对两张图片的特征点进行粗匹配,再用RANSAC的改进算法进行特征点对的筛选。筛选后的特征点基本能够一一对应。
3.使用DLT算法(直接线性法)将剩下的特征点对进行透视变换矩阵的估计。
4.由于此时得到的透视变换矩阵是基于全局特征点对进行的,通常为了提高精确度,Apap将图像切割成无数多个小方块,对每个小方块的变换矩阵逐一估计。
(3)图像分割
原文:https://imlogm.github.io/图像处理/mincut-maxflow/
关于最小割(min-cut)
如图所示,是一个有向带权图,共有4个顶点和5条边。
最后
以上就是虚心飞机最近收集整理的关于计算机视觉学习 图像全景拼接(基于sift特征)1.实验原理2.实验代码的全部内容,更多相关计算机视觉学习内容请搜索靠谱客的其他文章。


![[OpenGL]从零开始写一个Android平台下的全景视频播放器——5.1 使用OpenGL把全景视频贴到球上](https://www.shuijiaxian.com/files_image/reation/bcimg3.png)





发表评论 取消回复