高可用完全分布式模式
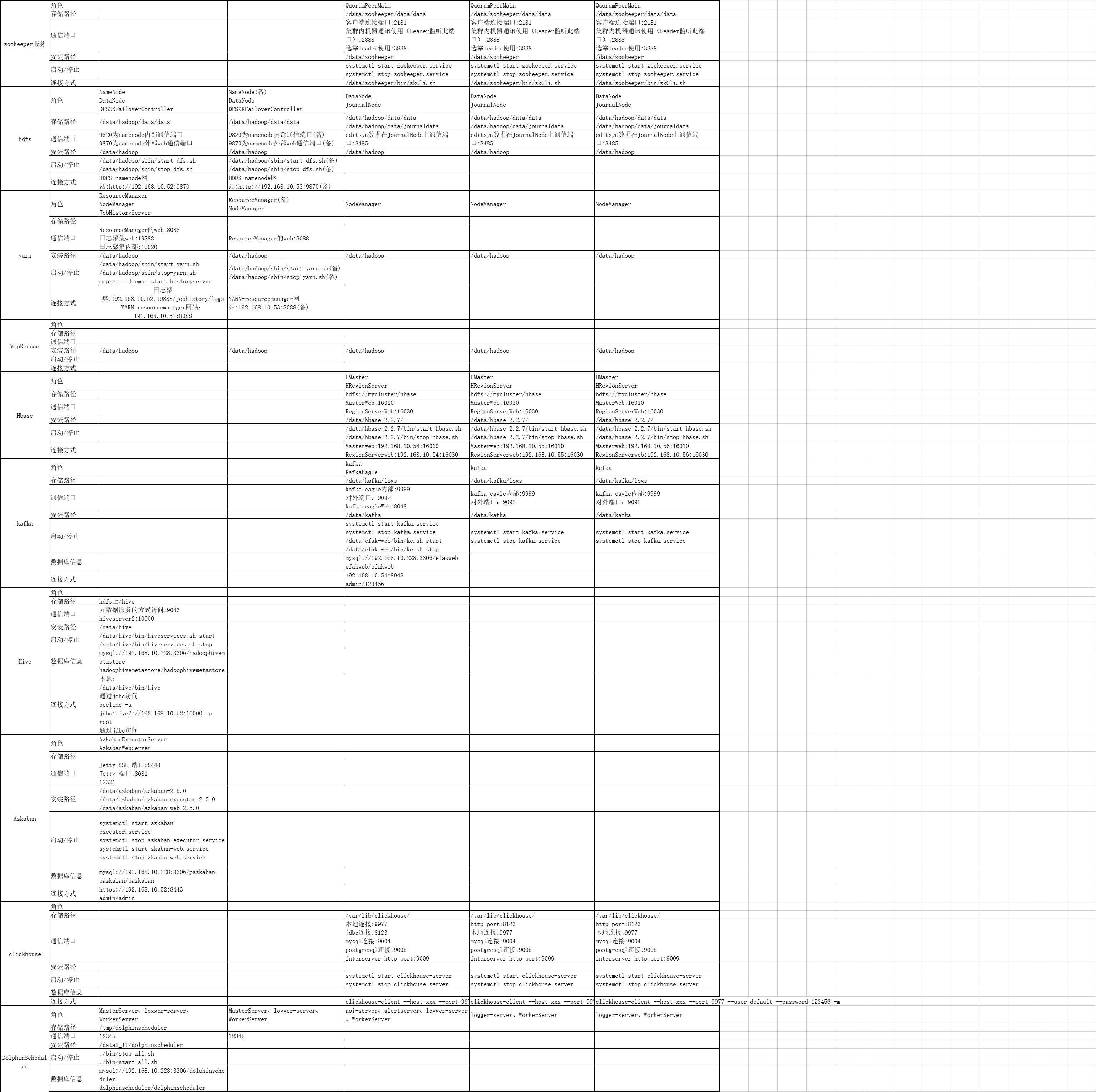
一、部署规划
二、环境准备
-
所有机器禁用seinux,firewalld
-
所有机器相互ping通/etc/hosts
配置主机名解析:vim /etc/hosts 192.168.66.61 hadoop-master1 192.168.66.62 hadoop-master2 192.168.66.65 hadoop-slave1 192.168.66.66 hadoop-slave2 192.168.66.67 hadoop-slave3 -
所有机器配置统一时间
yum -y install chrony systemctl restart chronyd date -
所有机器优化文件打开数
vim /etc/security/limits.conf * soft nofile 655360 * hard nofile 655360 root soft nofile 655360 root hard nofile 655360 * soft core unlimited * hard core unlimited root soft core unlimited -
所有机器优化系统参数
vi /etc/sysctl.conf # see details in https://help.aliyun.com/knowledge_detail/39428.html # see details in https://help.aliyun.com/knowledge_detail/41334.html #仅在内存不足的情况下--当剩余空闲内存低于vm.min_free_kbytes limit时,使用交换空间。 vm.swappiness = 0 #单个进程可分配的最大文件数 fs.nr_open=2097152 #系统最大文件句柄数 fs.file-max=1048576 #backlog 设置 net.core.somaxconn=32768 net.ipv4.tcp_max_syn_backlog=16384 net.core.netdev_max_backlog=16384 #TCP Socket 读写 Buffer 设置 net.core.rmem_default=262144 net.core.wmem_default=262144 net.core.rmem_max=16777216 net.core.wmem_max=16777216 net.core.optmem_max=16777216 net.ipv4.neigh.default.gc_stale_time=120 #TIME-WAIT Socket 最大数量、回收与重用设置 net.ipv4.tcp_max_tw_buckets=1048576 net.ipv4.tcp_tw_reuse=1 net.ipv4.tcp_tw_recycle=1 #TCP 连接追踪设置 net.nf_conntrack_max=1000000 net.netfilter.nf_conntrack_max=1000000 net.netfilter.nf_conntrack_tcp_timeout_time_wait=30 # FIN-WAIT-2 Socket 超时设置 net.ipv4.tcp_fin_timeout=15 net.ipv4.ip_forward = 1 sysctl -p -
所有机器卸载安装自带jdk,安装jdk
for i in 52 53 54 55 56; do scp jdk-8u212-linux-x64.tar.gz root@192.168.10.$i:/data/; done tar -xvf jdk-8u212-linux-x64.tar.gz -C /opt/ vim /etc/profile.d/my_env.sh #添加JAVA_HOME export JAVA_HOME=/opt/jdk1.8.0_212 export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/ export PATH=$PATH:$JAVA_HOME/bin source /etc/profile 检测:java -version -
master机器相互配置远程密钥
#第一次登陆不需要输入yes vim /etc/ssh/ssh_config Host * GSSAPIAuthentication yes StrictHostKeyChecking no systemctl restart sshd#master其中一台,SSH信任 ssh-keygen for i in 25 26 27 28; do ssh-copy-id 192.168.66.$i; done #公钥私钥考给其它master for i in 其它masterIp; do scp -r -p /root/.ssh/* 192.168.66.$i:/root/.ssh/; done (操作节点上)编写配置分发脚本 -
创建hadoop用户,hadoopgroup组所有机器
#创建用户组 groupadd hadoop #创建用户 useradd -g hadoop hadoop #给用户设置密码 echo hadoop | passwd --stdin hadoop #配置 atguigu 用户具有 root 权限,方便后期加 #sudo 执行 root 权限的命令 vim /etc/sudoers ## Allow root to run any commands anywhere root ALL=(ALL) ALL ## Allows people in group wheel to run all commands %wheel ALL=(ALL) ALL atguigu ALL=(ALL) NOPASSWD:ALL chown atguigu:atguigu /opt/module
三、各各组件安装
1、安装zookeeper:分布式协助服务
#默认3节点开始、安装在3台node节点
-
所有zookeeper节点机器安装
for i in 54 55 56; do scp apache-zookeeper-3.6.3-bin.tar.gz root@192.168.10.$i:/data/; done tar -xvf /data/apache-zookeeper-3.6.3-bin.tar.gz -C /data/ mv /data/apache-zookeeper-3.6.3-bin/ /data/zookeeper -
所有zookeeper节点机器添加环境变量
vim /etc/profile.d/my_env.sh #添加ZK_HOME export ZK_HOME=/data/zookeeper export PATH=$PATH:$ZK_HOME/bin source /etc/profile -
所有zookeeper节点机器修改配置文件
cd /data/zookeeper/conf/ cp -p zoo_sample.cfg zoo.cfg vim zoo.cfg # 响应毫秒数 tickTime=2000 # 初始同步需要的连接数 initLimit=10 #传输同步需要的连接数 syncLimit=5 #存储快照的目录 dataDir=/data/zookeeper/data/data/ #客户端将连接的端口 clientPort=2181 #客户端连接数 #maxClientCnxns=60 #保留在dataDir中的快照数 #autopurge.snapRetainCount=3 #清除任务间隔h,设置为“0”可禁用自动清除功能 #autopurge.purgeInterval=1 #最后添加 server.1=1节点主机ip:2888:3888 server.2=2节点主机ip:2888:3888 server.3=3节点主机ip:2888:3888vim /data/zookeeper/bin/zkEnv.sh #首行增加 JAVA_HOME=/opt/jdk1.8.0_212 创建存储文件夹 mkdir -p /data/zookeeper/data/data #创建 myid 文件,id 必须与配置文件里主机名对应的server.(id)一致 1节点主机上执行 echo 1 > /data/zookeeper/data/data/myid 2节点主机上执行 echo 2 > /data/zookeeper/data/data/myid 3节点主机上执行 echo 3 > /data/zookeeper/data/data/myid -
所有zookeeper节点机器启动服务
命令单独启动
#启动 /data/zookeeper/bin/zkServer.sh start #查看状态 /data/zookeeper/bin/zkServer.sh status #停止 /data/zookeeper/bin/zkServer.sh stop配置启动服务
vim /usr/lib/systemd/system/zookeeper.service [Unit] Description=zookeeper After=network.target ConditionPathExists=/data/zookeeper/conf/zoo.cfg [Service] Type=forking Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/jdk1.8.0_212/bin" ExecStart=/data/zookeeper-3.6.3/bin/zkServer.sh start ExecReload=/data/zookeeper-3.6.3/bin/zkServer.sh restart ExecStop=/data/zookeeper-3.6.3/bin/zkServer.sh stop User=root Group=root [Install] WantedBy=multi-user.target systemctl daemon-reload systemctl start zookeeper.service systemctl status zookeeper.service systemctl enable zookeeper.service -
连接:
/data/zookeeper/bin/zkCli.sh
2、安装hadoop核心服务
官网参数参考:http://hadoop.apache.org/docs/
#目录说明
bin 存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
etc Hadoop的配置文件目录,存放Hadoop的配置文件
lib 存放Hadoop的本地库(对数据进行压缩解压缩功能)
sbin 存放启动或停止Hadoop相关服务的脚本
share 存放Hadoop的依赖jar包、文档、和官方案例
-
所有机器安装包
for i in 52 53 54 55 56; do scp hadoop-3.1.3.tar.gz root@192.168.10.$i:/data/; done tar -xvf /data/hadoop.tar.gz -C /data/ mv /data/hadoop-3.1.3 /data/hadoop -
所有机器添加命令变量
vim /etc/profile.d/my_env.sh #添加HADOOP_HOME export HADOOP_HOME=/data/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOP_HOME/sbin source /etc/profile -
所有机器创建白名单、黑名单,用于防止恶意机器
vim /data/hadoop/etc/hadoop/whitelist 192.168.10.52 192.168.10.53 192.168.10.54 192.168.10.55 192.168.10.56touch /data/hadoop/etc/hadoop/blacklist 机器ip1 机器ip2刷新namenode(第一次需要重启,后面可以动态添加)
hdfs dfsadmin -refreshNodes -
修改配置
所有机器上传并修改变量hadoop-env.sh文件
vim /data/hadoop/etc/hadoop/hadoop-env.sh #jdk安装路径 export JAVA_HOME=/opt/jdk1.8.0_212/ #家目录 export HADOOP_HOME=/data/hadoop ####################################NameNode特定参数 #namenode内存设置namenode最小1G,每增加100W个block,增加1G内存,先可以使用默认的 # export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS - Xmx1024m" ####################################DataNode特定参数 #datanode内存设置,最小4G,副本总数低于400W个block;超过后每增加100W个block,增加1G内存,先使用默认设置 # export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS - Xmx1024m"所有机器hdfs文件配置
所有机器修改核心配置文件core-sitevim /data/hadoop/etc/hadoop/core-site.xml <configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/data/data</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>zookeeper1ip:2181,zookeeper2ip:2181,zookeeper3ip:2181</value> </property> <!-- 开启回收站60分钟,防止误删除文件,回收站地址.Trash/--> <!-- 注意:通过网页和程序删除上直接删除的文件也不会走回收站--> <property> <name>fs.trash.interval</name> <value>60</value> </property> <!--添加hive连接的代理用户root--> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <!-- 配置 HDFS 网页登录使用的静态用户为 root--> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration>创建运行时产生文件的存储目录
mkdir -p /data/hadoop/data/data所有机器配置hdfs文件
vim /data/hadoop/etc/hadoop/hdfs-site.xml <configuration> <!--副本策略,一份文件存储几份--> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- #心跳并发配置数,计算python --> <!-- >>> import math --> <!-- >>> print int(20*math.log(datanode数量)) --> <!-- >>>quit() --> <property> <name>dfs.namenode.handler.count</name> <value>21</value> </property> <!-- 白名单 --> <property> <name>dfs.hosts</name> <value>/data/hadoop/etc/hadoop/whitelist</value> </property> <!-- 黑名单 --> <property> <name>dfs.hosts.exclude</name> <value>/data/hadoop/etc/hadoop/blacklist</value> </property> <!--修改默认文件快大小,默认普通机械硬盘128m,固态硬盘258m,270532608--> <property> <name>dfs.blocksize</name> <value>134217728</value> </property> <!--最小块大小默认1m --> <property> <name>dfs.namenode.fs-limits.min-block-size</name> <value>1048576</value> </property> <!--DN 向 NN 汇报当前解读信息的时间间隔,默认 6 小时--> <property> <name>dfs.blockreport.intervalMsec</name> <value>21600000</value> </property> <!--DN 扫描自己节点块信息列表的时间,默认 6 小时--> <property> <name>dfs.datanode.directoryscan.interval</name> <value>21600s</value> </property> <!--DataNode掉线时监测,每300000毫秒检查,每次3s检查时间--> <property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> </property> <property> <name>dfs.heartbeat.interval</name> <value>3</value> </property> <!--指定hdfs的nameservice为mycluster --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!-- mycluster下面有两个NameNode,分别是nn1,nn2名称固定内置的--> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!-- RPC通信地址,9820为namenode内部通信端口 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>master1namenodeIp:9820</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>master2namenodeIp:9820</value> </property> <!-- web通信地址,9870为hdfs namenode外部通信端口 --> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>master1namenodeIp:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>master2namenodeIp:9870</value> </property> <!-- 指定NameNode的edits元数据在JournalNode上的存放位置基数台 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://slave1JournalNodeIp:8485;slave2JournalNodeIp:8485;slave3JournalNodeIp:8485/mycluster</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/data/hadoop/data/journaldata</value> </property> <!-- 关闭权限检查--> <property> <name>dfs.permissions.enable</name> <value>false</value> </property> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 指定HDFS客户端连接active namenode的java类 --> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制为ssh--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 2nn web 9868 端访问地址(高可用集群不需要)--> <property> <name>dfs.namenode.secondary.http-address</name> <value>master1SeecondarynodeIp:9868</value> </property> <!--默认SecondaryNameNode每隔一小时执行一次CheckPoint(高可用集群不需要)--> <property> <name>dfs.namenode.checkpoint.period</name> <value>3600s</value> </property> <!--默认当操作次数达到 1 百万时,SecondaryNameNode 执行一次CheckPoint,隔60s检查一次(高可用集群不需要)--> <property> <name>dfs.namenode.checkpoint.txns</name> <value>1000000</value> </property> <property> <name>dfs.namenode.checkpoint.check.period</name> <value>60s</value> </property> <!--开启存储异构存储(冷热数据分离)策略--> <property> <name>dfs.storage.policy.enabled</name> <value>true</value> </property> <!--DataNode多个目录,生产无法扩容磁盘空间时,增加磁盘,该项每个服务器不一样--> <!--策略存储每台不一样[SSD]固态、[RAM_DISK]、[DISK]机器--> <property> <name>dfs.datanode.data.dir</name> <value>[SSD]file:///data/hadoop- 3.1.3/hdfsdata/ssd,[RAM_DISK]file:///data/hadoop- 3.1.3/hdfsdata/ram_disk,[DISK]file:///data/hadoop- 3.1.3/hdfsdata/disk</value> </property> </configuration>所有机器创建JournalNode在本地磁盘存放数据的位置
mkdir -p /data/hadoop/data/journaldata所有机器yarn文件配置
配置yarn-sitevim /data/hadoop/etc/hadoop/yarn-site.xml <configuration> <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 开启RM高可用 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定RM的cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-cluster</value> </property> <!-- 指定ResourceManager的名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 指定YARN的ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>ResourceManager1Ip</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>ResourceManager2Ip</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>ResourceManager1Ip:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>ResourceManager2Ip:8088</value> </property> <!--启用自动恢复--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!-- 指定zk集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>zookeeper1Ip:2181,zookeeper2Ip:2181,zookeeper3Ip:2181</value> </property> <!--指定 resourcemanager 的状态信息存储在 zookeeper 集群--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore</value> </property> <!-- 环境变量的继承 3.1版本的一个bug,3.2以后无需开启了--> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://master1IP:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为 7 天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <!--调度器默认容量,中小型架构默认,大型架构使用公平--> <!--1默认--> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property> <!--2公平--> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.FairScheduler</value> </property> <property> <name>yarn.scheduler.fair.allocation.file</name> <value>/opt/module/hadoop-3.1.3/etc/hadoop/fair-scheduler.xml</value> <description>指明公平调度器队列分配配置文件</description> </property> <property> <name>yarn.scheduler.fair.preemption</name> <value>false</value> <description>禁止队列间资源抢占</description> </property> <!--ResourceManager处理调度器请求的线程数量,默认50--> <!--普遍上次分析文件大小/默认文件快大小=几个MapTast,几个ReduceTasj,1个mrAppMaster--> <!--总共个数/NodeManager机器数=每台的线程数*1.5=实际需求线程数(要小于服务器的线程数)--> <property> <name>yarn.resourcemanager.scheduler.client.thread-count</name> <value>50</value> </property> <!--是否让yarn自己检测硬件进行配置,默认false,该节点有很多其他应用程序--> <!--建议手动配置。如果该节点没有其他应用程序,可以采用自动--> <property> <name>yarn.nodemanager.resource.detect-hardware-capabilities</name> <value>false</value> </property> <!--是否将虚拟核数当作CPU核数,默认false,一般集群中很多不同的cpu开启--> <property> <name>yarn.nodemanager.resource.count-logical-processors-as-cores</name> <value>false</value> </property> <!--虚拟核数和物理核数乘数,该参数就应设为2,默认1.0,针对单个节点设置的--> <property> <name>yarn.nodemanager.resource.pcores-vcores-multiplier</name> <value>1.0</value> </property> <!--NodeManager使用内存,默认8G,该参数根据实际--> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> </property> <!--NodeManager使用CPU核数,默认8个--> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>8</value> </property> <!--是否启动一个线程检查每个任务正使用的虚拟内存量--> <!--如果任务超出分配值,则直接将其杀掉,默认是 true--> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>true</value> </property> <!--虚拟内存物理内存比例,默认2.1--> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <!--容器最最小内存,默认1G--> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> </property> <!--容器最最大内存,默认8G,更新实际情况调--> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>8192</value> </property> <!--容器最小CPU核数,默认1个--> <property> <name>yarn.scheduler.minimum-allocation-vcores</name> <value>1</value> </property> <!--容器最大CPU核数,默认4个,更新实际情况调--> <property> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>4</value> </property> <!--任务优先级,在资源紧张时,优先级高的任务将优先获取资源,5个等级--> <property> <name>yarn.cluster.max-application-priority</name> <value>5</value> </property> </configuration> 公平调度配置 fair-scheduler.xml <?xml version="1.0"?> <allocations> <!-- 单个队列中 Application Master 占用资源的最大比例,取值 0-1 ,企业一般配置 0.1 --> <queueMaxAMShareDefault>0.5</queueMaxAMShareDefault> <!-- 单个队列最大资源的默认值 test atguigu default --> <queueMaxResourcesDefault>4096mb,4vcores</queueMaxResourcesDefault> <!-- 增加一个队列 test --> <queue name="test"> <!-- 队列最小资源 --> <minResources>2048mb,2vcores</minResources> <!-- 队列最大资源 --> <maxResources>4096mb,4vcores</maxResources> <!-- 队列中最多同时运行的应用数,默认 50,根据线程数配置 --> <maxRunningApps>4</maxRunningApps> <!-- 队列中 Application Master 占用资源的最大比例 --> <maxAMShare>0.5</maxAMShare> <!-- 该队列资源权重,默认值为 1.0 --> <weight>1.0</weight> <!-- 队列内部的资源分配策略 --> <schedulingPolicy>fair</schedulingPolicy> </queue> <!-- 增加一个队列 atguigu --> <queue name="atguigu" type="parent"> <!-- 队列最小资源 --> <minResources>2048mb,2vcores</minResources> <!-- 队列最大资源 --> <maxResources>4096mb,4vcores</maxResources> <!-- 队列中最多同时运行的应用数,默认 50,根据线程数配置 --> <maxRunningApps>4</maxRunningApps> <!-- 队列中 Application Master 占用资源的最大比例 --> <maxAMShare>0.5</maxAMShare> <!-- 该队列资源权重,默认值为 1.0 --> <weight>1.0</weight> <!-- 队列内部的资源分配策略 --> <schedulingPolicy>fair</schedulingPolicy> </queue> <!-- 任务队列分配策略,可配置多层规则,从第一个规则开始匹配,直到匹配成功 --> <queuePlacementPolicy> <!-- 提交任务时指定队列,如未指定提交队列,则继续匹配下一个规则; false 表示:如果指 定队列不存在,不允许自动创建--> <rule name="specified" create="false"/> <!-- 提交到 root.group.username 队列,若 root.group 不存在,不允许自动创建;若 root.group.user 不存在,允许自动创建 --> <rule name="nestedUserQueue" create="true"> <rule name="primaryGroup" create="false"/> </rule> <!-- 最后一个规则必须为 reject 或者 default。Reject 表示拒绝创建提交失败, default 表示把任务提交到 default 队列 --> <rule name="reject" /> </queuePlacementPolicy> </allocations>所有机器MapReduc文件配置
配置mapred-sitevim /data/hadoop/etc/hadoop/mapred-site.xml <configuration> <!-- 指定MapReduce运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 家目录环境变量赋值 --> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <!--Map阶段并行处理输入数据家目录--> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOP_HOME}</value> </property> <!--Reduce阶段并行处理输入数据家目录--> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <!--指定运行jar包程序的位置 --> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value> </property> <!-- 历史服务器端内部地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>master1IP:10020</value> </property> <!-- 历史服务器 web 端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master1IP:19888</value> </property> <!-- 默认情况下,每个 Task 任务都需要启动一个 JVM 来运行 --> <!--如果 Task 任务计算的数据量很小 --> <!--我们可以让同一个 Job 的多个 Task 运行在一个 JVM 中 --> <!--不必为每个 Task 都开启一个 JVM --> <!-- 开启 uber 模式,默认关闭 --> <property> <name>mapreduce.job.ubertask.enable</name> <value>true</value> </property> <!-- uber 模式中最大的 mapTask 数量,可向下修改 --> <property> <name>mapreduce.job.ubertask.maxmaps</name> <value>9</value> </property> <!-- uber 模式中最大的 reduce 数量,可向下修改 --> <property> <name>mapreduce.job.ubertask.maxreduces</name> <value>1</value> </property> <!-- uber模式最大输入数据量,使用 dfs.blocksize 的值,可向下修改 --> <property> <name>mapreduce.job.ubertask.maxbytes</name> <value></value> </property> <!-- 环形缓冲区大小,默认 100m --> <property> <name>mapreduce.task.io.sort.mb</name> <value>100</value> </property> <!-- 环形缓冲区溢写阈值,默认 0.8 --> <property> <name>mapreduce.map.sort.spill.percent</name> <value>0.80</value> </property> <!-- merge 合并次数,默认 10 个 --> <property> <name>mapreduce.task.io.sort.factor</name> <value>10</value> </property> <!-- maptask 内存,默认 1g; maptask 堆内存大小默认和该值大小一致 mapreduce.map.java.opts --> <property> <name>mapreduce.map.memory.mb</name> <value>-1</value> </property> <!-- matask 的 CPU 核数,默认 1 个 --> <property> <name>mapreduce.map.cpu.vcores</name> <value>1</value> </property> <!-- matask 异常重试次数,默认 4 次 --> <property> <name>mapreduce.map.maxattempts</name> <value>4</value> </property> <!-- 每个 Reduce 去 Map 中拉取数据的并行数。默认值是 5 --> <property> <name>mapreduce.reduce.shuffle.parallelcopies</name> <value>5</value> </property> <!-- Buffer 大小占 Reduce 可用内存的比例,默认值 0.7 --> <property> <name>mapreduce.reduce.shuffle.input.buffer.percent</name> <value>0.70</value> </property> <!-- Buffer 中的数据达到多少比例开始写入磁盘,默认值 0.66。 --> <property> <name>mapreduce.reduce.shuffle.merge.percent</name> <value>0.66</value> </property> <!-- reducetask 内存,默认 1g;reducetask 堆内存大小默认和该值大小一致 mapreduce.reduce.java.opts --> <property> <name>mapreduce.reduce.memory.mb</name> <value>-1</value> </property> <!-- reducetask 的 CPU 核数,默认 1 个 --> <property> <name>mapreduce.reduce.cpu.vcores</name> <value>2</value> </property> <!-- reducetask 失败重试次数,默认 4 次 --> <property> <name>mapreduce.reduce.maxattempts</name> <value>4</value> </property> <!-- 当 MapTask 完成的比例达到该值后才会为 ReduceTask 申请资源。默认是 0.05 --> <property> <name>mapreduce.job.reduce.slowstart.completedmaps</name> <value>0.05</value> </property> <!-- 如果程序在规定的默认 10 分钟内没有读到数据,将强制超时退出 --> <property> <name>mapreduce.task.timeout</name> <value>600000</value> </property> </configuration>配置多队列的容量调度器
vim /data/hadoop/etc/hadoop/capacity-scheduler.xml <configuration> <property> <name>yarn.scheduler.capacity.maximum-applications</name> <value>10000</value> </property> <property> <name>yarn.scheduler.capacity.maximum-am-resource-percent</name> <value>0.1</value> </property> <property> <name>yarn.scheduler.capacity.resource-calculator</name> <value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value> </property> <!--指定多队列,增加hive/flink队列--> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>default,hive,flink</value> </property> <!--default--> <!--降低 default 队列占总内存80%,默认 100%--> <property> <name>yarn.scheduler.capacity.root.default.capacity</name> <value>100</value> </property> <!--降低 default 队列最大资源容量为总资源90%,默认 100%--> <property> <name>yarn.scheduler.capacity.root.default.maximum-capacity</name> <value>100</value> </property> <!--default最多可以使用队列多少资源,1表示所有资源--> <property> <name>yarn.scheduler.capacity.root.default.user-limit-factor</name> <value>1</value> </property> <!--启动default队列--> <property> <name>yarn.scheduler.capacity.root.default.state</name> <value>RUNNING</value> </property> <!--哪些用户有权向default队列提交作业--> <property> <name>yarn.scheduler.capacity.root.default.acl_submit_applications</name> <value>*</value> </property> <!--哪些用户有权操作队列,管理员权限(查看/杀死)--> <property> <name>yarn.scheduler.capacity.root.default.acl_administer_queue</name> <value>*</value> </property> <!--哪些用户有权配置提交任务优先级--> <property> <name>yarn.scheduler.capacity.root.default.acl_application_max_priority</name> <value>*</value> </property> <!--如果application指定了使用时间--> <!--则提交到该队列的application的任务运行的时间,-1无限--> <property> <name>yarn.scheduler.capacity.root.default.maximum-application-lifetime </name> <value>-1</value> </property> <!--如果 application 没指定使用时间--> <!--则用的任务运行的时间,-1无限--> <property> <name>yarn.scheduler.capacity.root.default.default-application-lifetime </name> <value>-1</value> </property> <!--hive--> <!--降低 hive队列占总内存60%,默认 100%--> <property> <name>yarn.scheduler.capacity.root.hive.capacity</name> <value>60</value> </property> <!--降低 hive队列最大资源容量为总资源80%,默认 100%--> <property> <name>yarn.scheduler.capacity.root.hive.maximum-capacity</name> <value>80</value> </property> <!--hive最多可以使用队列多少资源,1表示所有资源,0.0到0.5--> <property> <name>yarn.scheduler.capacity.root.hive.user-limit-factor</name> <value>0.8</value> </property> <!--启动hive队列--> <property> <name>yarn.scheduler.capacity.root.hive.state</name> <value>RUNNING</value> </property> <!--哪些用户有权向hive队列提交作业--> <property> <name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name> <value>*</value> </property> <!--哪些用户有权操作队列,管理员权限(查看/杀死)--> <property> <name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name> <value>*</value> </property> <!--哪些用户有权配置提交任务优先级--> <property> <name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name> <value>*</value> </property> <!--如果application指定了使用时间--> <!--则提交到该队列的application的任务运行的时间,-1无限--> <property> <name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime </name> <value>-1</value> </property> <!--如果 application 没指定使用时间--> <!--则用的任务运行的时间,-1无限--> <property> <name>yarn.scheduler.capacity.root.hive.default-application-lifetime </name> <value>-1</value> </property> <!--flink--> <!--降低 flink队列占总内存50%,默认 100%--> <property> <name>yarn.scheduler.capacity.root.flink.capacity</name> <value>60</value> </property> <!--降低 flink队列最大资源容量为总资源60%,默认 100%--> <property> <name>yarn.scheduler.capacity.root.flink.maximum-capacity</name> <value>80</value> </property> <!--flink最多可以使用队列多少资源,1表示所有资源,0.0到0.5--> <property> <name>yarn.scheduler.capacity.root.flink.user-limit-factor</name> <value>0.8</value> </property> <!--启动flink队列--> <property> <name>yarn.scheduler.capacity.root.flink.state</name> <value>RUNNING</value> </property> <!--哪些用户有权向flink队列提交作业--> <property> <name>yarn.scheduler.capacity.root.flink.acl_submit_applications</name> <value>*</value> </property> <!--哪些用户有权操作队列,管理员权限(查看/杀死)--> <property> <name>yarn.scheduler.capacity.root.flink.acl_administer_queue</name> <value>*</value> </property> <!--哪些用户有权配置提交任务优先级--> <property> <name>yarn.scheduler.capacity.root.flink.acl_application_max_priority</name> <value>*</value> </property> <!--如果application指定了使用时间--> <!--则提交到该队列的application的任务运行的时间,-1无限--> <property> <name>yarn.scheduler.capacity.root.flink.maximum-application-lifetime </name> <value>-1</value> </property> <!--如果 application 没指定使用时间--> <!--则用的任务运行的时间,-1无限--> <property> <name>yarn.scheduler.capacity.root.flink.default-application-lifetime </name> <value>-1</value> </property> <property> <name>yarn.scheduler.capacity.node-locality-delay</name> <value>40</value> </property> <property> <name>yarn.scheduler.capacity.rack-locality-additional-delay</name> <value>-1</value> </property> <property> <name>yarn.scheduler.capacity.queue-mappings</name> <value></value> </property> <property> <name>yarn.scheduler.capacity.queue-mappings-override.enable</name> <value>false</value> </property> <property> <name>yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments</name> <value>1</value> </property> <property> <name>yarn.scheduler.capacity.application.fail-fast</name> <value>false</value> </property> </configuration> -
启动
添加变量
#添加hdfs脚本启动权限变量(所有机器上) vim /data/hadoop/sbin/start-dfs.sh export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_JOURNALNODE_USER=root export HDFS_ZKFC_USER=root export HDFS_DATANODE_SECURE_USER=rootvim /data/hadoop/sbin/stop-dfs.sh export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_JOURNALNODE_USER=root export HDFS_ZKFC_USER=root export HDFS_DATANODE_SECURE_USER=root#添加YARN脚本启动权限变量(所有机器上) vim /data/hadoop/sbin/start-yarn.sh export YARN_RESOURCEMANAGER_USER=root export HADOOP_SECURE_DN_USER=root export YARN_NODEMANAGER_USER=rootvim /data/hadoop/sbin/stop-yarn.sh export YARN_RESOURCEMANAGER_USER=root export HADOOP_SECURE_DN_USER=root export YARN_NODEMANAGER_USER=root格式化第一次启动集群需格式化
#删除data/和logs/,保证在之后新启动的集群id配置都相同 rm -rf /data/hadoop/data/data/* mkdir /data/hadoop/logs rm -rf /data/hadoop/logs/* rm -rf /data/hadoop/data/journaldata/*格式化NameNode,会产生新的集群id,导致NameNodeDataNode的集群id不一致,集群找不到 已往数据。
格式NameNode时——>先删除data数据和log日志——>格式化NameNode#格式化NameNode(slave-journalnode上)由于做了journalnode初始化时需要连接,要单独 先启动 (slave上)hdfs --daemon start journalnode (操作节点上)hdfs namenode -format#格式化ZKFC初始化HA在Zookeeper中状态 (操作节点上)hdfs zkfc -formatZK#在zookeeper集群中可以查看: zkCli.sh [z: localhost:2181(CONNECTED) 4] get -s /hadoop-ha/mycluster cZxid = 0x100000006 ctime = Thu Dec 20 22:29:00 CST 2018 mZxid = 0x100000006 mtime = Thu Dec 20 22:29:00 CST 2018 pZxid = 0x100000006 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 0 numChildren = 0单向一个一个启动
1、启动HDFS:分布式文件系统 启动Namenode(Namenode机器上) 启动 hdfs --daemon start namenode 关闭: hdfs --daemon stop namenode 查看 jps 启动Datanode(Datanode机器上) 启动 hdfs --daemon start datanode 关闭: hdfs --daemon stop datanode 查看 jps 启动secondarynamenode(secondarynamenode机器上) 启动 hdfs --daemon start secondarynamenode 关闭: hdfs --daemon stop secondarynamenode 查看 jps一键启动停止
所有机器配置节点清单(不允许空格) vim /data/hadoop/etc/hadoop/workers 192.168.10.52 192.168.10.53 192.168.10.54 192.168.10.55 192.168.10.56 1、启动HDFS:分布式文件系统 启动(操作机器上) /data/hadoop/sbin/start-dfs.sh 停止(操作机器上) /data/hadoop/sbin/stop-dfs.sh 查看 jps2、启动YARN集群资源管理系统 注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN, 应该在ResouceManager所在的机器上启动YARN 启动(操作机器上) /data/hadoop/sbin/start-yarn.sh 停止(操作机器上) /data/hadoop/sbin/stop-yarn.sh 查看 Jps启动历史服务器 mapred --daemon start historyserver 查看历史服务器是否启动 jps -
网站访问
HDFS-namenode网站:http://192.168.66.61:9870/
YARN-resourcemanager网站:http://192.168.66.61:8088/日志聚集服务器地址:http://master1IP:19888/jobhistory/logs
jobhistory历史服务器 web 端地址:master1:19888
3、安装Hbase分布式列存数据库:(数据存储层)(在slave1,slave2,slave3上)
-
解压(在slave1,slave2,slave3上)
for i in 54 55 56; do scp hbase-2.2.7-bin.tar.gz root@192.168.10.$i:/data/; done tar -zxvf /data/hbase-2.2.7-bin.tar.gz -C /data/ -
添加环境变量(在slave1,slave2,slave3上)
vim /etc/profile.d/my_env.sh #添加HBASE_HOME export HBASE_HOME=/data/hbase-2.2.7 export PATH=$PATH:$HBASE_HOME/bin export PATH=$PATH:$HBASE_HOME/sbin source /etc/profile -
修改配置文件(在slave1,slave2,slave3上)
修改启动变量文件修改内容 vim /data/hbase-2.2.7/conf/hbase-env.sh export JAVA_HOME=/opt/jdk1.8.0_212 export HBASE_MANAGES_ZK=false修改配置文:hbase-site.xml vim /data/hbase-2.2.7/conf/hbase-site.xml <configuration> <!-- 这个目录是region服务器共享的目录,用来持久存储HBase的数据,默认值为:${hbase.tmp.dir}/hbase,如果不修改这个配置,数据将会在集群重启时丢失。 --> <property> <name>hbase.rootdir</name> <!-- hadoop引入JQM负载均衡时,这里配置dfs.nameservices指定的集群逻辑名称 --> <value>hdfs://mycluster/hbase</value> <!-- 指定Hadoop master服务器的写法,hbase监听hdfs默认的端口是9000,这里的配置端口只能写9000 --> <!--<value>hdfs://hadoop.master01:9000/hbase</value>--> </property> <!-- 指定hbase集群为分布式集群 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 指定zookeeper集群,有多个用英文逗号分隔 --> <property> <name>hbase.zookeeper.quorum</name> <value>zookeeper1ip:2181,zookeeper2ip:2181,zookeeper3ip:2181</value> </property> <!-- Zookeeper元数据快照的存储目录(需要和Zookeeper的zoo.cfg 配置文件中的属性一致) --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/data/zookeeper/data/data</value> </property> <!-- 指定HBase Master web页面访问端口,默认端口号16010 --> <property> <name>hbase.master.info.port</name> <value>16010</value> </property> <!-- 指定HBase RegionServer web页面访问端口,默认端口号16030 --> <property> <name>hbase.regionserver.info.port</name> <value>16030</value> </property> <!-- 解决启动HMaster无法初始化WAL的问题 --> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> </configuration> -
拷贝接hadoop配置文件到hbase(在slave1,slave2,slave3上)
cp -p /data/hadoop/etc/hadoop/core-site.xml /data/hbase-2.2.7/conf/core-site.xml cp -p /data/hadoop/etc/hadoop/hdfs-site.xml /data/hbase-2.2.7/conf/hdfs-site.xml -
启动
单向启动方式1(在slave1,slave2,slave3上) bin/hbase-daemon.sh start master bin/hbase-daemon.sh start regionserver #提示:如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出 ClockOutOfSyncException异常。 修复提示: a、同步时间服务 b、属性:hbase.master.maxclockskew设置更大的值 <property> <name>hbase.master.maxclockskew</name> <value>180000</value> <description>Time difference of regionserver from master</description> </property>(在slave1,slave2,slave3上)集群启动方式2
启动 /data/hbase-2.2.7/bin/start-hbase.sh 停止 /data/hbase-2.2.7/bin/stop-hbase.sh -
查看HBase页面
HBase Master web
http://hadoop102:16010
HBase RegionServer web
http://hadoop102:16030
4、安装Kafka(数据存储传输层)(在slave1,slave2,slave3上)
-
安装包(在slave1,slave2,slave3上)
for i in 54 55 56; do scp kafka_2.12-2.7.0.tgz root@192.168.10.$i:/data/; done tar -xvf /data/kafka_2.12-2.7.0.tgz -C /data/ mv /data/kafka_2.12-2.7.0 /data/kafka -
添加环境变量(在slave1,slave2,slave3上)
vim /etc/profile.d/my_env.sh #添加KAFKA_HOME export KAFKA_HOME=/data/kafka export PATH=$PATH:$KAFKA_HOME/bin source /etc/profile -
修改配置文件(在slave1,slave2,slave3上)
vim /data/kafka/config/server.properties #代理的id broker.id=主机ip尾号 #日志路径 log.dirs=/data/kafka/logs #zookeeper集群地址 zookeeper.connect=slave1-zookeeperIp:2181,slave2-zookeeperIp:2181,slave3-zookeeperIp:2181 #允许删除topic delete.topic.enable=true -
启动(在slave1,slave2,slave3上)
配置启动服务 vim /usr/lib/systemd/system/kafka.service [Unit] Description=kafka After=network.target [Service] Type=forking Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/jdk1.8.0_212/bin" WorkingDirectory=/data/kafka ExecStart=/data/kafka/bin/kafka-server-start.sh -daemon /data/kafka/config/server.properties ExecStop=/data/kafka/bin/kafka-server-stop.sh -daemon /data/kafka/config/server.properties User=root Group=root [Install] WantedBy=multi-user.target -
修改启动文件(Kafka 监控时需要)
vim /data/kafka/bin/kafka-server-start.sh if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then #export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70" export JMX_PORT="9999" fi systemctl daemon-reload systemctl start kafka.service systemctl status kafka.service systemctl enable kafka.service -
查看角色(在slave1,slave2,slave3上)
jps -
验证(在slave1上操作即可)
#创建一个 topic cd /data/kafka_2.12-2.6.2/ ./bin/kafka-topics.sh --create --partitions 1 --replication-factor 1 --zookeeper slave3:2181 --topic aa #模拟生产者,发布消息 cd /data/kafka_2.12-2.6.2/ ./bin/kafka-console-producer.sh --broker-list slave2:9092 --topic aa #模拟消费者,接收消息 cd /data/kafka_2.12-2.6.2/ ./bin/kafka-console-consumer.sh --bootstrap-server slave1:9092 --topic aa
Kafka 监控安装(随便一个节点安装)
-
解压到本地
tar -zxvf kafka-eagle-bin-2.0.8.tar.gz -C /data/ cd /data/kafka-eagle-bin-2.0.8 tar -xvf efak-web-2.0.8-bin.tar.gz -C /data/ mv /data/efak-web-2.0.8/ /data/efak-web rm -rf /data/kafka-eagle-bin-2.0.8 -
添加环境变量
vim /etc/profile.d/my_env.sh #添加KE_HOME export KE_HOME=/data/efak-web export PATH=$PATH:$KE_HOME/bin source /etc/profile -
修改配置文件
vim /data/efak-web/conf/system-config.properties #监控多套集群 efak.zk.cluster.alias=cluster1,cluster2 cluster1.zk.list=zookeeper1IP:2181,zookeeper2IP:2181,zookeeper3IP:2181 #cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181 #web界面访问端口 efak.webui.port=8048 # kafka offset存储位置 cluster1.efak.offset.storage=kafka #cluster2.efak.offset.storage=zk # kafka图标监控, 15 days by default efak.metrics.charts=true efak.metrics.retain=15 #kafka源数据信息sqlite 存储 #efak.driver=org.sqlite.JDBC #efak.url=jdbc:sqlite:/hadoop/kafka-eagle/db/ke.db #efak.username=root #efak.password=www.kafka-eagle.org # kafka sasl authenticate cluster1.efak.sasl.enable=false cluster1.efak.sasl.protocol=SASL_PLAINTEXT cluster1.efak.sasl.mechanism=SCRAM-SHA-256 cluster1.efak.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka" password="kafka-eagle"; cluster1.efak.sasl.client.id= cluster1.efak.blacklist.topics= cluster1.efak.sasl.cgroup.enable=false cluster1.efak.sasl.cgroup.topics= #cluster2.efak.sasl.enable=false #cluster2.efak.sasl.protocol=SASL_PLAINTEXT #cluster2.efak.sasl.mechanism=PLAIN #cluster2.efak.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="kafka" password="kafka-eagle"; #cluster2.efak.sasl.client.id= #cluster2.efak.blacklist.topics= #cluster2.efak.sasl.cgroup.enable=false #cluster2.efak.sasl.cgroup.topics= # kafka ssl authenticate #cluster3.efak.ssl.enable=false #cluster3.efak.ssl.protocol=SSL #cluster3.efak.ssl.truststore.location= #cluster3.efak.ssl.truststore.password= #cluster3.efak.ssl.keystore.location= #cluster3.efak.ssl.keystore.password= #cluster3.efak.ssl.key.password= #cluster3.efak.ssl.endpoint.identification.algorithm=https #cluster3.efak.blacklist.topics= #cluster3.efak.ssl.cgroup.enable=false #cluster3.efak.ssl.cgroup.topics= #kafka源数据信息mysql存储 efak.driver=com.mysql.cj.jdbc.Driver efak.url=jdbc:mysql://127.0.0.1:3306/efakweb?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull efak.username=efakweb efak.password=efakweb -
启动
/data/efak-web/bin/ke.sh start /data/efak-web/bin/ke.sh stop -
访问
http://192.168.9.102:8048/ke
admin/123456
安装Hive(计算层-离线计算)(在操作机器上)
单节点安装,不需要安装集群,相当于hadoop分析提供的客户端
-
解压包
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /data/ mv /data/apache-hive-3.1.2-bin/ /data/hive -
添加环境变量
vim /etc/profile.d/my_env.sh #HIVE_HOME export HIVE_HOME=/data/hive export PATH=$PATH:$HIVE_HOME/bin source /etc/profile -
解决日志 Jar 包冲突
cd /data/hive/lib/ mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.bak mv guava-19.0.jar guava-19.0.jar.bak cp -p /data/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar . -
Hive 元数据配置到 MySQL
将 MySQL 的 JDBC 驱动拷贝到 Hive 的 lib 目录下
mv mysql-connector-java.jar /data/hive-3.1.2/lib/mysql-connector-java.jar -
修改配置文件
cd /data/hive/conf cp -p hive-env.sh.template hive-env.sh vim hive-env.sh HADOOP_HOME=/data/hadoop export HIVE_CONF_DIR=/data/hive/conf export HIVE_AUX_JARS_PATH=/data/hive/libcp -p hive-default.xml.template hive-site.xml vim /data/hive/conf/hive-site.xml <configuration> <!-- jdbc 连接的 URL --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop102:3306/hadoophivemetastore?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai</value> </property> <!-- jdbc 连接的 Driver--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <!-- jdbc 连接的 username--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hadoophivemetastore</value> </property> <!-- jdbc 连接的 password --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hadoophivemetastore</value> </property> <!-- Hive 元数据存储版本的验证 --> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <!--元数据存储授权--> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <!-- Hive 在 HDFS 的工作目录 --> <property> <name>hive.metastore.warehouse.dir</name> <value>/hive</value> </property> <!-- 使用元数据服务的方式访问 Hive-指定存储元数据要连接的地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://Hive节点ip:9083</value> </property> <!-- 使用 JDBC 方式访问 Hive-指定 hiveserver2 连接的 host --> <property> <name>hive.server2.thrift.bind.host</name> <value>Hive节点ip</value> </property> <!-- 指定 hiveserver2 连接的端口号 --> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <!--使用客户端连接时显示打印当前库和表头 --> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> <!-- 开启动态分区功能--> <property> <name>hive.exec.dynamic.partition</name> <value>true</value> </property> <!--设置为非严格模式,默认 strict,表示必须指定至少一个分区为静态分区--> <!--nonstrict 模式表示允许所有的分区字段都可以使用动态分区--> <property> <name>hive.exec.dynamic.partition.mode</name> <value>strict</value> </property> <!--在所有执行 MR 的节点上,最大一共可以创建多少个动态分区。默认 1000--> <property> <name>hive.exec.max.dynamic.partitions</name> <value>1000</value> </property> <!--在每个执行 MR 的节点上,最大可以创建多少个动态分区--> <property> <name>hive.exec.max.dynamic.partitions.pernode</name> <value>100</value> </property> <!--整个 MR Job 中,最大可以创建多少个 HDFS 文件。默认 100000--> <property> <name>hive.exec.max.created.files</name> <value>100000</value> </property> <!--当有空分区生成时,是否抛出异常--> <property> <name>hive.error.on.empty.partition</name> <value>false</value> <!--more,在全局查找、字段查找、limit 查找等都不走mapreduce--> </property> <property> <name>hive.fetch.task.conversion</name> <value>more</value> </property> <!--小表大表 Join(MapJOIN)--> <!--设置自动选择 Mapjoin--> <property> <name>hive.auto.convert.join</name> <value>true</value> </property> <!--大表小表的阈值设置(默认 25M 以下认为是小表)--> <property> <name>hive.mapjoin.smalltable.filesize</name> <value>25000000</value> </property> <!--Map 端聚合参数--> <!--在 Map 端进行聚合--> <property> <name>hive.map.aggr</name> <value>true</value> </property> <!--在 Map 端进行聚合操作的条目数目--> <property> <name>hive.groupby.mapaggr.checkinterval</name> <value>100000</value> </property> <!--有数据倾斜的时候进行负载均衡--> <property> <name>hive.groupby.skewindata</name> <value>true</value> </property> <!--开启本地 mapreduce,一般集群中先不配置--> <property> <name>hive.exec.mode.local.auto</name> <value>true</value> </property> <!--设置本地 mapreduce的最大输入数据量,当输入数据量小于这个值时采用的方式--> <property> <name>hive.exec.mode.local.auto.inputbytes.max</name> <value>50000000</value> </property> <!--设置本地 mapreduce输入文件个数,输入文件小于时采用本地 mapreduce的方式--> <property> <name>hive.exec.mode.local.auto.input.files.max</name> <value>10</value> </property> </configuration> mkdir /data/hive/data -
修改运行日志配置文件
cd /data/hive/conf/ mv hive-log4j2.properties.template hive-log4j2.properties vim /data/hive/conf/hive-log4j2.properties #添加 hive.log.dir=/data/hive/logs mkdir /data/hive/logs -
数据库上新建 Hive 元数据库
CREATE USER 'hadoophivemetastore'@'%' IDENTIFIED BY 'hadoophivemetastore'; CREATE DATABASE `hadoophivemetastore`CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; GRANT ALL PRIVILEGES ON hadoophivemetastore.* TO 'hadoophivemetastore'@'%'; -
初始化 Hive 元数据库
schematool -initSchema -dbType mysql -verbose -
启动
#前台metastore程序启动(元数据服务的方式) /data/hive/bin/hive --service metastore #前台hiveserver2程序启动(使用 JDBC 方式访问) /data/hive/bin/hive --service hiveserver2后台程序启动脚本 vim /data/hive/bin/hiveservices.sh #!/bin/bash #检查日志目录是否存在,不存在就创建 HIVE_LOG_DIR=/data/hive/shlogs if [ ! -d $HIVE_LOG_DIR ] then mkdir -p $HIVE_LOG_DIR fi #启动服务 function hive_start() { nohup /data/hive/bin/hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 & nohup /data/hive/bin/hive --service hiveserver2 >$HIVE_LOG_DIR/metastore.log 2>&1 & } #停止服务 function hive_stop() { for metastoreid in `ps -ef | grep metastore | awk '{print $2}'` do kill -9 $metastoreid done for hiveserver2id in `ps -ef | grep hiveserver2 | awk '{print $2}'` do kill -9 $hiveserver2id done } #运行状态 function hive_status() { pidmetastoreNum=`ps -ef | grep metastore | awk '{print $2}' | wc -l` pidhiveserver2Num=`ps -ef | grep hiveserver2 | awk '{print $2}' | wc -l` if [ $pidmetastoreNum -ge 3 ]; then echo metastore正在运行 else echo metastore未在运行 fi if [ $pidhiveserver2Num -ge 2 ]; then echo hiveserver2正在运行 else echo hiveserver2未在运行 fi } case $1 in start) hive_start;; stop) hive_stop;; restart) hive_stop sleep 10 hive_start;; status) hive_status;; *) echo Invalid Args! echo 'Usage: '$(basename $0)' start|stop|restart|status' esac添加执行权限 chmod +x /data/hive/bin/hiveservices.sh启动 Hive 后台服务 /data/hive/bin/hiveservices.sh start -
客户端访问
本地启动一个客户端并进入Hive客户端
/data/hive/bin/hive通过jdbc访问
服务端:hiveserver2
客户端:beeline
启动 beeline 客户端(需要多等待一会)
beeline -u jdbc:hive2://(hiveserver2地址):10000 -n 随便一个用户名
Azkaban工作流调度系统-定时多重任务(任务调度层)
-
解压并创建目录(操作机器节点)
mkdir /data/azkaban tar -zxvf azkaban-web-server-2.5.0.tar.gz -C /data/azkaban/ tar -zxvf azkaban-executor-server-2.5.0.tar.gz -C /data/azkaban/ tar -zxvf azkaban-sql-script-2.5.0.tar.gz -C /data/azkaban/ -
创建数据库(数据库节点)
建用户: CREATE USER 'pazkaban'@'%' IDENTIFIED BY 'pazkaban'; 新建库: CREATE DATABASE `pazkaban`CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; 用户授权: GRANT ALL PRIVILEGES ON pazkaban.* TO 'pazkaban'@'%'; 导入数据 mysql> use pazkaban; mysql> source /data/azkaban-2.5.0/create-all-sql-2.5.0.sql -
生成密钥对和证书(操作机器节点)
生成 keystore 的密码及相应信息的密钥库 mkdir /data/azkaban/keytool cd /data/azkaban/keytool keytool -keystore keystore -alias jetty -genkey -keyalg RSA 输入密钥库口令: 123456 再次输入新口令: 123456 您的名字与姓氏是什么? [Unknown]: 您的组织单位名称是什么? [Unknown]: 您的组织名称是什么? [Unknown]: 您所在的城市或区域名称是什么? [Unknown]: 您所在的省/市/自治区名称是什么? [Unknown]: 该单位的双字母国家/地区代码是什么? [Unknown]: CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown 是否 正确? [否]: y 输入 <jetty> 的密钥口令 (如果和密钥库口令相同, 按回车): -
修改配置文件(操作机器节点)
Web 服务器配置 vim /data/azkaban/azkaban-web-2.5.0/conf/azkaban.properties #Azkaban Personalization Settings #服务器 UI 名称,用于服务器上方显示的名字 azkaban.name=Test #描述 azkaban.label=My Local Azkaban #UI 颜色 azkaban.color=#FF3601 azkaban.default.servlet.path=/index #默认 web server 存放 web 文件的目录 web.resource.dir=/data/azkaban/azkaban-web-2.5.0/web/ #默认时区,已改为亚洲/上海 默认为美国 default.timezone.id=Asia/Shanghai #Azkaban UserManager class user.manager.class=azkaban.user.XmlUserManager #用户权限管理默认类(绝对路径) user.manager.xml.file=/data/azkaban/azkaban-web-2.5.0/conf/azkaban-users.xml #Loader for projects #global 配置文件所在位置(绝对路径) executor.global.properties=/data/azkaban/azkaban-executor-2.5.0/conf/global.properties azkaban.project.dir=projects #数据库类型 database.type=mysql #端口号 mysql.port=3306 #数据库连接 IP mysql.host=192.168.10.228 #数据库实例名 mysql.database=pazkaban #数据库用户名 mysql.user=pazkaban #数据库密码 mysql.password=pazkaban #最大连接数 mysql.numconnections=100 # Velocity dev mode velocity.dev.mode=false # Azkaban Jetty server properties. # Jetty 服务器属性. #最大线程数 jetty.maxThreads=25 #Jetty SSL 端口 jetty.ssl.port=8443 #Jetty 端口 jetty.port=8081 #SSL 文件名(绝对路径) jetty.keystore=/data/azkaban/keytool/keystore #SSL 文件密码 jetty.password=123456 #Jetty 主密码与 keystore 文件相同 jetty.keypassword=123456 #SSL 文件名(绝对路径) jetty.truststore=/data/azkaban/keytool/keystore #SSL 文件密码 jetty.trustpassword=123456 # Azkaban Executor settings executor.port=12321 # mail settings mail.sender= mail.host= job.failure.email= job.success.email= lockdown.create.projects=false cache.directory=cacheweb 服务器用户配置 vim /data/azkaban/azkaban-web-2.5.0/conf/azkaban-users.xml <azkaban-users> <user username="azkaban" password="azkaban" roles="admin" groups="azkaban" /> <user username="metrics" password="metrics" roles="metrics"/> <user username="admin" password="admin" roles="admin,metrics"/> <role name="admin" permissions="ADMIN" /> <role name="metrics" permissions="METRICS"/> </azkaban-users>执行服务器配置 vim /data/azkaban/azkaban-executor-2.5.0/conf/azkaban.properties #Azkaban #时区 default.timezone.id=Asia/Shanghai # Azkaban JobTypes Plugins #jobtype 插件所在位置 azkaban.jobtype.plugin.dir=plugins/jobtypes #Loader for projects executor.global.properties=/data/azkaban/azkaban-executor-2.5.0/conf/global.properties azkaban.project.dir=projects database.type=mysql mysql.port=3306 mysql.host=192.168.10.228 mysql.database=pazkaban mysql.user=pazkaban mysql.password=pazkaban mysql.numconnections=100 # Azkaban Executor settings #最大线程数 executor.maxThreads=50 #端口号(如修改,请与 web 服务中一致) executor.port=12321 #线程数 executor.flow.threads=30 -
启动
启动 Executor 服务器
添加mysql驱动 cd /data/azkaban/azkaban-executor-2.5.0/lib mv mysql-connector-java-5.1.28.jar mysql-connector-java-5.1.28.jar.bak 添加mysql8驱动 vim /usr/lib/systemd/system/azkaban-executor.service [Unit] Description=zkaban-executor After=network.target [Service] Type=forking Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/jdk1.8.0_212/bin" ExecStart=/data/azkaban/azkaban-executor-2.5.0/bin/azkaban-executor-start.sh ExecStop=/data/azkaban/azkaban-executor-2.5.0/bin/azkaban-executor-shutdown.sh User=root Group=root [Install] WantedBy=multi-user.target systemctl daemon-reload systemctl start azkaban-executor.service systemctl status azkaban-executor.service systemctl enable azkaban-executor.service启动 Web 服务器
添加mysql驱动 cd /data/azkaban/azkaban-web-2.5.0/lib/ mv mysql-connector-java-5.1.28.jar mysql-connector-java-5.1.28.jar.bak 添加mysql8驱动 vim /usr/lib/systemd/system/zkaban-web.service [Unit] Description=zkaban-web After=network.target [Service] Type=forking Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/jdk1.8.0_212/bin" ExecStart=/data/azkaban/azkaban-web-2.5.0/bin/azkaban-web-start.sh ExecStop=/data/azkaban/azkaban-web-2.5.0/bin/azkaban-web-shutdown.sh User=root Group=root [Install] WantedBy=multi-user.target systemctl daemon-reload systemctl start zkaban-web.service systemctl status zkaban-web.service systemctl enable zkaban-web.service -
查看进程
jps AzkabanExecutorServer AzkabanWebServer -
访问
https://192.168.10.52:8443
admin/admin
DolphinScheduler(工作流任务调度系统,升级版)(在操作节点进行)
-
解压并创建目录
tar -xvf apache-dolphinscheduler-2.0.0-bin.gz -C /data/ mv /data/apache-dolphinscheduler-2.0.0-bin /data/apache-dolphinscheduler-install cd /data/apache-dolphinscheduler-install -
创建用户
useradd dolphinscheduler echo "dolphinscheduler" | passwd --stdin dolphinscheduler vim /etc/sudoers #Defaults requirett #最后添加 dolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL chown -R dolphinscheduler:dolphinscheduler /data/apache-dolphinscheduler-install 创建传输密钥 su dolphinscheduler ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 600 ~/.ssh/authorized_keys -
初始化数据库(数据库节点)
建用户: CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler'; 新建库: CREATE DATABASE `dolphinscheduler`CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; 用户授权: GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%'; 导入数据 mysql> source sql/dolphinscheduler_mysql.sql; mysql> flush privileges; -
修改配置文件
mysql 驱动程序放入 /data/apache-dolphinscheduler-install/lib/mysql-connector-java.jar vim conf/datasource.properties spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://xx:3306/dolphinscheduler?characterEncoding=UTF-8&allowMultiQueries=true spring.datasource.username=dolphinscheduler spring.datasource.password=dolphinscheduler vim conf/config/install_config.conf #装调度的机器hostname列表,如果是伪分布式,则只需写一个伪分布式hostname即可 ips="1ip,2ip,3ip,4ip,5ip" #SSHPort sshPort="22" #部署master的机器hostname列表 masters="1ip,2ip" #部署worker的机器hostname列表 workers="1ip:default,2ip:default,3ip:default,4ip:default,5ip:default" #部署alert server的机器hostname列表 alertServer="1ip" #部署api server的机器hostname列表 apiServers="1ip,2ip" #安装路径 installPath="/data/dolphinscheduler" #使用用户 deployUser="dolphinscheduler" #数据路径 dataBasedirPath="/data/dolphinscheduler/dolphinschedulerdata" #环境变量 javaHome="/opt/jdk1.8.0_212" #apiServerPort apiServerPort="12345" #数据库信息 dbtype="mysql" dbhost="172.31.115.17:3306" username="dolphinscheduler" password="dolphinscheduler" dbname="dolphinscheduler" # Registry Server registryPluginDir="lib/plugin/registry/zookeeper" #zookeeper信息 registryPluginName="zookeeper" # Registry Server address. registryServers="172.31.115.17:2181,172.31.115.18:2181,172.31.115.19:2181" #服务跟 zkRoot="/dolphinscheduler" # Alert Server alertPluginDir="lib/plugin/alert" # Worker Task Server taskPluginDir="lib/plugin/task" #资源存储类型: HDFS, S3, NONE resourceStorageType="NONE" # HDFS/S3时的路径 resourceUploadPath="/dolphinscheduler" #resourceStorageType=HDFS时信息 defaultFS="hdfs://hdp0.fengjian.com:8020" #resourceStorageType=S3时信息 s3Endpoint="http://192.168.xx.xx:9010" s3AccessKey="xxxxxxxxxx" s3SecretKey="xxxxxxxxxx" #resourcemanagerPort resourceManagerHttpAddressPort="8088" #hdfs用户 hdfsRootUser="hdfs" #是否使用sudo sudoEnable="true" #工作租户自动创建 workerTenantAutoCreate="true"环境变量
vim conf/env/dolphinscheduler_env.sh export HADOOP_HOME=/data/hadoop export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop #export SPARK_HOME1=/opt/soft/spark1 #export SPARK_HOME2=/opt/soft/spark2 #export PYTHON_HOME=/opt/soft/python export JAVA_HOME=/opt/jdk1.8.0_212 #export HIVE_HOME=/opt/soft/hive #export FLINK_HOME=/opt/soft/flink #export DATAX_HOME=/opt/soft/datax export PATH=$HADOOP_HOME/bin:$JAVA_HOME/bin #export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$PATH修改jvm 堆栈参数,根据需求修改
vim bin/dolphinscheduler-daemon.sh配置安装分发
/install.sh -
启动
一键启停止集群所有服务 ./bin/stop-all.sh ./bin/start-all.sh 启停 Master ./bin/dolphinscheduler-daemon.sh stop master-server ./bin/dolphinscheduler-daemon.sh start master-server 启停 Worker ./bin/dolphinscheduler-daemon.sh start worker-server ./bin/dolphinscheduler-daemon.sh stop worker-server 启停 Api ./bin/dolphinscheduler-daemon.sh start api-server ./bin/dolphinscheduler-daemon.sh stop api-server 启停 Logger ./bin/dolphinscheduler-daemon.sh start logger-server ./bin/dolphinscheduler-daemon.sh stop logger-server 启停 Alert ./bin/dolphinscheduler-daemon.sh start alert-server ./bin/dolphinscheduler-daemon.sh stop alert-server -
访问
http://xxx:12345/dolphinscheduler
admin/dolphinscheduler123
flume安装(安装在需要采集的业务机器上)
-
解压
tar -xvf apache-flume-1.9.0-bin.tar.gz -C /data/ mv apache-flume-1.9.0-bin flume -
添加环境变量
vim /etc/profile.d/my_env.sh #添加FLUME_HOME export FLUME_HOME=/data/flume export PATH=$PATH:$FLUME_HOME/bin source /etc/profile.d/my_env.sh -
修改Flume配置文件
cd /data/flume/conf mv flume-env.sh.template flume-env.sh 修改环境变量 vi flume-env.sh # 修改内容如下 export JAVA_HOME=/opt/jdk1.8.0_212修改日志文件 vi log4j.properties # 修改内容如下 flume.log.dir=/data/flume/logs mkdir /data/flume/logs -
Ganglia监控Flume工具
定义
Ganglia由gmond、gmetad和gweb三部分组成
gmond(Ganglia Monitoring Daemon)
种轻量级服务,安装在每台需要收集指标数据的节点主机上。使用gmond,你可以很容易 收集很多系统指标数据,如CPU、内存、磁盘、网络和活跃进程的数据等
gmetad(Ganglia Meta Daemon)
gmetad整合所有信息,并将其以RRD格式存储至磁盘的服务
gweb(Ganglia Web)
可视化工具,gweb是一种利用浏览器显示gmetad所存储数据的PHP前端。在Web界面中 以图表方式展现集群的运行状态下收集的多种不同指标数据安装其他依赖
yum -y install httpd php rrdtool perl-rrdtool rrdtool-devel apr-devel epel-release安装ganglia
yum -y install ganglia-gmetad yum -y install ganglia-web yum install -y ganglia-gmond修改配置文件
vim /etc/httpd/conf.d/ganglia.conf # Ganglia monitoring system php web frontend Alias /ganglia /usr/share/ganglia <Location /ganglia> Order deny,allow Deny from all Allow from all # Allow from 127.0.0.1 # Allow from ::1 # Allow from .example.com </Location>修改数据源
vim /etc/ganglia/gmetad.conf data_source "cxkcluster" 监控的机器ip1 监控的机器ip2 vim /etc/ganglia/gmond.conf cluster { name = "cxkcluster" owner = "unspecified" latlong = "unspecified" url = "unspecified" } udp_send_channel { #bind_hostname = yes # Highly recommended, soon to be default. # This option tells gmond to use a source address # that resolves to the machine's hostname. Without # this, the metrics may appear to come from any # interface and the DNS names associated with # those IPs will be used to create the RRDs. # mcast_join = 239.2.11.71 host = server主机ip port = 8649 ttl = 1 } udp_recv_channel { # mcast_join = 239.2.11.71 port = 8649 bind = 节点ip retry_bind = true # Size of the UDP buffer. If you are handling lots of metrics you really # should bump it up to e.g. 10MB or even higher. # buffer = 10485760 }启动ganglia
systemctl httpd start
systemctl gmetad start
systemctl gmond start打开网页浏览ganglia页面
http://192.168.1.102/ganglia
#如果完成以上操作依然出现权限不足错误,请修改/var/lib/ganglia目录的权限:
chmod -R 777 /var/lib/gangliaGanglia监控视图


案例
配置参考文档
https://flume.liyifeng.org/#flume-sources
Exec source适用于监控一个实时追加的文件,不能实现断电续传;
Spooldir Source适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步; Taildir Source适合用于监听多个实时追加的文件,并且能够实现断点续传。
-
Flume案例-监听数据端口
1、安装常用通信软件 yum install -y nc net-tools 2、新增配置并启动flume-agent mkdir -p /data/flume/job vim /data/flume/job/flume-netcat-logger.conf # example.conf: 一个单节点的 Flume 实例配置 # 配置Agent a1各个组件的名称 #Agent a1 的source有一个,叫做r1 a1.sources = r1 #Agent a1 的sink也有一个,叫做k1 a1.sinks = k1 #Agent a1 的channel有一个,叫做c1 a1.channels = c1 # 配置Agent a1的source r1的属性 #使用的是NetCat TCP Source,这里配的是别名,Flume内置的一些组件都是有别名的,没有别名填全限定类名 a1.sources.r1.type = netcat #NetCat TCP Source监听的hostname,这个是本机 a1.sources.r1.bind = localhost #监听的端口 a1.sources.r1.port = 44444 # 配置Agent a1的sink k1的属性 # sink使用的是Logger Sink,这个配的也是别名 a1.sinks.k1.type = logger # 配置Agent a1的channel c1的属性,channel是用来缓冲Event数据的 #channel的类型是内存channel,顾名思义这个channel是使用内存来缓冲数据 a1.channels.c1.type = memory #内存channel的容量大小是1000,注意这个容量不是越大越好,配置越大一旦Flume挂掉丢失的event也就越多 a1.channels.c1.capacity = 1000 #source和sink从内存channel每次事务传输的event数量 a1.channels.c1.transactionCapacity = 100 # 把source和sink绑定到channel上 #与source r1绑定的channel有一个,叫做c1 a1.sources.r1.channels = c1 #与sink k1绑定的channel有一个,叫做c1 a1.sinks.k1.channel = c1 3、启动 /data/flume/bin/flume-ng agent --conf /data/flume/conf/ --name a1 --conf-file /data/flume/job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console #--name给 agent 起名为 a1 #将控制台日志打印级别设置为 INFO 级别。日志级别包括:log、info、warn、error 4、开启另一个终端,发送消息 nc localhost 4444 aaa -
Flume案例-实时监控单个追加文件
实时监控 Hive 日志,并上传到 HDFS 中 1、要想将数据输出到HDFS,必须持有Hadoop相关jar包 拷贝jar包至/data/flume/lib hadoop-3.1.3/share/hadoop/common/lib/commons-configuration2-2.1.1.jar hadoop-3.1.3/share/hadoop/common/lib/hadoop-auth-3.1.3.jar hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar hadoop-3.1.3/share/hadoop/common/lib/commons-io-2.5.jar hadoop-3.1.3/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar hadoop-3.1.3/share/hadoop/hdfs/hadoop-hdfs-3.1.3.jar 2、新增配置并启动flume-agent vim /data/flume/job/flume-file-hdfs.conf # example.conf: 一个单节点的 Flume 实例配置 # 配置Agent a1各个组件的名称 #Agent a2 的source有一个,叫做r2 a2.sources = r2 #Agent a2的sink也有一个,叫做k2 a2.sinks = k2 #Agent a2 的channel有一个,叫做c2 a2.channels = c2 # 配置Agent a2的source r2的属性 #定义source类型为exec可执行命令的 a2.sources.r2.type = exec #执行命令 a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log #执行shell脚本的绝对路径 a2.sources.r2.shell = /bin/bash -c # 配置Agent a2的sink k2的属性 # sink使用的是Logger Sink,这个配的也是别名 a2.sinks.k2.type = hdfs a2.sinks.k2.hdfs.path = hdfs://hadoop102:9000/flume/%Y%m%d/%H #上传文件的前缀 a2.sinks.k2.hdfs.filePrefix = logs- #是否按照时间滚动文件夹 a2.sinks.k2.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k2.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k2.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k2.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a2.sinks.k2.hdfs.batchSize = 1000 #设置文件类型,可支持压缩 a2.sinks.k2.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k2.hdfs.rollInterval = 30 #设置每个文件的滚动大小 a2.sinks.k2.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a2.sinks.k2.hdfs.rollCount = 0 # sink的kafka配置 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.bootstrap.servers = Kafka1ip:9092,Kafka2ip:9092,Kafka3ip:9092 a1.sinks.k1.kafka.topic = first a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 1 # 配置Agent a2的channel c2的属性,channel是用来缓冲Event数据的 #channel的类型是内存channel,顾名思义这个channel是使用内存来缓冲数据 a2.channels.c2.type = memory #内存channel的容量大小是1000,注意这个容量不是越大越好,配置越大一旦Flume挂掉丢失的event也就越多 a2.channels.c2.capacity = 1000 #source和sink从内存channel每次事务传输的event数量 a2.channels.c2.transactionCapacity = 100 # 把source和sink绑定到channel上 #与source r2绑定的channel有一个,叫做c2 a2.sources.r2.channels = c2 #与sink k2绑定的channel有一个,叫做c2 a2.sinks.k2.channel = c2 3、启动flume-agent /data/flume/bin/flume-ng agent --conf /data/flume/conf/ --name a1 --conf-file /data/flume/job/flume-file-hdfs.conf -
Flume案例-实时监控目录下多个新文件
1、要想将数据输出到HDFS,必须持有Hadoop相关jar包 拷贝jar包至/data/flume/lib hadoop-3.1.3/share/hadoop/common/lib/commons-configuration2-2.1.1.jar hadoop-3.1.3/share/hadoop/common/lib/hadoop-auth-3.1.3.jar hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar hadoop-3.1.3/share/hadoop/common/lib/commons-io-2.5.jar hadoop-3.1.3/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar hadoop-3.1.3/share/hadoop/hdfs/hadoop-hdfs-3.1.3.jar 2、创建flume-dir-hdfs.conf文件 vim /data/flume/job/flume-dir-hdfs.conf #定义source a3.sources = r3 #定义sink a3.sinks = k3 #定义channel a3.channels = c3 #定义source类型为目录 a3.sources.r3.type = spooldir #定义source类型为目录 a3.sources.r3.spoolDir = /opt/module/flume/upload #定义文件上传完,后缀 a3.sources.r3.fileSuffix = .COMPLETED #是否有文件头 a3.sources.r3.fileHeader = true #忽略所有以.tmp 结尾的文件,不上传 a3.sources.r3.ignorePattern = ([^ ]*.tmp) #sink类型为hdfs a3.sinks.k3.type = hdfs #文件上传到hdfs的路径 a3.sinks.k3.hdfs.path = hdfs://hadoop102:9000/flume/upload/%Y%m%d/%H #上传文件的前缀 a3.sinks.k3.hdfs.filePrefix = upload- #是否按照时间滚动文件夹 a3.sinks.k3.hdfs.round = true #多少时间单位创建一个新的文件夹 a3.sinks.k3.hdfs.roundValue = 1 #重新定义时间单位 a3.sinks.k3.hdfs.roundUnit = hour #是否使用本地时间戳 a3.sinks.k3.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a3.sinks.k3.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a3.sinks.k3.hdfs.fileType = DataStream #多久生成一个新的文件 a3.sinks.k3.hdfs.rollInterval = 60 #设置每个文件的滚动大小大概是 128M a3.sinks.k3.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a3.sinks.k3.hdfs.rollCount = 0 a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3 3、启动flume-agent cd /data/flume bin/flume-ng agent -n a3 -c conf/ -f job/flume-dir-hdfs.conf -
Flume案例-实时监控目录下的多个追加文件,断点续传
1、要想将数据输出到HDFS,必须持有Hadoop相关jar包 拷贝jar包至/data/flume/lib hadoop-3.1.3/share/hadoop/common/lib/commons-configuration2-2.1.1.jar hadoop-3.1.3/share/hadoop/common/lib/hadoop-auth-3.1.3.jar hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar hadoop-3.1.3/share/hadoop/common/lib/commons-io-2.5.jar hadoop-3.1.3/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar hadoop-3.1.3/share/hadoop/hdfs/hadoop-hdfs-3.1.3.jar 2、创建flume-dir-hdfs.conf文件 vim /data/flume/job/flume-taildir-hdfs.conf #定义source a3.sources = r3 #定义sink a3.sinks = k3 #定义channel a3.channels = c3 #定义source类型 a3.sources.r3.type = TAILDIR0 #指定position_file位置,再次恢复文件时从哪里恢复 a3.sources.r3.positionFile = /data/flume/tail_dir.json #定义监控目录文件 a3.sources.r3.filegroups = f1 f2 a3.sources.r3.filegroups.f1 = /data/flume/files/.*file.* a3.sources.r3.filegroups.f2 = /data/flume/files/.*log.* # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://hadoop102:9000/flume/upload2/%Y%m%d/%H #上传文件的前缀 a3.sinks.k3.hdfs.filePrefix = upload- #是否按照时间滚动文件夹 a3.sinks.k3.hdfs.round = true #多少时间单位创建一个新的文件夹 a3.sinks.k3.hdfs.roundValue = 1 #重新定义时间单位 a3.sinks.k3.hdfs.roundUnit = hour #是否使用本地时间戳 a3.sinks.k3.hdfs.useLocalTimeStamp = true #积攒多少个Event才flush到HDFS一次 a3.sinks.k3.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a3.sinks.k3.hdfs.fileType = DataStream #多久生成一个新的文件 a3.sinks.k3.hdfs.rollInterval = 60 #设置每个文件的滚动大小大概是128M a3.sinks.k3.hdfs.rollSize = 134217700 #文件的滚动与Event数量无关 a3.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3 3、创建目录和文件 cd /data/flume mkdir files cp CHANGELOG files/CHANGELOG.log cp LICENSE files/LICENSE.log 4、启动flume-agent cd /data/flume bin/flume-ng agent -n a3 -c conf/ -f job/flume-taildir-hdfs.conf -
Flume的企业开发实例
1、复制和多路复用 需求:使用 Flume-1 监控文件变动,Flume-1 将变动内容传递给 Flume-2,Flume-2 负 责存储到 HDFS。同时 Flume-1 将变动内容传递给 Flume-3,Flume-3 负责输出到 Local FileSystem。 单数据源多出口案例(选择器) 1、Agent a1创建flume-file-flume.conf文件 vim /data/flume/job/flume-file-flume.conf # 配置Agent a1各个组件的名称 #Agent a1 的source有一个,叫做r1 a1.sources = r1 #Agent a1 的sink也有2个,叫做k1,k2 a1.sinks = k1 k2 #Agent a1 的channel有2个,叫做c1,c2 a1.channels = c1 c2 # 将数据流复制给所有 channel,副本策略 a1.sources.r1.selector.type = replicating #组件监控文件变动 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log a1.sources.r1.shell = /bin/bash -c a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # sink 端的 avro 是一个数据发送者,通过端口传输数据 a1.sinks.k1.type = avro a1.sinks.k1.hostname = 目标ip a1.sinks.k1.port = 传输的端口 a1.sinks.k2.type = avro a1.sinks.k2.hostname = 目标ip a1.sinks.k2.port = 传输的端口 a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2 2、Agent a2创建flume-flume-hdfs.conf文件 vim /data/flume/job/flume-flume-hdfs.conf a2.sources = r1 a2.sinks = k1 a2.channels = c1 # source 端的 avro 是一个数据接收服务 a2.sources.r1.type = avro a2.sources.r1.bind = 本机ip a2.sources.r1.port = 传输端口 a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://hadoop102:9000/flume2/%Y%m%d/%H #上传文件的前缀 a2.sinks.k1.hdfs.filePrefix = flume2- #是否按照时间滚动文件夹 a2.sinks.k1.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k1.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k1.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a2.sinks.k1.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a2.sinks.k1.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k1.hdfs.rollInterval = 600 #设置每个文件的滚动大小大概是 128M a2.sinks.k1.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a2.sinks.k1.hdfs.rollCount = 0 a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 3、Agent a3创建flume-flume-dir.conf文件 vim /data/flume/job/flume-flume-dir.conf a3.sources = r1 a3.sinks = k1 a3.channels = c2 a3.sources.r1.type = avro a3.sources.r1.bind = 本机ip a3.sources.r1.port = 传输端口 a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 a3.sinks.k1.type = file_roll a3.sinks.k1.sink.directory = /opt/module/data/flume3 a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2 启动 bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group1/flume-flume-dir.conf bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group1/flume-flume-hdfs.conf bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group1/flume-file-flume.conf2故障转移、负载均衡 需求:使用 Flume1 监控一个端口,其 sink 组中的 sink 分别对接 Flume2 和 Flume3,采用 FailoverSinkProcessor,实现故障转移的功能。 1、Agent a1创建flume-netcat-flume.conf文件 vim /data/flume/job/flume-netcat-flume.conf a1.sources = r1 a1.channels = c1 #1 个 sink group a1.sinkgroups = g1 a1.sinks = k1 k2 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 5 a1.sinkgroups.g1.processor.priority.k2 = 10 a1.sinkgroups.g1.processor.maxpenalty = 10000 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sinks.k1.type = avro a1.sinks.k1.hostname = 目标ip a1.sinks.k1.port = 使用端口 a1.sinks.k2.type = avro a1.sinks.k2.hostname = 目标ip a1.sinks.k2.port = 使用端口 a1.sources.r1.channels = c1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1 2、Agent a2创建flume-flume-console1.conf文件 vim /data/flume/job/flume-flume-console1.conf a2.sources = r1 a2.sinks = k1 a2.channels = c1 a2.sources.r1.type = avro a2.sources.r1.bind = 本机ip a2.sources.r1.port = 使用端口 a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 a2.sinks.k1.type = logger a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 3、Agent a3创建flume-flume-console2.conf文件 vim /data/flume/job/flume-flume-console2.conf a3.sources = r1 a3.sinks = k1 a3.channels = c2 a3.sources.r1.type = avro a3.sources.r1.bind = 本机ip a3.sources.r1.port = 使用端口 a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 a3.sinks.k1.type = logger a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2 启动 bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group2/flume-flume-console2.conf -Dflume.root.logger=INFO,console bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group2/flume-flume-console1.conf -Dflume.root.logger=INFO,console bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group2/flume-netcat-flume.conf3、聚合 需求:hadoop102 上的 Flume-1 监控文件/opt/module/data/group.log, hadoop103 上的 Flume-2 监控某一个端口的数据流, Flume-1 与 Flume-2 将数据发送给 hadoop104 上的 Flume-3,Flume-3 将最终数据打印到控 制台。 1、Agent a1创建flume1-logger-flume.conf文件 vim /data/flume/job/flume1-logger-flume.conf a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/group.log a1.sources.r1.shell = /bin/bash -c a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sinks.k1.type = avro a1.sinks.k1.hostname = 目标ip a1.sinks.k1.port = 传输端口 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 2、Agent a2创建flume2-netcat-flume.conf文件 vim /data/flume/job/flume2-netcat-flume.conf a2.sources = r1 a2.sinks = k1 a2.channels = c1 a2.sources.r1.type = netcat a2.sources.r1.bind = 本机ip a2.sources.r1.port = 使用端口 a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 a2.sinks.k1.type = avro a2.sinks.k1.hostname = 目标ip a2.sinks.k1.port = 传输端口 a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 3、Agent a3创建flume3-flume-logger.conf文件 vim /data/flume/job/flume3-flume-logger.conf a3.sources = r1 a3.sinks = k1 a3.channels = c1 a3.sources.r1.type = avro a3.sources.r1.bind = 本机ip a3.sources.r1.port = 传输端口 a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 a3.sinks.k1.type = logger a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1 启动 bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group3/flume3-flume-logger.conf -Dflume.root.logger=INFO,console bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group3/flume1-logger-flume.conf bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group3/flume2-netcat-flume.conf
Sqoop:数据同步工具(数据传输层-结构化文件)(安装在需要采集的业务机器上)
单节点安装,不需要安装集群,相当于hadoop分析提供的客户端
-
安装
tar -xvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /data/ mv /data/sqoop-1.4.7.bin__hadoop-2.6.0 /data/sqoop-1.4.7 -
添加环境变量
vim /etc/profile.d/my_env.sh #SQOOP_HOME export SQOOP_HOME=/data/sqoop-1.4.7 export PATH=$PATH:$SQOOP_HOME/bin source /etc/profile -
修改配置文件
cd /data/sqoop-1.4.7/conf mv sqoop-env-template.sh sqoop-env.sh vim sqoop-env.sh export HADOOP_COMMON_HOME=/data/hadoop-2.7.2 export HADOOP_MAPRED_HOME=/data/hadoop-2.7.2 export HIVE_HOME=/data/hive export ZOOKEEPER_HOME=/data/zookeeper-3.4.10 export ZOOCFGDIR=/data/zookeeper-3.4.10 export HBASE_HOME=/data/hbase -
拷贝JDBC驱动
cp mysql-connector-java.jar /data/sqoop-1.4.7/lib/ -
验证Sqoop
#通过某一个command来验证sqoop配置是否正确: sqoop help #测试Sqoop是否能够成功连接数据库 sqoop list-databases --connect jdbc:mysql://hadoop102:3306/ --username root --password 000000 出现如下输出: information_schema metastore mysql oozie performance_schema
ClickHouse列式存储数据库(不依赖hadoop)(3台slave上)
-
安装依赖
yum install -y libtool yum install -y *unixODBC* -
验证CPU是否支持 SSE 4.2 指令集
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported" -
安装软件包
cd clickhouse rpm -ivh *.rpm 密码输入:123456 查看 rpm -qa|grep clickhouse -
修改配置文件
vim /etc/clickhouse-server/config.xml #修改tcp_port为9977,因为这个端口和 HDFS 的冲突了 <tcp_port>9977</tcp_port> #listen_host 表示能监听的主机,:: 表示任意主机都可以访问 <listen_host>::</listen_host> <!-- <listen_host>::1</listen_host> --> <!-- <listen_host>127.0.0.1</listen_host> --> #最大并发处理的请求数(包含 select,insert 等),默认值 100,推荐 150(不够再加)~300 <max_concurrent_queries>150</max_concurrent_queries> #集群修改3分片2副本 <remote_servers> <clickhouse_cluster> <shard> <weight>1</weight> <internal_replication>true</internal_replication> <replica> <host>slave1ip</host> <port>9977</port> <user>default</user> <password>default</password> </replica> <replica> <host>slave2ip</host> <port>9977</port> <user>default</user> <password>default</password> </replica> </shard> <shard> <weight>1</weight> <internal_replication>true</internal_replication> <replica> <host>slave2ip</host> <port>9977</port> <user>default</user> <password>default</password> </replica> <replica> <host>slave3ip</host> <port>9977</port> <user>default</user> <password>default</password> </replica> </shard> <shard> <weight>1</weight> <internal_replication>true</internal_replication> <replica> <host>slave3ip</host> <port>9977</port> <user>default</user> <password>default</password> </replica> <replica> <host>slave1ip</host> <port>9977</port> <user>default</user> <password>default</password> </replica> </shard> </clickhouse_cluster> </remote_servers> #zookeeper配置 <zookeeper> <node> <host>zookeeper1ip</host> <port>2181</port> </node> <node> <host>zookeeper2ip</host> <port>2181</port> </node> <node> <host>zookeeper3ip</host> <port>2181</port> </node> </zookeeper> #数据压缩配置 <compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>zstd</method> </case> </compression> #时区配置 <timezone>Asia/Shanghai</timezone> vim /etc/clickhouse-server/users.xml # Query 占用内存最大值,128G 内存的机器,设置为 100GB <max_memory_usage>10000000000</max_memory_usage> -
启动
systemctl start clickhouse-server systemctl enable clickhouse-server systemctl status clickhouse-server -
验证
clickhouse-client --host=xxx --port=9977 --user=default --password=123456 -m select * from system.clusters;
喜欢的亲可以关注点赞评论哦!以后每天都会更新的哦!本文为小编原创文章; 文章中用到的文件、安装包等可以加小编联系方式获得;
欢迎来交流小编联系方式VX:CXKLittleBrother 进入运维交流群
最后
以上就是搞怪铃铛最近收集整理的关于Hadoop大数据系列组键-部署一、部署规划二、环境准备三、各各组件安装的全部内容,更多相关Hadoop大数据系列组键-部署一、部署规划二、环境准备三、各各组件安装内容请搜索靠谱客的其他文章。








发表评论 取消回复