机器学习 实验三 手写汉字识别
一、实验环境
PC机,Python
二、代码
一、使用神经网络
#%%
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import os,PIL,pathlib
import numpy as np
import warnings
from tensorflow import keras
import cv2
#%%
from PIL import Image
img = Image.open(r'datatrain�input_1_1_1.jpg', 'r')
img
#%%
import os
def file_name(file_dir):
L=[]
for root, dirs, files in os.walk(file_dir):
for file in files:
if os.path.splitext(file)[1] == '.jpg':
L.append(os.path.join(root, file))
L.sort()
return L
#%%
train_image_paths=file_name('data\train')
train_path_ds = tf.data.Dataset.from_tensor_slices(train_image_paths)
train_path_ds
#%%
train_image_paths
#%%
# pre_image_paths=file_name('data\test')
# pre_path_ds = tf.data.Dataset.from_tensor_slices(pre_image_paths)
# pre_path_ds
#%%
# pre_image_paths
#%%
pre_image_paths_sort=[]
dirname='data\test\'
for i in range(3000):
pre_image_paths_sort.append(dirname+str(i)+'.jpg')
#%%
pre_image_paths_sort
#%%
for i in range(3000):
if(pre_image_paths_sort[i]=='data\test\3.jpg'):
print(i)
#%%
pre_path_ds = tf.data.Dataset.from_tensor_slices(pre_image_paths_sort)
pre_path_ds
#%%
n2=len(pre_path_ds)
n2
#%%
train_image_label=[]
for i in train_image_paths:
k=i[-6:-4]
if(k[0]=='_'):
k=k[-1]
k=int(k)-1
train_image_label.append(k)
#将标签切片
train_label_ds = tf.data.Dataset.from_tensor_slices(train_image_label)
#%%
train_image_label
#%%
def preprocess_image(image):
image = tf.image.decode_jpeg(image,channels = 3)
image = tf.image.resize(image,[64,64])
return image / 255.0
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
#根据路径读取图片并进行预处理
train_image_ds = train_path_ds.map(load_and_preprocess_image,num_parallel_calls=tf.data.experimental.AUTOTUNE)
pre_image_ds = pre_path_ds.map(load_and_preprocess_image,num_parallel_calls=tf.data.experimental.AUTOTUNE)
#%%
train_image_ds
#%%
pre_image_ds
#%%
image_label_ds = tf.data.Dataset.zip((train_image_ds,train_label_ds))
#%%
image_label_ds
#%%
num=0
for i in range(20):
plt.subplot(4, 5, i + 1)
num +=1
plt.xticks([])
plt.yticks([])
plt.grid(False)
t=i+2000
# 显示图片
images = plt.imread(train_image_paths[t])
plt.imshow(images)
# 显示标签
plt.xlabel(train_image_label[t])
plt.show()
#%%
n=len(image_label_ds)
n
#%%
image_label_ds = image_label_ds.shuffle(n)
#%%
image_label_ds
#%%
num=0
for i in range(20):
plt.subplot(4, 5, i + 1)
num +=1
plt.xticks([])
plt.yticks([])
plt.grid(False)
t=i+5000
# 显示图片
images = plt.imread(train_image_paths[t])
plt.imshow(images)
# 显示标签
plt.xlabel(train_image_label[t])
plt.show()
#%%
test_count=int(n*0.2)
train_count=n-test_count
train_ds = image_label_ds.take(train_count).shuffle(test_count)
test_ds = image_label_ds.skip(train_count).shuffle(test_count)
#%%
train_ds=image_label_ds.shuffle(n)
#%%
train_ds
#%%
pre_ds=pre_image_ds
#%%
# for i in train_ds:
# print(i)
#%%
height = 64
width = 64
batch_size = 128
epochs = 50
#%%
train_ds = train_ds.batch(batch_size)#设置batch_size
train_ds = train_ds.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
test_ds = test_ds.batch(batch_size)
test_ds = test_ds.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
pre_ds=pre_ds.batch(batch_size)
pre_ds = pre_ds.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
#%%
plt.figure(figsize=(8, 8))
for images, labels in train_ds.take(1):
# print(images.shape)
for i in range(12):
ax = plt.subplot(4, 3, i + 1)
plt.imshow(images[i])
plt.title(labels[i].numpy()) # 使用.numpy()将张量转换为 NumPy 数组
plt.axis("off")
break
plt.show()
#%%
train_ds
#%%
# for i in train_ds:
# print(i)
#%%
test_ds
#%%
pre_ds
#%%
for i in pre_ds:
print(i)
#%%
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32,kernel_size=(3,3),padding="same",activation="relu",input_shape=[64, 64, 3]),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(filters=64,kernel_size=(3,3),padding="same",activation="relu"),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(filters=64,kernel_size=(3,3),padding="same",activation="relu"),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(15, activation="softmax")
])
model.compile(optimizer="adam",
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
history = model.fit(
train_ds,
validation_data=test_ds,
epochs = epochs
)
#%%
model.save('modelbest2.h5')
#%%
train_ds
#%%
test_ds
#%%
modelbest=keras.models.load_model('modelbest2.h5')
#%%
modelbest
#%%
pre=modelbest.predict(pre_ds)
pre[0]
#%%
result=[]
for i in pre:
maxpre=0
maxpreindex=0
for j in range(len(i)):
if(i[j]>maxpre):
maxpre=i[j]
maxpreindex=j
t=maxpreindex
if(maxpreindex==11):
t=100
elif(maxpreindex==12):
t=1000
elif(maxpreindex==13):
t=10000
elif(maxpreindex==14):
t=100000000
result.append(t)
#%%
result
#%%
plt.figure(figsize=(10, 10))
for images in pre_ds:
for i in range(20):
ax = plt.subplot(4, 5, i + 1)
plt.imshow(images[i])
# mo="but"
# s=str(labels[i].numpy())+mo+str(result[i])
plt.title(result[i])
# plt.title(pre_image_paths_sort[i][-8:-3])
plt.axis("off")
break
plt.show()
#%%
a = []
b=[]
for line in range(3000):
a.append(str(line)+'.jpg')
b.append(result[line])
a = pd.DataFrame(a)
b= pd.DataFrame(b)
df=pd.concat([a,b],axis=1)
df.to_csv('submission', sep='t', header=None, index=False)
二、使用MLP
#%%
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import os,PIL,pathlib
import numpy as np
import warnings
from tensorflow import keras
import cv2
from sklearn.neural_network import MLPClassifier
# train_data = pd.read_csv('/ilab/datasets/local/chinese_num')
# train_data
#%%
from PIL import Image
img = Image.open(r'datatrain�input_1_1_1.jpg', 'r')
img
#%%
import os
def file_name(file_dir):
L=[]
for root, dirs, files in os.walk(file_dir):
for file in files:
if os.path.splitext(file)[1] == '.jpg':
L.append(os.path.join(root, file))
L.sort()
return L
#%%
train_image_paths=file_name('data\train')
train_path_ds = tf.data.Dataset.from_tensor_slices(train_image_paths)
train_path_ds
#%%
pre_image_paths_sort=[]
dirname='data\test\'
for i in range(3000):
pre_image_paths_sort.append(dirname+str(i)+'.jpg')
#%%
for i in range(3000):
if(pre_image_paths_sort[i]=='data\test\3.jpg'):
print(i)
#%%
pre_path_ds = tf.data.Dataset.from_tensor_slices(pre_image_paths_sort)
pre_path_ds
#%%
train_image_label=[]
for i in train_image_paths:
k=i[-6:-4]
if(k[0]=='_'):
k=k[-1]
k=int(k)-1
if(k==11):
k==100
elif(k==12):
k=1000
elif(k==13):
k=10000
elif(k==14):
k=100000000
train_image_label.append(k)
#将标签切片
train_label_ds = tf.data.Dataset.from_tensor_slices(train_image_label)
#%%
train_image_label
#%%
def img2vec(fname):
'''将jpg等格式的图片转为向量'''
im = Image.open(fname).convert('L')
im = im.resize((128,128))
tmp = np.array(im)
vec = tmp.ravel()/255.0
return vec
#%%
train_image_data=[]
for i in train_image_paths:
train_image_data.append(img2vec(i))
#%%
train_image_data
#%%
s_data=np.array(train_image_data)
s_label=np.array(train_image_label)
#%%
index=np.arange(len(s_data))
np.random.shuffle(index)
#%%
s_data=s_data[index]
#%%
s_label=s_label[index]
#%%
pre_image_data=[]
for i in pre_image_paths_sort:
pre_image_data.append(img2vec(i))
#%%
num=0
for i in range(20):
plt.subplot(4, 5, i + 1)
num +=1
plt.xticks([])
plt.yticks([])
plt.grid(False)
t=i
# 显示图片
# images = plt.imread(train_image_data[t])
plt.imshow(s_data[t].reshape(128,128))
# 显示标签
plt.xlabel(s_label[t])
plt.show()
#%%
#尝试lbfgs、sgd、adam三种优化器
# lbfgs = MLPClassifier(solver = 'lbfgs', hidden_layer_sizes = [100,100,100,100,100], activation = 'relu',
# alpha = 1e-4, random_state = 100, verbose = 1)
#%%
sgd = MLPClassifier(solver = 'sgd', hidden_layer_sizes = [300,300,300,300,300], activation = 'relu',
alpha = 1e-4, random_state = 100, verbose = 1, learning_rate_init = 0.1)
#%%
adam = MLPClassifier(solver = 'adam', hidden_layer_sizes = [100,100,100,100], activation = 'relu',
alpha = 1e-4, random_state = 100, verbose = 1)
#%%
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(s_data, s_label, random_state=1, train_size=0.8)
#%%
# lbfgs.fit(x_train, y_train)
#%%
sgd.fit(x_train, y_train)
#%%
adam.fit(x_train,y_train)
#%%
# lbfgs_predict = lbfgs.predict(x_test)
#%%
sgd_predict = sgd.predict(x_test)
#%%
# adam_predict = adam.predict(x_test)
#%%
# print("lbfgs在训练集准确度: %f" % lbfgs.score(x_train, y_train))
# print("lbfgs在测试集准确度: %f" % lbfgs.score(x_test, y_test))
print("sgd在训练集准确度: %f" % sgd.score(x_train, y_train))
print("sgd在验证集准确度: %f" % sgd.score(x_test, y_test))
print("adam在训练集准确度: %f" % adam.score(x_train, y_train))
print("adam在测试集准确度: %f" % adam.score(x_test, y_test))
#%%
# pre=lbfgs.predict(pre_image_data)
#%%
# pre
#%%
pre2=sgd.predict(pre_image_data)
#%%
# pre2
#%%
# pre3=adam.predict(pre_image_data)
# pre3
#%%
result=[]
for i in pre2:
result.append(i)
#%%
data=pd.read_csv('submission.csv')
#%%
data
#%%
result
#%%
a = []
b=[]
for line in range(3000):
a.append(str(line)+'.jpg')
b.append(result[line])
a = pd.DataFrame(a)
b= pd.DataFrame(b)
df=pd.concat([a,b],axis=1)
df.to_csv('submissionmlp2.csv', sep='t', header=None, index=False)
二、实验结果与分析
1、猎豹平台提交结果:
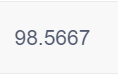
2、对于手写汉字的识别可以使用很多种方法,文中利用的是tensorflow库,大家可以试试pytorch。在MLP中的lbfgs、sgd、adam三种优化器,他们所展现的效果区别还是挺大的,大家可以看看三者的具体区别。(链接我就不放了,大家自由学习)对于多层感知机参数的调整经历了不少的尝试,大家在使用文章代码时可以自主调整,希望能有不错的效果提升。
最后
以上就是冷静柜子最近收集整理的关于机器学习 实验三 手写汉字识别机器学习 实验三 手写汉字识别的全部内容,更多相关机器学习内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复