该博客翻译整理自:https://www.vertica.com/blog/expanding-cluster-new-nodes/
若想对原有的vertica数据库集群扩容(增加一些节点),可以参考以下步骤:
-
备份现有数据库
保险起见,操作前需要对数据进行备份。但是,如果数据库数据量特别巨大呢? -
删除旧的或未使用的表分区
感觉这一步应该放在最前面,以减少备份的数据量。参考命令:
SELECT DROP_PARTITION(table-name, partition value); -
验证是否已禁用本地分段。如果未禁用,请将其禁用。(本地分段顾名思义是将每个节点的数据分段,分段操作将加快数据的移动,这比重新分割投影有效,但是可能会带来一些其他问题,可参考:本地数据分段)
SELECT DISABLE_LOCAL_SEGMENTS(); -
检查集群的网络带宽和CPU性能。参考命令:
$ /opt/vertica/bin/vnetperf
$ /opt/vertica/bin/vcpuperf
扩容前先确保所有节点网络和CPU性能,这样可以确保你快速的完成节点的扩容(特别是数据的重分布操作)。 -
检查是否有足够的存储空间(至少是数据库大小的40%)来执行重新平衡。 要获取每个节点的快照,请查看
HOST_RESOURCES系统表中的以下字段:
SELECT host_name, disk_space_used_mb, disk_space_total_mb disk_space_free_mb FROM host_resources; -
最小化要重新平衡的表上的任何DML操作(最好都给停了),当重新平衡锁定表时,加载失败。如果您的重新平衡可能与ETL作业竞争,请增加配置参数LockTimeout的值。(尽量不要在加载数据时进行扩容等操作)。
ALTER SESSION SET LockTimeout = value;
默认值为300s。 -
使用
update_vertica来向集群中增加节点(如果你安装过vertica,执行这个命令应该不是问题)。使用db_add_node将节点添加到数据库。将节点添加到数据库后,Vertica会自动将更新的配置文件分发到群集中的其余节点,并启动在群集中重新平衡数据的过程。
/opt/vertica/sbin/update_vertica --add-hosts host(s) --rpm package
admintools -t db_add_node -d sampleDB -p 'password' –s node(s) -
监视各个表的重新平衡进度
SELECT table_name, separated_percent, transferred_percent FROM REBALANCE_TABLE_STATUS; -
检查重新平衡是否成功完成
SELECT operation_status FROM REBALANCE_OPERATIONS;
如果operation_status = COMPLETE,则重新平衡完成且没有错误。
至此,扩容成功。
在扩容过程中,最耗时的无疑是数据的重新平衡的过程,特别是当数据量很大时。
参考:数据库重新平衡时会发生什么
数据移动
Vertica在重新平衡期间移动的数据量取决于:
- 您拥有的节点数。
- 要添加的节点数。
- 未分段投影与分段投影的数量。例如,Vertica从伙伴节点复制未分段的投影,因为每个节点都包含数据的完整副本。
下图蓝色矩形表示现有节点,红色矩形表示新节点:
- Vertica将节点插入到群集中最小化数据移动的位置。
- Vertica将数据传输到新节点和现有节点。图中的箭头表示数据传输的方向以及移动的数据百分比。
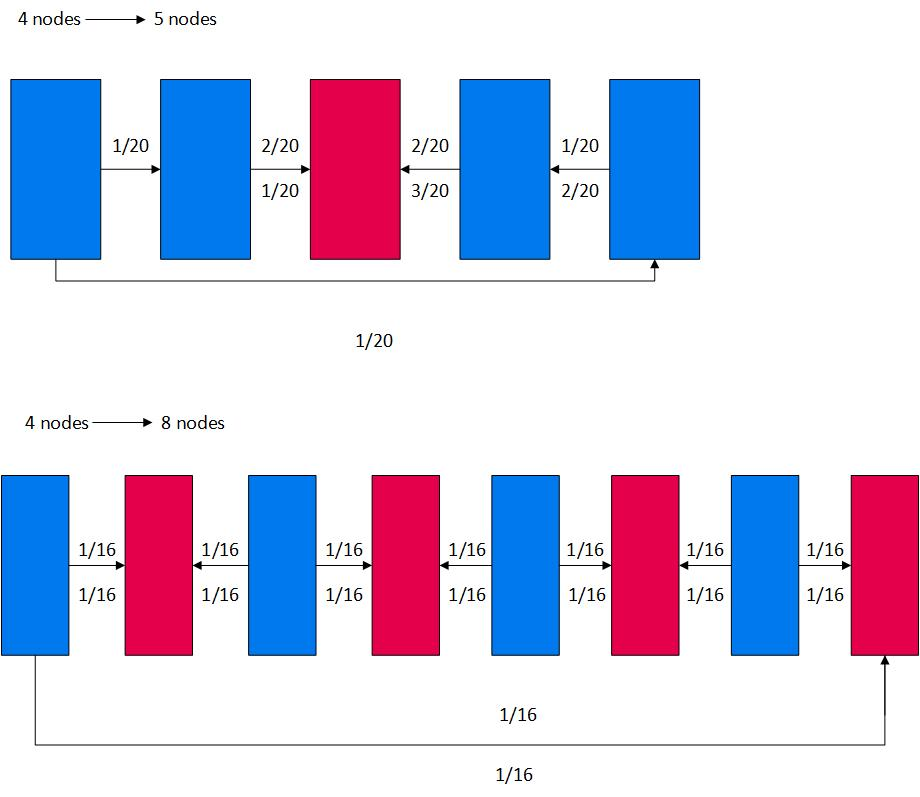
例如,图形的顶行显示向四节点集群添加一个节点。Vertica在最小化数据移动的位置分发新节点。在四节点集群中,每个节点包含1/4的数据。对于五节点集群,每个节点必须包含1/5的数据。当群集从4个节点加倍到8个节点时,道理是相同的。
重新平衡时的资源池使用
重新平衡始终使用内置的REFRESH资源池运行。在此池中,您可以使用PLANNEDCONCURRENCY参数指定Vertica可以随时重新平衡的投影伙伴组的数量。MAXCONCURRENCY池参数对REFRESH资源池没有影响。
建议使用REFRESH资源池的默认设置。
重新平衡的阶段
由于大量数据移动,为了节省磁盘空间,Vertica一次重新平衡一组表和一组投影。组的数量取决于PLANNEDCONCURRENCY配置参数的值。
重新平衡的阶段是:
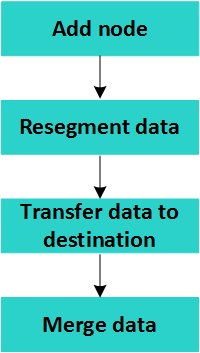
合并数据的最后阶段在重新平衡期间不会发生。Tuple Mover在下次执行合并时合并数据。
添加节点
为了最大限度地缩短在群集节点之间移动数据所需的时间,Vertica会将新节点插入群集中最小化数据移动的位置。新节点的位置会影响重新平衡的性能。对于大型集群尤其如此。
以下是将一个节点添加到三节点集群时的外观:
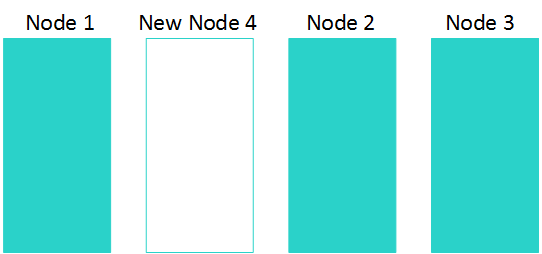
重新分布数据
Vertica从所有节点读取现有数据,并查看每个表和投影。
对于未分段的投影,Vertica:
- 对每个投影进行X锁定。
- 使用以下命令在目标节点上复制这些投影:
CREATE PROJECTION ... UNSEGMENTED ALL NODES KSAFE; - 刷新伙伴投影的投影。
对于分段投影,Vertica:
- 对表进行S锁定,在投影上进行X锁定。
- 将各种类型的投影分隔细分。
- 刷新投影。
分段数据需要暂存区域,因此重新平衡使用临时存储。为了有效地使用该存储,Vertica只重新平衡了一些表和预测。
将节点添加到三节点群集后,重新分布可能如下所示:
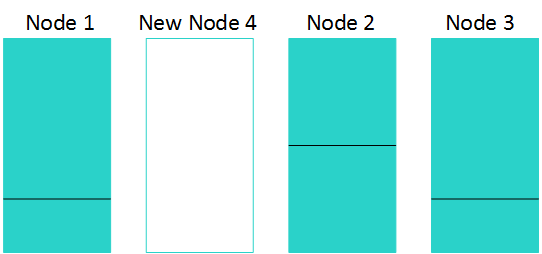
将数据传输到目标节点
为了平衡新的群集,Vertica使用散列函数来确定如何跨新节点和现有节点分发数据。传输数据时,Vertica会进行S锁定并复制未分段和分段的数据。
由于未分段的投影是彼此的副本,因此源节点读取数据,目标节点写入数据。如果您有多个新节点,Vertica可以将多个源节点中的未分段投影并行传输到多个目标节点。这个过程产生很少的CPU开销。
对于分段投影,这些步骤更复杂。在源节点上,Vertica读取,分割和写入分段投影。Vertica需要时间和磁盘空间来执行这些操作。
重新平衡完成后,在目标节点上,最终Tuple Mover合并数据段。
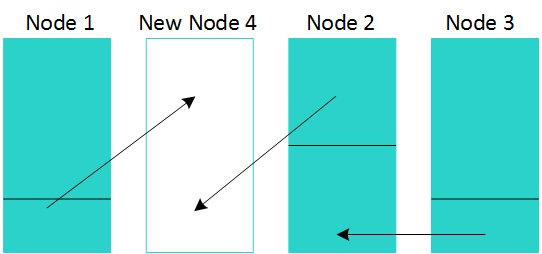
在三节点示例中,您可以看到Vertica使用来自相邻节点的数据填充新节点,以最大限度地减少数据传输量。传输后,数据在所有四个节点之间平衡。
在这个例子中:
- 节点1将数据库中总数据的1/12传输到节点4。
- 节点2将数据库中的总数据的2/12传送到节点4。
- 节点3将数据库中总数据的1/12传输到节点2。
结果是所有节点都具有Vertica数据库中总数据的1/4 。
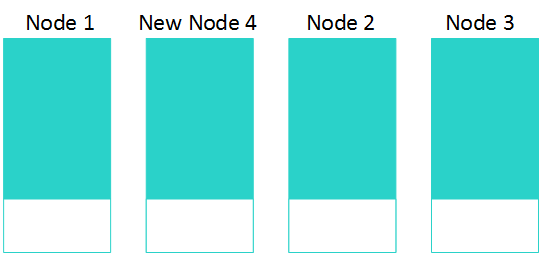
合并数据
重新平衡完成后,在目标节点上,Tuple Mover在下一次合并操作期间合并数据段。
下图说明了添加第四个节点后三节点集群的这种情况。
在Tuple Mover合并数据之后,它会刷新所有投影。如果要删除节点,则在临时节点上,Vertica会删除不需要的未分段投影。
重新平衡需要多长时间?
重新平衡群集可能需要很长时间。以下任何因素都可能影响重新平衡完成所需的时间:
- projections数量。
- 每个表的分区数。
- projection中的数据量和行数。
- 合并目标节点上的数据所花费的时间
- 最繁忙节点的总数据移动(读取和写入)
- 数据倾斜
- 网络吞吐量
- 如果重新平衡过程是I / O绑定或网络绑定
- 群集上的其他工作负载
最后,重新分割分段投影并分离ROS容器可能占总重新平衡时间的80%。
最后
以上就是娇气鸡翅最近收集整理的关于vertica集群增加节点(扩容)的全部内容,更多相关vertica集群增加节点(扩容)内容请搜索靠谱客的其他文章。








发表评论 取消回复