最近,我向大家介绍了我的 side-project,是个用 C# 写的简单的神经网络项目。正如我在那篇文章中提到的,给出的解决方案离最优方案还差的太远。假如要达到专业化使用的程度,这个解决方案还需要使用更多的数学和矩阵乘法。幸运的是,Google 里有些聪明人创造了一个做这件事情的库——TensorFlow。这是一个广受欢迎的开源库,正如你目前所了解的那样,它擅长于数字计算,这对我们的神经网络计算至关重要。它为大多数主流程序语言进行深度学习领域的开发提供了应用程序接口。

TensorFlow 是如何运作的呢? 它的整个解决方案是基于张量进行的,张量是 TensorFlow 的原始单元。TensorFlow 使用一个张量数据结构来表示所有数据。在数学中,张量是描述其他几何对象之间的线性关系的几何对象。在 TesnsorFlow 中,它们是多维数组或数据,比如矩阵。其实它并不像这样简单, 但这就是我现在想说的深入线性代数的整个张量的概念。无论如何,我们可以把张量看作是 n 维阵列,对它使用矩阵运算是简单且有效的。例如,在下面的代码中,我们定义了两个常量张量,并将一个值添加到另一个上。
更多Python视频、源码、资料加群683380553免费获取
这就是整个张量概念在线性代数中,
我们都知道,常量的值是不变的。而 TensorFlow 拥有丰富的 API,它的文档也很齐全,我们可以使用它定义其他类型的数据,比如变量。
除了张量之外,TensorFlow 还使用数据流图。图中的节点表示数学运算,边表示在它们之间通信的张量。
安装和设置
TensorFlow 为各种程序语言提供了 API,比如 Python、C++、Java、Go、Haskell 和 R(以第三方库的形式)。此外,它支持不同类型的操作系统。在本文中,我们将在 Windows 10 上使用 Python,因此会提及这个平台上的安装过程。TensorFlow 只支持 Python 3.5 和 3.6,所以请确保你的系统中安装了其中的一个版本。对于其他的操作系统和语言,你可以查看官方的安装指南。我们需要了解的另一件事是系统的硬件配置。安装 TensorFlow 可以有两种选择:
- 只支持 CPU 的 TensorFlow 版本。
- 支持 GPU 的 TensorFlow 版本。
如果你的系统有一个 NVIDIA GPU,那么你可以安装支持 GPU 的 TensorFlow 版本。当然,GPU 版本更快,但是 CPU 版更容易安装和配置。
如果你使用 Anaconda 安装 TensorFlow,可以按照以下步骤完成:
通过运行命令来创建一个 conda 环境“tensorflow”。
conda create -n tensorflow pip python=3.5
通过命令激活创建的环境:
activate tensorflow
调用该命令来在你的环境中安装 TensorFlow。对于 CPU 版本运行这个命令:
pip install --ignore-installed --upgrade tensorflow
对于 GPU 版本运行命令:
pip install --ignore-installed --upgrade tensorflow-gpu
当然,你也可以使用“native pip”命令来安装 TensorFlow。对于 CPU 版本运行:
pip3 install --upgrade tensorflow
对于 GPU TensorFlow 版本运行命令:
pip3 install --upgrade tensorflow-gpu
现在我们已经安装了 TensorFlow。接下来开始解决我们要解决的问题。
Iris 数据集分类问题
Iris 数据集,以及 MNIST 数据集,可能是模式识别文献中最著名的数据集之一。这是机器学习分类问题的“Hello World”示例。它最早是在 1936 年由 Ronald Fisher 推出的。他是英国的统计学家和植物学家,他在论文《使用多重测量解决生物分类问题》中使用了这个例子,直到今天这篇论文也经常被引用。该数据集包含 3 个类别,每个类别有 50 个实例。每个类别都是一种类型的 Iris 植物:Iris setosa、Iris virginica 和 Iris versicolor。第一类是线性可分的,但后两种不是线性可分的。每个记录都有五个属性:
- cm 表示的 Sepal 长度
- cm 表示的 Sepal 宽度
- cm 表示的 Petal 长度
- cm 表示的 Petal 宽度
类别 Class(Iris setosa, Iris virginica, Iris versicolor)
我们要创建神经网络的目标是根据其他属性来预测 Iris 的种类。这意味着它需要创建一个模型,描述属性值和类别之间的关系。
TensorFlow 工作流
大部分的 TensorFlow 代码遵循这个工作流程:
- 导入数据集
- 使用附加列扩展数据集,用以描述数据
- 选择模型的类型
- 开始训练
- 评估模型的准确性
- 使用模型预测结果
如果你关注我之前的博客文章,你可能会注意到开发任何人工神经网络都离不开训练和评估过程。这些过程通常是在两个数据集上完成的,一个用于训练,另一个用于测试训练网络的准确性。通常,我们得到一组数据,我们需要将它们分成两个独立的数据集,并使用其中一个进行培训,另一个用于测试。这一比率通常为 80% 到 20%。这次这些都已经为我们做好了。你可以从这里下载训练数据集,从这里下载测试数据集。或者你可以从这里下载完整的代码和数据。
编码
在继续之前,我得首先说明一下,我使用 Spyder IDE 进行开发,因此我将使用这个环境来解释整个过程。
我们需要做的第一件事是导入数据集并解析它。为此,我们需要使用另一个 Python 库 -Pandas。这是另一个开源库,为 Python 提供了易于使用的数据结构和数据分析工具。
正如你所看到的,首先我们使用 readcsv 函数将数据集导入到本地变量中,然后我们将输入 (train_x、test_x) 和预期输出 (train_y、test_y) 分离开来,创建四个独立的矩阵。以下是他们的样子:
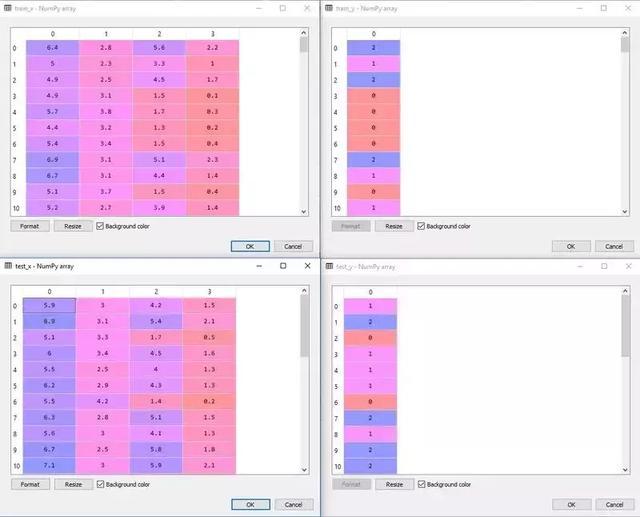
我们准备好了用于训练和测试的数据。现在,我们需要定义特征列,这也是神经网络需要的。
我们现在需要选择我们将要使用的模型。在我们的问题中,我们试图根据属性数据来预测 Iris 的类型。所以我们要从 TensorFlow API 中选择一个评估器。评估器类的一个对象封装了构建 TensorFlow 图形并运行 TensorFlow 会话的逻辑。为此,我们将使用 DNN 分类器。我们将添加两个隐藏的层,每个层有十个神经元。
在那之后,我们将用我们从训练数据集中选取的数据来训练我们的神经网络。首先,我们将定义训练功能。该函数需要通过扩展和创建多个批次来提供来自训练集的数据。如果训练样本是随机的训练效果也会更好。这就是为什么调用 shuffle 函数的原因。总之, train_function 使用经过训练的数据集,随机地从数据中选取数据,并将数据反馈给 DNN 分类器的训练方法,从而创建大量的数据。
最后,我们调用评估函数来评估我们的神经网络,并给出网络的回准度。
当我们运行这段代码后,将得到如下结果:
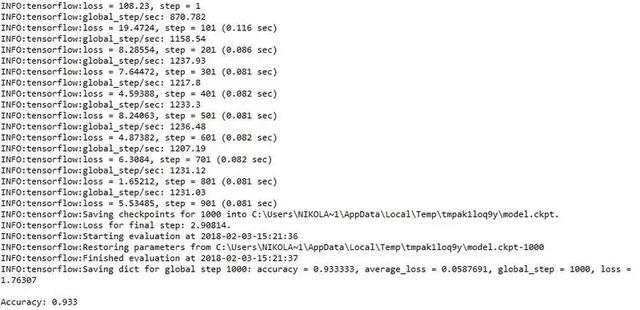
所以,我的神经网络的精度是 0.93,非常不错。在此之后,我们可以使用单个数据调用分类器,并对其进行预测。
结论
神经网络已经存在很长时间了,现在的几乎所有重要的概念都可以追溯到 70 年代或 80 年代。阻碍整个领域发展的问题是那时我们没有强大的计算机和 GPU 来运行这些程序。现在,我们不仅可以做到这一点,而且 Google 通过创造这一伟大的工具使神经网络变的流行起来,那就是开源的 TensorFlow。如今,我们还有其他更高级的 API,可以进一步简化神经网络的实现。其中一些比如 Keras 也是基于 TensorFlow 运行的。在以后的文章中,我们将对这一问题进一步探讨。
最后
以上就是成就面包最近收集整理的关于如何用一个Python示例入门TensorFlow?的全部内容,更多相关如何用一个Python示例入门TensorFlow内容请搜索靠谱客的其他文章。








发表评论 取消回复