说明
本教程将结合经典的神经网络入门案例,通过绘图剖析网络中传播的细节,并附上详细的求导公式,希望能帮助读者更好地理解神经网络的工作过程,本教程需要你了解一些神经网络的基本知识。如果文中有错误,请各位大佬及时指正
案例
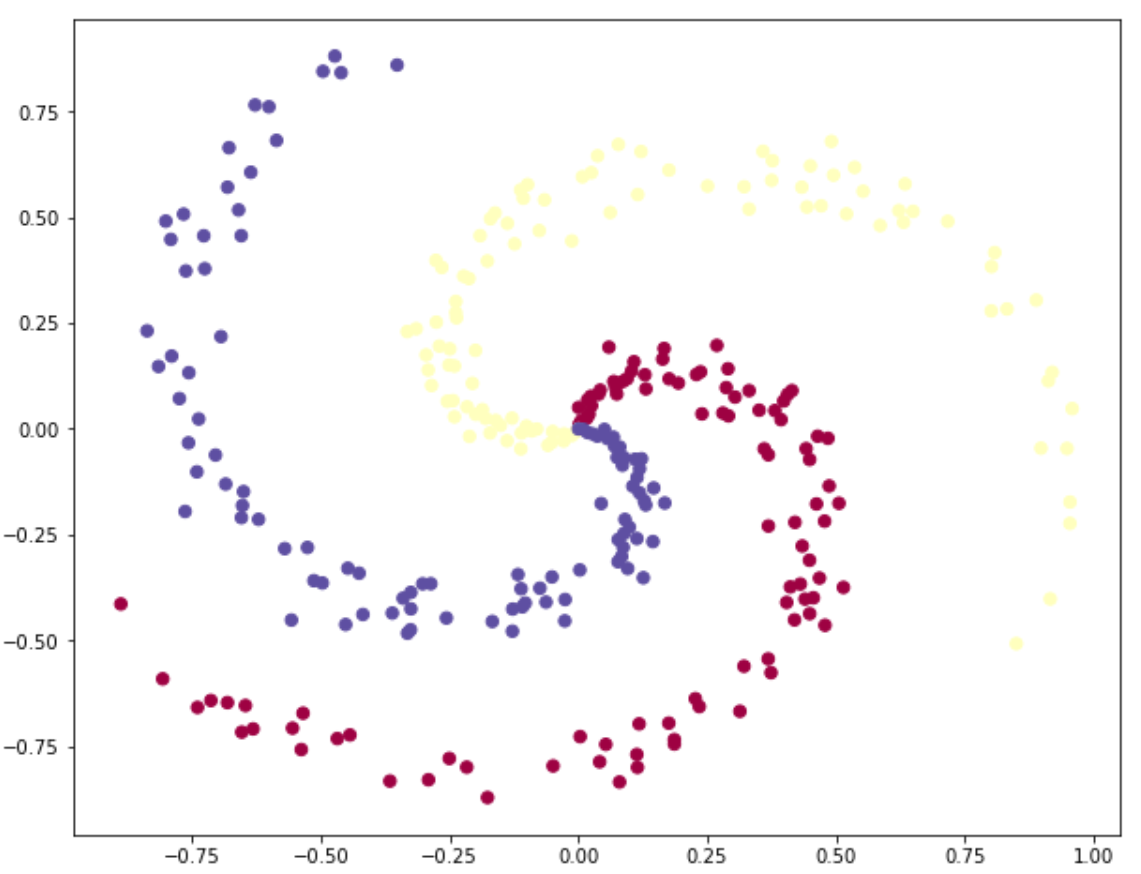
在本案例中,我们将随机生成三类样本点,要求使用分类器将这三类样本点进行分类。首先,我们将会使用普通的线性分类器(不带激活函数)来进行分类,再使用神经网络分类器(带激活函数)进行分类,最后对比两者的分类效果。在整个教程中,我会通过绘图来详细剖析分类器各层的含义和作用,再附上代码,阅读代码时,你可以对比着看分类器的结构图
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10.0, 8.0)
# 初始化参数
np.random.seed(0)
N = 100 # 每个类中的样本点
D = 2 # 维度
K = 3 # 类别个数
X = np.zeros((N*K, D)) # (300, 2)
y = np.zeros(N*K, dtype='uint8')
for j in range(K):
ix = range(N*j, N*(j+1))
r = np.linspace(0.0, 1, N) # 在0.0到1.0之间返回间隔均匀的N个数字
t = np.linspace(j*4, (j+1)*4, N) + np.random.randn(N)*0.2
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)] # 按行连接两个矩阵
y[ix] = j
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
线性分类器
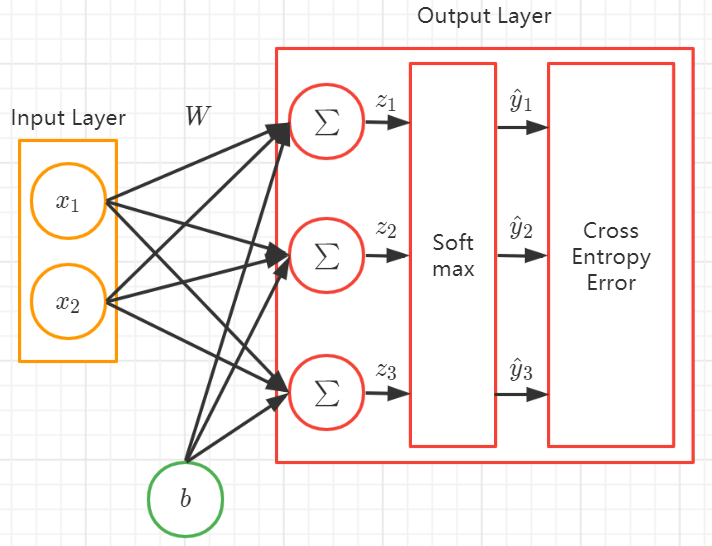
神经元
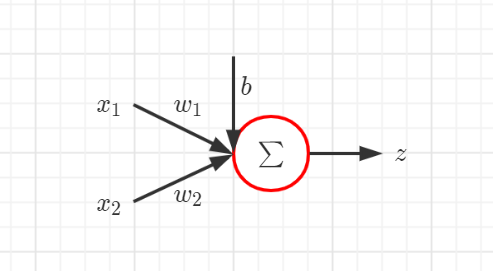
单个神经元的输出
z i = ∑ i x i w i + b z_i = sum_i x_i w_i + b zi=i∑xiwi+b
其中 x i x_i xi 表示样本的第 i i i 个特征, w i w_i wi 表示连接到该神经元的第 i i i 个权重, b b b 表示偏置, z i z_i zi 表示该神经元的输出
以此类推,可得到整个网络的矩阵表示
Z = X W + b pmb{Z} = pmb{X} pmb{W} + pmb{b} ZZZ=XXXWWW+bbb
梯度
∂ Z ∂ W = ∂ ( X W + b ) ∂ W = X ⊤ frac{partial pmb{Z}}{partial pmb{W}} = frac{partial (pmb{X} pmb{W} + pmb{b})}{partial pmb{W}} = pmb{X}^top ∂WWW∂ZZZ=∂WWW∂(XXXWWW+bbb)=XXX⊤
∂ Z ∂ b = ∂ ( X W + b ) ∂ b = I frac{partial pmb{Z}}{partial pmb{b}} = frac{partial (pmb{X} pmb{W} + pmb{b})}{partial pmb{b}} = pmb{I} ∂bbb∂ZZZ=∂bbb∂(XXXWWW+bbb)=III
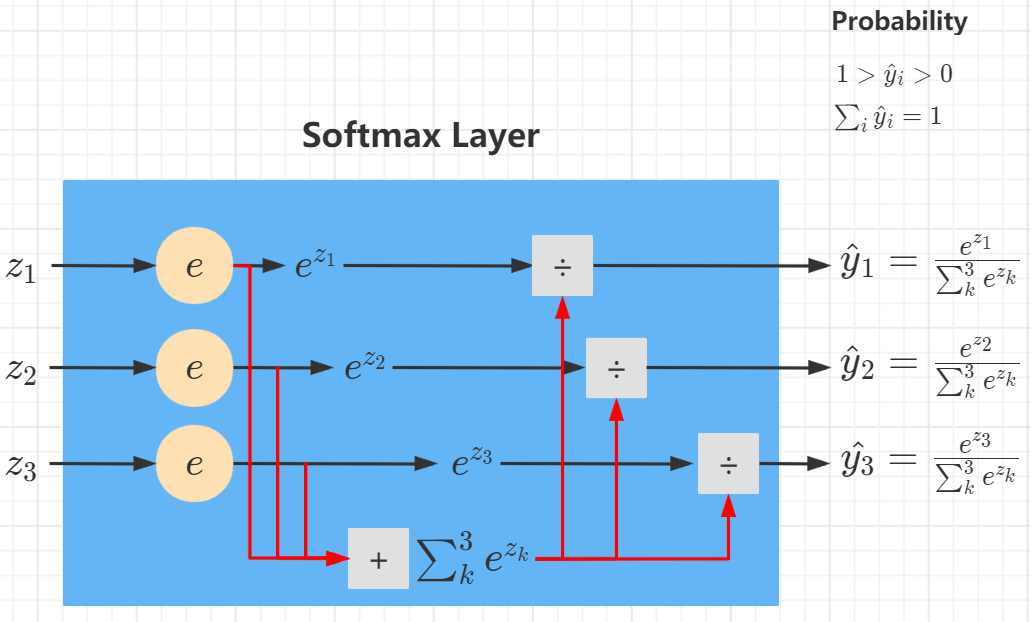
Softmax
S i = y ^ i = e z i ∑ k e z k S_i = hat{y}_i = frac{e^{z_i}}{sum_k e^{z_k}} Si=y^i=∑kezkezi
其中 z i z_i zi 是第 i i i 个输出单元的输出, y ^ i hat{y}_i y^i 是 z i z_i zi 经过 Softmax 转换后得到的概率值,表示样本属于第 i i i 个类别的概率
梯度
若 j = i j = i j=i
∂ S j ∂ z i = ∂ S i ∂ z i = ∂ ( e z i ∑ k e z k ) ∂ z i = ∑ k e z k e z i − ( e z i ) 2 ∑ k ( e z k ) 2 = ( e z i ∑ k e z k ) ( 1 − e z i ∑ k e z k ) = S i ( 1 − S i ) frac{partial S_j}{partial z_i} = frac{partial S_i}{partial z_i} = frac{partial (frac{e^{z_i}}{sum_k e^{z_k}})}{partial z_i} = frac{sum_k e^{z_k} e^{z_i} - (e^{z_i})^2}{sum_k (e^{z_k})^2} = (frac{e^{z_i}}{sum_k e^{z_k}}) (1 - frac{e^{z_i}}{sum_k e^{z_k}}) = S_i (1 - S_i) ∂zi∂Sj=∂zi∂Si=∂zi∂(∑kezkezi)=∑k(ezk)2∑kezkezi−(ezi)2=(∑kezkezi)(1−∑kezkezi)=Si(1−Si)
若 j ≠ i j neq i j=i
∂ S j ∂ z i = ∂ ( e z j ∑ k e z k ) ∂ z i = − e z j ( 1 ∑ k e z k ) 2 e z i = − S i S j frac{partial S_j}{partial z_i} = frac{partial (frac{e^{z_j}}{sum_k e^{z_k}})}{partial z_i} = - e^{z_j} (frac{1}{sum_k e^{z_k}})^2 e^{z_i} = - S_i S_j ∂zi∂Sj=∂zi∂(∑kezkezj)=−ezj(∑kezk1)2ezi=−SiSj
交叉熵损失
损失函数
L i = − y i ln y ^ i = − y i ln S i L_i = - y_i ln hat{y}_i = - y_i ln S_i Li=−yilny^i=−yilnSi
L = ∑ i L i = − ∑ i y i ln S i L = sum_i L_i = - sum_i y_i ln S_i L=i∑Li=−i∑yilnSi
其中 i i i 表示第 i i i 个类别,若样本的真实类别为 i i i,则 y i y_i yi 为 1,否则为 0
梯度
∂ L i ∂ S i = ∂ ( − y i ln S i ) ∂ S i = − y i 1 S i frac{partial L_i}{partial S_i} = frac{partial (- y_i ln S_i)}{partial S_i} = - y_i frac{1}{S_i} ∂Si∂Li=∂Si∂(−yilnSi)=−yiSi1
∂ L ∂ z i = ∑ j ∂ L j ∂ S j ∂ S j ∂ z i = ∑ j = i ∂ L j ∂ S j ∂ S j ∂ z i + ∑ j ≠ i ∂ L j ∂ S j ∂ S j ∂ z i = − y i S i S i ( 1 − S i ) + ∑ j ≠ i y j S j S i S j = − y i + y i S i + ∑ j ≠ i y j S i = − y i + S i ∑ j y j begin{aligned} frac{partial L}{partial z_i} =& sum_j frac{partial L_j}{partial S_j} frac{partial S_j}{partial z_i} \ =& sum_{j=i} frac{partial L_j}{partial S_j} frac{partial S_j}{partial z_i} + sum_{j neq i} frac{partial L_j}{partial S_j} frac{partial S_j}{partial z_i} \ =& - frac{y_i}{S_i} S_i(1 - S_i) + sum_{j neq i} frac{y_j}{S_j} S_i S_j \ =& - y_i + y_i S_i + sum_{j neq i} y_j S_i \ =& - y_i + S_i sum_j y_j \ end{aligned} ∂zi∂L=====j∑∂Sj∂Lj∂zi∂Sjj=i∑∂Sj∂Lj∂zi∂Sj+j=i∑∂Sj∂Lj∂zi∂Sj−SiyiSi(1−Si)+j=i∑SjyjSiSj−yi+yiSi+j=i∑yjSi−yi+Sij∑yj
针对分类问题,我们给定的结果 y i y_i yi 最终只会有一个类别是 1,其他类别都是 0,因此,对于分类问题,梯度等于
∂ L ∂ z i = S i − y i = y ^ i − y i frac{partial L}{partial z_i} = S_i - y_i = hat{y}_i - y_i ∂zi∂L=Si−yi=y^i−yi
正则化惩罚项
L 2 = λ 2 ∑ i ∑ j w i j 2 L_2 = frac{lambda}{2} sum_i sum_j w^2_{ij} L2=2λi∑j∑wij2
梯度
∂ L 2 ∂ w i j = λ w i j frac{partial L_2}{partial w_{ij}} = lambda w_{ij} ∂wij∂L2=λwij
矩阵形式
∂ L 2 ∂ W = λ W frac{partial L_2}{partial pmb{W}} = lambda pmb{W} ∂WWW∂L2=λWWW
其中 λ lambda λ 为正则化系数
# 单层神经网络
# 初始化参数
W = 0.01 * np.random.randn(D, K) # 随机初始化参数 (2, 3)
b = np.zeros((1, K)) # (1, 3)
step_size = 1e-0 # 1.0,学习率
reg = 1e-3 # 0.001,正则化系数
num_examples = X.shape[0] # 样本个数
# 训练
for i in range(1000):
# 前向传播
scores = np.dot(X, W) + b # (300, 3)
# softmax
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # 计算类别概率 (300, 3)
# 交叉熵损失
corect_logprobs = -np.log(probs[range(num_examples), y])
data_loss = np.sum(corect_logprobs) / num_examples # 对所有样本的损失进行求和,取均值
# 正则化惩罚项
reg_loss = 0.5 * reg * np.sum(W*W)
loss = data_loss + reg_loss
if i % 100 == 0:
print('iteration %d: loss %f' % (i, loss))
# 计算损失梯度 dL/dz
dscores = probs
dscores[range(num_examples), y] -= 1
dscores /= num_examples # 将一批数据产生的梯度取平均
# 计算在W,b上的梯度
dW = np.dot(X.T, dscores) # (2, 3)
db = np.sum(dscores, axis=0, keepdims=True) # (1, 3)
# 加上正则项梯度
dW += reg * W
# 参数更新
W += -step_size * dW
b += -step_size * db

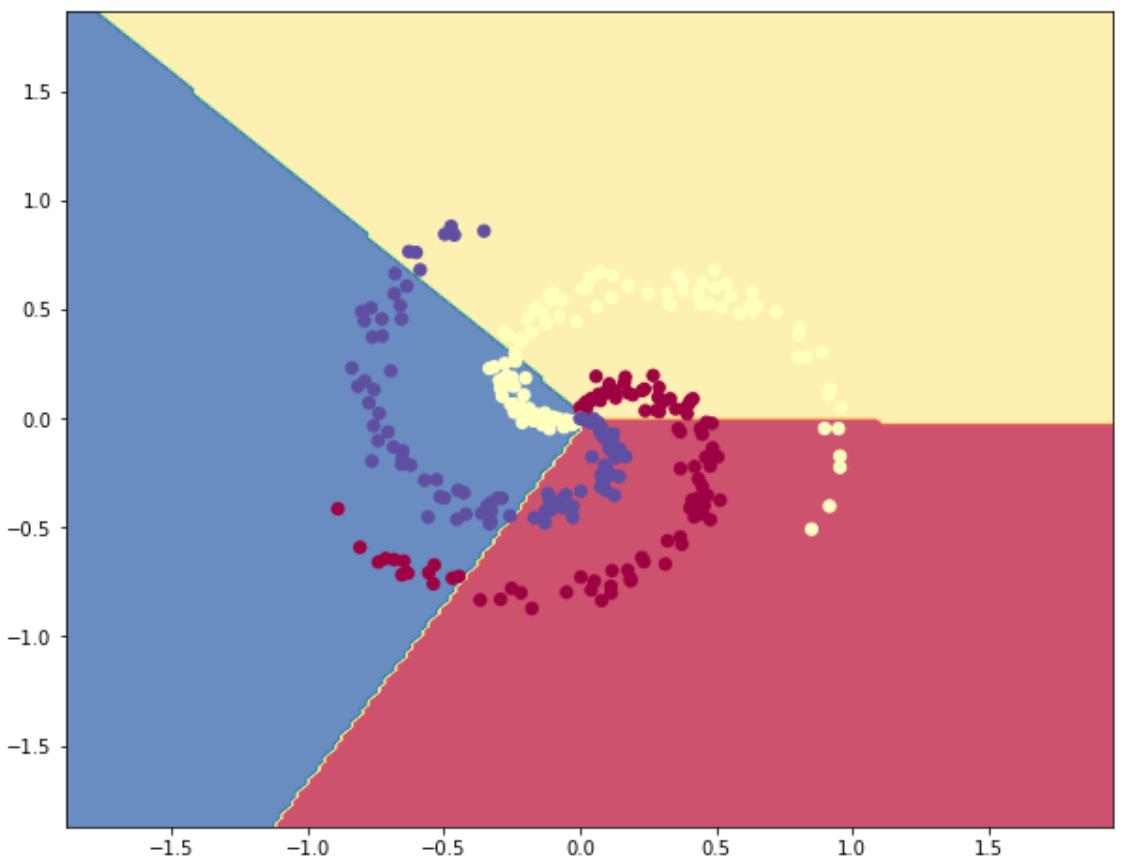
scores = np.dot(X, W) + b
predicted_class = np.argmax(scores, axis=1) # 概率最大的类别的下标
print('training accuracy: %.2f' % (np.mean(predicted_class == y))) # 准确率
training accuracy: 0.49
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = np.dot(np.c_[xx.ravel(), yy.ravel()], W) + b # ravel将多维数组降为一维
Z = np.argmax(Z, axis=1) # 取概率最高的类别
Z = Z.reshape(xx.shape)
fig = plt.figure()
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8) # 绘制三维等高线
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()
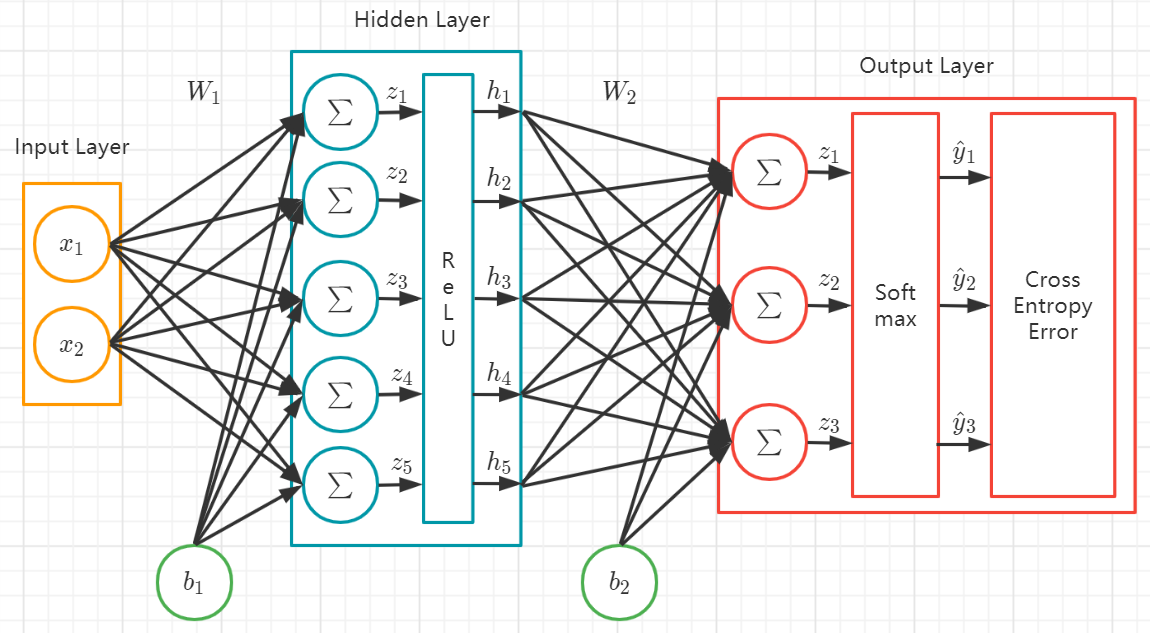
神经网络分类器
ReLU 激活单元
r = m a x ( 0 , x ) r = max(0, x) r=max(0,x)
梯度
d r d x = { 0 x < = 0 1 x > 0 frac{d r}{d x} = begin{cases} 0 & x <= 0 \ 1 & x > 0 \ end{cases} dxdr={01x<=0x>0
# 两层神经网络
# 初始化参数
h = 100 # 隐层大小(神经元个数)
W = 0.01 * np.random.randn(D, h)
b = np.zeros((1, h))
W2 = 0.01 * np.random.randn(h, K)
b2 = np.zeros((1, K))
step_size = 1e-0 # 学习率
reg = 1e-3 # 正则化系数
num_examples = X.shape[0] # 样本个数
# 训练
for i in range(10000):
# 前向传播
hidden_layer = np.maximum(0, np.dot(X, W) + b) # 使用 ReLU 激活函数
scores = np.dot(hidden_layer, W2) + b2
# softmax
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # 计算类别概率
# 交叉熵损失
corect_logprobs = -np.log(probs[range(num_examples), y])
data_loss = np.sum(corect_logprobs) / num_examples
# 正则化惩罚项
reg_loss = 0.5*reg*np.sum(W*W) + 0.5*reg*np.sum(W2*W2)
loss = data_loss + reg_loss
if i % 1000 == 0:
print("iteration %d: loss %f" % (i, loss))
# 计算损失梯度 dL/dz
dscores = probs
dscores[range(num_examples), y] -= 1
dscores /= num_examples
# 计算在W2,b2上的梯度
dW2 = np.dot(hidden_layer.T, dscores)
db2 = np.sum(dscores, axis=0, keepdims=True)
dhidden = np.dot(dscores, W2.T)
# ReLU 激活函数梯度
dhidden[hidden_layer <= 0] = 0
# 计算最后在W,b上的梯度
dW = np.dot(X.T, dhidden)
db = np.sum(dhidden, axis=0, keepdims=True)
# 加上正则项梯度
dW2 += reg * W2
dW += reg * W
# 参数更新
W += -step_size * dW
b += -step_size * db
W2 += -step_size * dW2
b2 += -step_size * db2

# 计算分类准确度
hidden_layer = np.maximum(0, np.dot(X, W) + b)
scores = np.dot(hidden_layer, W2) + b2
predicted_class = np.argmax(scores, axis=1)
print('training accuracy: %.2f' % (np.mean(predicted_class == y)))
training accuracy: 0.98
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = np.dot(np.maximum(0, np.dot(np.c_[xx.ravel(), yy.ravel()], W) + b), W2) + b2
Z = np.argmax(Z, axis=1)
Z = Z.reshape(xx.shape)
fig = plt.figure()
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()
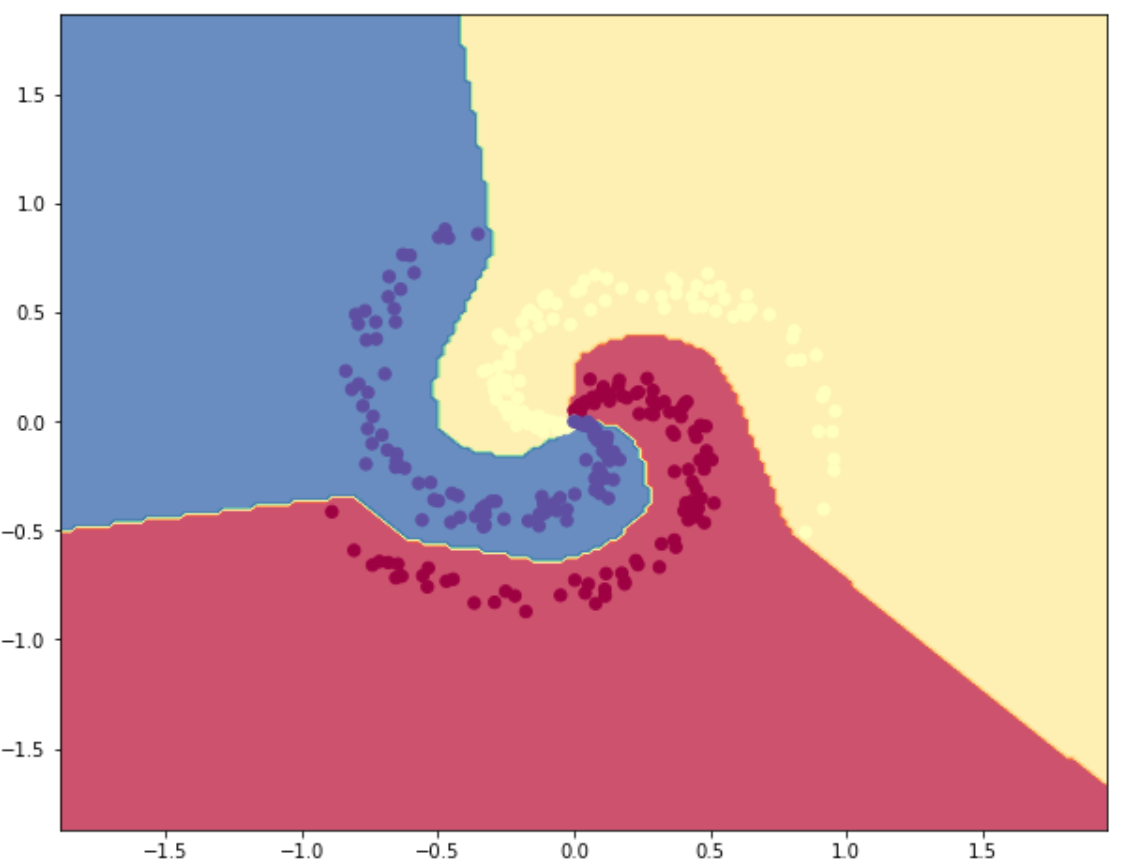
可以看到,神经网络由于引入了激活函数从而提升了分类器的非线性分类能力,由此我们可以感受到神经网络的强大魅力
完结,撒花!
最后
以上就是靓丽黄豆最近收集整理的关于神经网络入门案例保姆级教程的全部内容,更多相关神经网络入门案例保姆级教程内容请搜索靠谱客的其他文章。








发表评论 取消回复