你好哇,我是单字鹏。欢迎进入我的C语言总结。
今天我们来总结C语言中数据是如何通过类型来保存到内存中的。
C语言是如何分配内存的
我们知道现在主流的计算机系统分为32位系统和64位系统,这其中的位就是比特位。
计算机中存储数据的设备是硬盘和内存,处理数据的设备是cpu。
但是cpu是不负责保存数据(只能短暂的保存需要处理的数据),而且要处理的数据只能在内存中读取。处理好的数据也只能保存在内存中。
所以cpu和内存之间就需要有进行数据的传输通道——总线。
以32位系统的计算机为例,它的总线就有32根地址线组成。

就有2^32(4294967296)组的随机组合,每一个组合标记内存中的一个字节(8比特位)的空间。所以这些组合就是地址,内存地址。

从计算器中的单位换算中可以知道2^32(4294967296)组的地址就可以标记4G大小空间的内存。
那C语言又是如何区划分这些空间的?
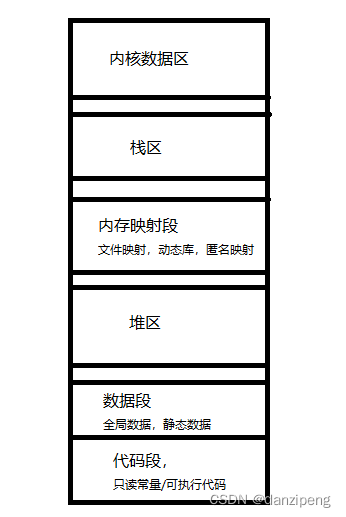
整形的数据是如何保存进内存的?
整形的数据要保存在内存要经过原码转反码 ,反码转补码 才能保存在内存中。
为什么要这么复杂的转换了?
这就需要牵扯到cpu的设计和原理了,因为在设计cpu 时需要考虑成本和复杂程度的。越复杂造价越高。我们的科学家前辈们发现 负数经过三码的转换后就可以直接用加法来完成计算。直接就可以设计一个加法器,就可以完成数据的加减的计算。就简化了cpu的设计

因为负数需要经过这些转换才能完成计算,而整数不需要这些转换就可以直接完成计算,所以正整数的原码 反码 补码 三码相同都等于原码。

所以整形的数据在cpu中处理时就是用补码来完成的。在内存中也是用补码进行保存的。
整形的数据保存在内存中的具体表现
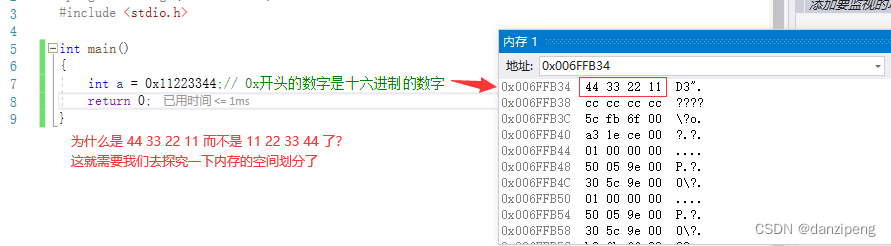
 要理解上面代码的实践表现就得知道大小端字节序的概念?
要理解上面代码的实践表现就得知道大小端字节序的概念?
最后
以上就是伶俐太阳最近收集整理的关于C语言总结 深入理解数据在内存中的保存的全部内容,更多相关C语言总结内容请搜索靠谱客的其他文章。







![[C语言数据存储深度解析]-内存数据搞不懂?三千字长文带你走进数据类型及其存储C语言的基本数据类型内置类型的基本归类整型数据在内存中的存储浮点型数据在内存中的存储写在最后](https://www.shuijiaxian.com/files_image/reation/bcimg18.png)
发表评论 取消回复