基于HMM识别的基本原理以及一些HTK工具已经在前面的章节中讲述。本章开始讲述HTK工具的软件体系结构。接下来将会介绍所有HTK工具并结合基于HMM识别器的创建与测试进行说明。为了顾及HTK老用户,HTK最新版本的修改之处会被列出。接下来的章节将依据一个简单连续语音识别系统的构建实例来讲解HTK工具包的使用。
2.1 HTK软件体系结构
HTK的大部分功能被内置到库模块中。这些模块确保每个工具的对外接口方式是一致的。他们还提供常用函数(a central resource of commonly used functions)。图2.1展示了一个典型HTK工具以及它的输入和输出。
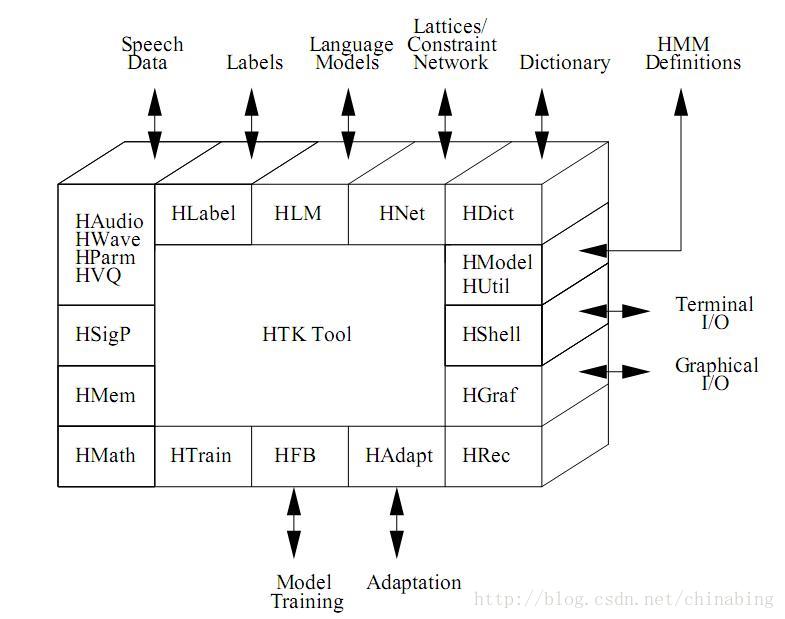
图2.1 软件体系结构
用户的输入输出以及与操作系统的接口是由库模块HSHELL控制,所有的内存管理是由HMEM控制。数学支持是由HMATH提供,语音分析中使用到的信号处理操作由HSIGP支持。HTK中的每种类型的文件对应一个专用的接口模块。HLABEL为label文件提供接口,HLM对应语言模型文件,HNET对应网络和词图文件,HDICT对应词典文件,HVQ对应VQ codebooks,以及HMODEL对应HMM模型文件。
所有的语音输入和输出都是通过HWAVE(waveformlevel)或HPARM(parameterizedlevel)。除了提供一致的接口,HWAVE和HLABEL还支持多种文件格式,并容许数据从其他系统导入。HAUDIO支持直接的音频输入,HGRAF支持简单的交互图形。HUTIL支持一些utility routines,用于操控HMMs,HTRAIN和HFB支持各种HTK训练工具。HADAPT支持各种HTK调整工具。最后,HREC包含主要的识别处理函数。
接下来将讲到,可以通过配置变量对这些库模块进行合理控制和运用。由库模块提供的函数的详细描述将在本书的第二部分进行说明,相关的配置变量也将在具体运用时给出说明。为了查询的需要,第18章给出了完整的列表。
2.2 HTK工具共有的属性
HTK工具被设计运行于传统的命令行界面。每个工具具有一些必选参数和若干可选参数。可选参数以一个减号开头。例如,下面的命令将会执行一个虚构的HTK工具HFOO
HFoo -T 1 -f 34.3 -a -s myfile file1 file2
这个工具有两个主要参数file1、file2以及4个可选参数。可选项参数以一个字母接相应参数值的形式出现。参数值和参数名之间以空格隔开。从而,-f的参数值是一个实数,-T的参数值是一个整数,-s的参数值是一个字符串。-a后面没有参数值,用作简单的标记来标识工具的某个特性的开关。例如,-T选项总是用来控制HTK工具的跟踪输出。
除了命令行参数,工具的操作可以通过配置文件中的参数来控制。例如,
HFoo -C config -f 34.3 -a -s myfile file1 file2
工具HFOO将会在初始化过程中载入存储在config文件中的参数。多个配置文件可以通过多个-C来载入,例如
HFoo -C config1-C config2 -f 34.3 -a -s myfile file1 file2
配置参数有时可以代替命令行参数。例如,跟踪选项可以设置于配置文件中。然而,配置文件的主要用处是用于控制库模块的详细行为。
尽管命令行工作方式看上去有些过时,特别是和现代的图像化界面相比。但它有很多优点,它能够很方便地以shell脚本控制HTK工具执行。这一点对于大规模系统的构建和实验至关重要的。而且,使用文本的方式来定义所有操作可以将实验结果记录保存。
最后,所有HTK工具的详细说明可以在命令行控制台中通过不带参数的命令来查看。
2.3 工具包
通过构建一个基于sub-word的连续语音识别器的处理步骤来介绍HTK工具的使用。如图2.2所示,总共有四个阶段: 数据预处理,训练,测试和分析。
2.3.1 数据预处理工具
构建HMM模型需要语音数据集和与之相对应的标注文件。在训练之前,要将语音数据和标注转换成指定的格式。HSLAB可以用于采集语音数据并且进行手动标注。尽管HTK工具可以随时参数化波形文件,实际应用中,最好进行一次参数化。HCopy工具就是用于文件参数化的工具,可以通过设定配置参数,将一个或多个文件进行编码(译者注: 例如提取MFCC特征)。HLIST用于检验语音文件的内容,检验文件的内容是否正确有效。在训练之前,标注文件需要做相应处理(译者注: 比如根据不同词典将词级标注转换为音素级标注),用到HLED工具。HMM训练时需要上下文相关的标注。HLED可以将输入文件转换为mlf文件,便于后续处理。HLSTATS可以获得标注文本的统计信息,HQUANT可以构建VQ codebook, 为构建离散概率HMM系统作准备。
2.3.2 训练工具
系统构建的第二步是为每个HMM模型定义拓扑原型。HMM模型可以存储于普通文本文件中,这样便于编辑。拓扑原型是用于表示模型的结构和参数形式。(译者注: 一般情况设置成标准正态分布,或者选择一批数据计算均值和方差,状态转移概率设为相等)。接下来的步骤会在原型的基础之上训练新的参数。
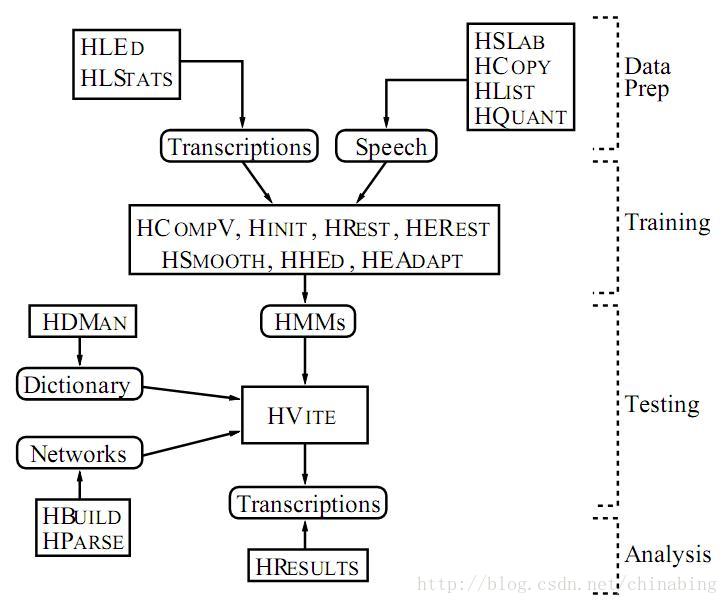
图2.2 HTK处理流程
当存在fully labelled bootstrap data, 即精确标注的数据(phone级),可以通过HINIT和HREST工具训练每个phone的模型。HINIT将数据切割至phone级,运用k-mean的方法计算每个phone的参数。再通过HREST调整参数。
当不存在fully labelled bootstrap data, 使用HCompV进行初始化,用到部分训练数据。
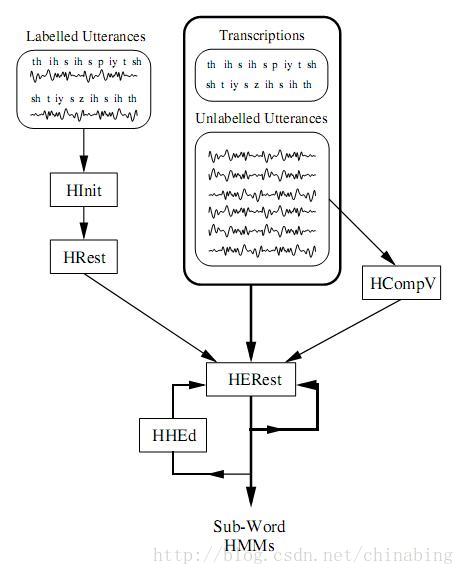
图2.3 训练sub-word HMM
完成模型的初始化后,再使用全部训练数据进行embedded training,这里用到HERest工具。HERest为所有的phone模型执行Baum-Welch re-estimation。对于每条训练语句,相应的phone模型会被串联起来,使用前向-后向算法为序列中的每个模型累积state occupation,means, variances等统计参数。当所有的训练数据都被处理后,累积的参数用于冲估计HMM参数。HERest是HTK训练工具的核心。它被用于训练大数据库,具有剪枝的配置用于降低计算量,也可以在网络中并行运算。
HMM模型被逐步优化是用HTK工具进行系统构建的哲学。因此,以单高斯、上下文无关phone 模型开始,然后扩展至混合高斯、上下文相关phone模型。HHed是HMM模型编辑器。可以用于将上下文无关phone模型转化为上下文相关phones模型,进行参数绑定,增加指定分布混合高斯的数目。
构建上下文相关HMM系统最大的问题是训练数据不够充足。模型集合越大,越复杂,所需的训练数据也就越多。需要使用一种机制平衡系统的复杂性与数据的有限性。对于连续密度系统,这种机制就是参数绑定。
2.3.3 识别工具
HTK提供了一种识别工具HVite, 使用语言模型和lattice进行识别。HLRescore是一种对lattice进行操作的工具,该lattice由HVite或HDecode工具生成,在lattice上添加更加复杂的语言模型。HTK的另外一个识别器是HDecode。注意: HDecode是在一个更加严格的许可下发布的。
HVite
HVite是使用token passing算法的识别工具,该算法在前面的章节中已做说明,执行基于Viterbi算法的语音识别。HVite的输入有描述所以可能词序列的识别网络、定义每个词发音的词典和HMM集。它将词网络转化为phone网络,将HMM集中的phone定义与网络中的phone绑定。识别的输入可以是语音列表文件,也可以直接录入语音。正如上一章节最后提到的,HVite支持cross-word triphones, 它能够执行多个tokens,生成包括多个hypotheses的lattice。它能够rescore lattice以及执行Force alignments。
HVite中的词网络或者是简单的词循环序列,任意词可以在任意词的后面,或者是有向图,表示一个有限状态任务语法。对于前一种情况,词转换之间一般带有bigram概率。词网络使用标准的lattice格式存储,这是一种基于文本的格式,因此可以使用文本编辑器对其进行编辑。然而,这种做法相当繁琐,因此HTK提供了两个工具来简化词网络的构建。首先,HBuild容许sub-networks以更高级的网络形式创建和使用。因此,尽管低级网络是一致的,但会减少大量重复。同时,HBuild能够被用于生成word loops, 它能够读入一个backed-off bigram language model, 修改word loop transitions, 从而合并bigram概率。注意,前面提到的标准统计工具HStats能够用于生成backed-off bigram language model.
除了直接确定词网络外,还有一种更高级的语法标记方法。该标记基于EBNF。HParse可以将该类型标记转换为词网络。
无论使用哪种网络生成方法,生成该网络所定义的语言的一个实例是很有必要的。HSGen工具可以实现这一功能。它的输入是词网络,输出是该网络的一条任意路径。HSGen还可以计算该网络的复杂度。
HLRecsore
HLRescores是用于操作lattice的工具。它以标准的lattice格式(例如由HVite生成的lattice)读入lattice,然后执行以下操作:
(1) 寻找lattice中1-best路径:this allows language model scalefactors and insertion penalties to be optimized rapidly;
(2) 使用新的语音模型扩展lattice: 容许使用更复杂的语音模型,例如4-gram,这样可以更有效的应用于解码中。
(3) 将lattices转换为等价的词网络:this is necessary prior tousing lattices generated with HVite(or HDecode) to merge duplicate paths
(4) 计算各种lattice统计信息
(5) 使用前向后向得分裁剪lattice
(6) 通过语言模型将词MLF文件转换为lattice:区分性训练解分母lattice时使用
HLRescore处理的lattice是有向无环图。如果lattice中存在环,HLRescore将报错。
HDecode
HDecode是用于大词汇语音识别和lattice生成的解码工具,是HTK的扩展,它的使用许可更严格。类似于HVite,HDecode通过HMM模型集和词典对语音文件进行解码。最佳解码候选保存于MLF文件中。同样,可以通过配置项生成多个解码候选,保存于SLF文件中。
识别过程的搜索空间由基于网络的模型定义,该模型可以通过扩展语言模型生成或者又词级lattice生成。如果没有词lattice,需要通过语言模型执行full decoding。HDecode目前的版本支持trigram和bigram full decoding。如果存在词lattice,那么语言模型是可选的,这种模式操作称之为lattice rescoring。
HDecode期望lattices中没有重复的词路径。但是,在默认情况下,由HDecode生成的lattice存在重复路径,这是由于一词多音情况以及可选的词间silence。为了使lattice适用于lattice rescoring,利用HLRescore将lattice中重复的路径合并(使用-m选项)。
目前版本的HDecode还存在一些局限性:
(1) 仅仅适用于cross-word triphones
(2) Sil和sp模型被存储为silence模型,默认情况下,会自动在词的结尾加上该模型。
(3) 由HDecode生成的lattice在进行lattice rescoring之前,必须合并或删除重复的路径。
2.3.4 分析工具
一旦基于HMM的识别器构建完成,需要评估它的性能。通常的做法是通过识别正确率来衡量。HResult使用动态规划的方法来对其原始标注与识别结果,统计替换错误、插入错误和删除错误数目。Options are provided to ensure that the algorithms andoutput formatsused by HResults are compatible with those used by the US National InstituteofStandards and Technology (NIST). As well as global performance measures,HResults canalso provide speaker-by-speaker breakdowns, confusion matrices andtime-aligned transcriptions.For word spotting applications, it can also computeFigure of Merit (FOM) scores and ReceiverOperating Curve (ROC) information.
2.4 Version 3.4中的新功能
这一章节列出了3.4版相对于之前3.3版的一些新特性
1. 增加了用于区分性训练的HMMIRest工具。该工具支持最小phone错误(MinimumPhone Error, MPE)和最大互信息(MaximunMutual Information, MMI)训练。 To support this additional library modules for performing theforward-backward algorithm on lattices, and the ability to mark phone boundarytimes in lattices have been added.
2. 增添了HDecode工具
3. 扩展了HERest工具,使其支持estimatingsemitied and HLDA transformations.
4. Compilation issues have nowbeen dealt with
5. Many other smaller changes andbug fixes have been integrated.
最后
以上就是紧张小馒头最近收集整理的关于HTK 第二章 HTK工具包概述的全部内容,更多相关HTK内容请搜索靠谱客的其他文章。








发表评论 取消回复