正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。(简单的讲就是一种过滤器)
常见的正则表达式符号:
| 符号 | 功能 |
| 转义字符,使用在一些特殊符号前,使之可以匹配 | |
| ^ | 锁定在行首,使用在字符的最前端 |
| $ | 锁定在行尾,使用在字符的最后端 |
| . | 匹配单字符,点号位置必须有字符 |
| [ ] | 匹配括号内的单个单词 |
| [ ^ ] | 不匹配括号内的单词 |
| [x-y] | 匹配区间,数字和字符都有用 |
| * | 表示出现0次或多次 |
Linux的正则表达式引擎:
- POSIX基础正则表达式(BRE)引擎
- POSIX扩展正则表达式(ERE)引擎
POSIX BRE
引擎通常出现在依赖正则表达式进行文本过滤的编程语言中。它为常见模式提供
了高级模式符号和特殊符号,比如匹配数字、单词以及按字母排序的字符。
gawk
程序用
ERE
引擎
来处理它的正则表达式模式。
注意:正则表达式区分大小写
1.纯文本的匹配

注意:可以匹配空格
![]()
2.特殊字符的匹配
匹配特殊字符 需要使用转义符(),使用在特殊字符的前面
特殊字符有:
- .*[ ]^${ }+?|()



3.锚字符
- ^ 匹配开头,作用于最开头 (开头之外的其他位置,那么它就跟普通字符一样,当^后没有字符时匹配时不需要转义,其他地方需要转义[sed 和gawk情况不同])
- $ 匹配结尾,作用于最末尾

1.匹配开头:

2.匹配结尾:

3.匹配^(不作为锚点,作为普通字符)
sed :开头之外的其他位置,那么它就跟普通字符一样,当^后没有字符时匹配时不需要转义,其他地方需要转义()
gawk:开头之外的其他位置,在哪都需要使用转义字符()
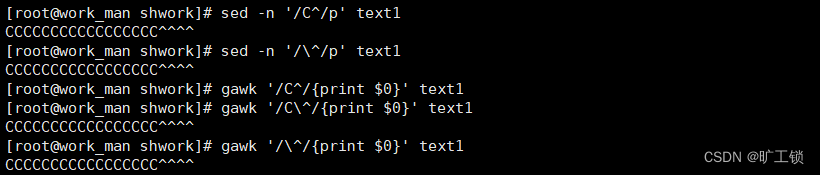
4.^和$的组合使用


6.剔除空行:


4.点号字符
点号 用来匹配除换行符之外的任意单个字符:
使用规则:
- 匹配时,点号这个位置必须有字符
- 点号后面也必须要匹配


5.字符组
使用 [ ] 来匹配内容,你可以匹配中括号的任意一个字符,可以使用多个[ ]匹配

匹配1或2开头的数据:

匹配0-19999的数

6.排除字符组
[^] 可以排除中括号内的字符
排除1和2开头的数据

7.匹配区间
[x-y] 匹配x和y之间的字符,包括x和y(可用于数字和字母)


8.星号
在字符后面放置星号表明该字符必须在匹配模式的文本中出现
0
次或多次。(表示该字符可有可无)

表示 o可以出现0次或多次

扩展正则表达式
一些gawk特有的过滤符号
| 符号 | 功能 |
| ? | 匹配前面的字符何以出现0次或多次 |
| + | 匹配前面的字符可以出现一次或多次(但必须至少出现一次) |
| {} | 指定字符出现的次数 |
| | | 相当与或 |
| () | 把一串字符包装为1个标准字符 |
1.问号(?)
表明前面的字符可以出现0次或1次,但只限于此。它不会匹配多次出现的字符。


2.加号
表明前面的字符可以出现一次或多次(但必须至少出现一次)

3.花括号
花括号允许你为可重复的正则表达式指定一个上限。这通常称为间隔(interval)。可以用两种格式来指定区间
- {m} 表示准确出现每次
- {m,n} 表示最少出现m次,最多出现n次
- 一般需要配合 gawk程序的 --re- interval 使用(有些可以不添加)
![]()

4.管道符号
相当于使用或(or)运算匹配数据
格式:
expr1|expr1|...

5.表达式分组
用圆括号进行分组,该分组会视为一个标准字符

最后
以上就是知性小天鹅最近收集整理的关于Shell 正则表达式的全部内容,更多相关Shell内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复