本人用R语言中的rvest包(需要加载xml2)爬取了猎聘网的一些数据,关键词为’数据分析’,网址是这个,然后利用python中的pandas进行分析。
爬虫
简单介绍一下,rvest包支持Xpath,是我目前接触到的R语言爬虫最好的包。首先观察一下网页翻页的变化,发现第二页是在网址后面加了一个’&curPage=1’,尝试让最后是’0’,发现又回到了第一页,这个网站的页数是从’0’开始的,而R中的索引是从1开始的(没什么影响,只是感慨一下),最多只能到100页,也就是这次的循环是for (i in 0:99){pass} #R中没有pass,理解这么个意思就行了。先分析一个页面:
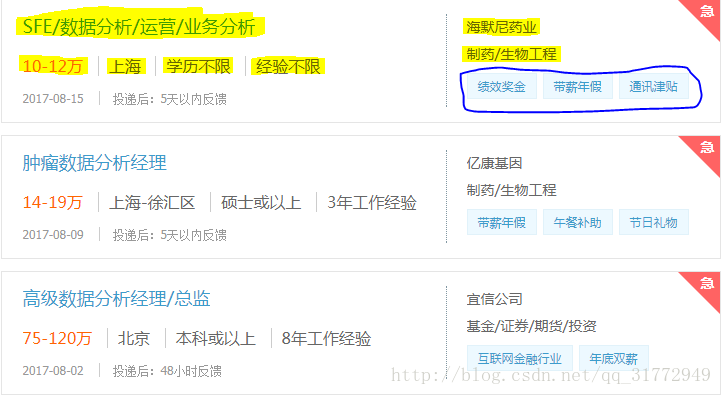
黄色的就是我要获取的东西,蓝色圈内是公司对对职位福利的描述(像五险一金,领导好之类的),顺便也爬下来了,下面请看详细介绍:
library(xml2)
library(rvest)# 载入所需包
url<-"https://www.liepin.com/zhaopin/?fromSearchBtn=2&ckid=b1cb589ca92cf57e°radeFlag=0&sfrom=click-pc_homepage-centre_searchbox-search_new&init=-1&key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&headckid=b1cb589ca92cf57e" # 要爬取的网页
position_info <- data.frame() # 初始化要储存信息的数据框
page<-read_html(url) # 读取网页信息
position<-page%>%html_nodes('ul.sojob_list div.sojob-item-main div.job-info,h3 a')%>%html_text(trim = TRUE) # 读取职位名,trim = TRUE 可以避免爬取的信息出现一堆rnt的东西。
address <- page %>% html_nodes('p.condition a.area') %>% html_text() # 爬取工作地点
experience <- page %>% html_nodes('p.condition span') %>% html_text() # 对工作经验的要求
companyName <- page %>% html_nodes('ul.sojob_list div.sojob-item-main div.company-info,p.company-name a') %>% html_text(trim=TRUE) # 公司名称
companyField <- page %>% html_nodes('p.field-financing span') %>% html_text(trim = TRUE) # 公司所在领域,像移动互联网,金融什么的。公司的福利标签内容数目个数不一定都有,而且不同的公司的内容不太一样,爬取起来比较麻烦,鄙人不才,用列表和循坏弄的,代码有四五行,就不贴出来,然后把爬到的东西存到之前的数据框里就行了,最后在写到txt文件里面,我不喜欢用csv文件,csv总是出现编码问题。
分析
数据分析我用的是python中的pandas库,直接上代码吧!
这些东西可能用不到,先写上肯定没错。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('ggplot') # 导入所需包,配色方案使用ggplot
plt.rcParams['font.sans-serif'] = ['SimHei'] # 正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
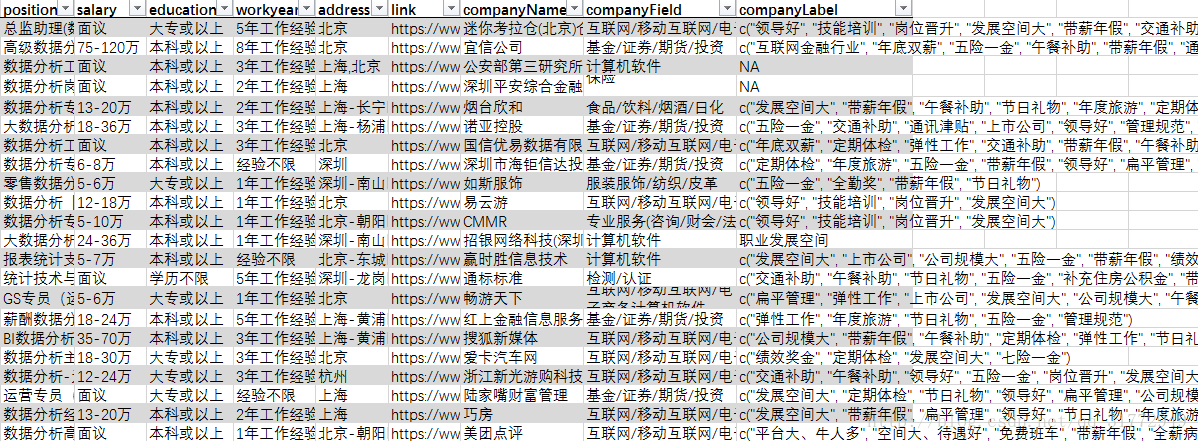
然后就去读取数据,清洗掉一些没用的数据,注意到在工资那里有一些写着面议,另外一些写的是薪资范围,不能直接进行计算,我把面议删掉了,然后把文本进行拆分,变成薪资上界和下界并转化成int,然后取均值。之后在把福利标签清理一下,爬的时候带着‘c’和‘()’,这个要去掉才能分析。很简单,代码就略了。
然后就可以进行分析了:
先按照城市进行分组,然后查看一下:
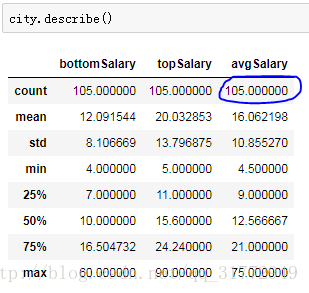
发现有105个城市,这非常不利于我们进行分析,所以我选择了几个比较热门的城市,算了,不想说太多了,直接上图算了
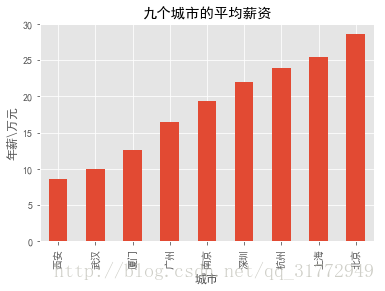
我们发现北京的平均薪资最高,上海是第二,杭州第三,深圳第四,南京第五,广州比南京低了一大截,位于第六,长三角地区的三个主要城市果然比较争气。再来一个箱线图看看,
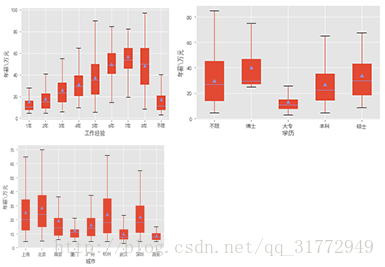
先看看左上角的工作经验和薪水的关系,发现随着工作经验的增加薪水也是在增加的;工作经验是连续的,当然也可以将其离散化,换成3~5年啊什么的;右上角是学历和薪水的关系,不限学历的上限和下限都比较极端,博士的下限和上限确实比较高但是明显的右偏,大专明显没有什么优势,本科生和硕士也有一些差别,但是差别不大;左下角是城市和薪水的关系,可以看出北京上海杭州深圳的上四分位数和下四分位数基本在同一档次上,比其他的城市明显高;算了,反正图在这儿了,自己理解吧
在附上一张福利标签的词频统计:

发现大多数公司认为职员最关注五险一金,带薪年假。还有647个公司什么都没写
当然也有一些不足之处:
1. 招聘信息不能代表在职人员的实际信息。
2. 有的公司还写着六险一金,它想表达的和五险一金没啥差别,还有一些会把领导好写成领导nice,这些程序都识别不出来,需要我们告诉程序,我在这里懒得弄了。
最后
以上就是淡然草莓最近收集整理的关于数据分析职位爬虫与分析的全部内容,更多相关数据分析职位爬虫与分析内容请搜索靠谱客的其他文章。








发表评论 取消回复