一、环境介绍
Ubuntu16.04操作系统
Hadoop3.1.3
Eclipse 编译器
二、数据来源及数据上传
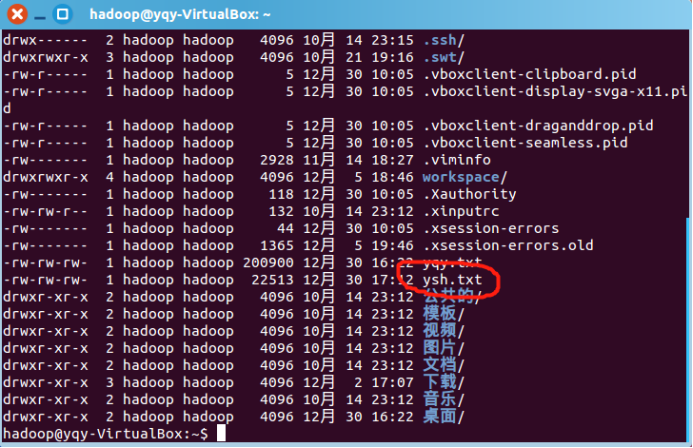
准备一个待分析的文件(10000字英文单词文件,可从网上找英文文章),命名为ysh.txt。将文件放到/home/Hadoop文件下:
三、数据上传结果查看
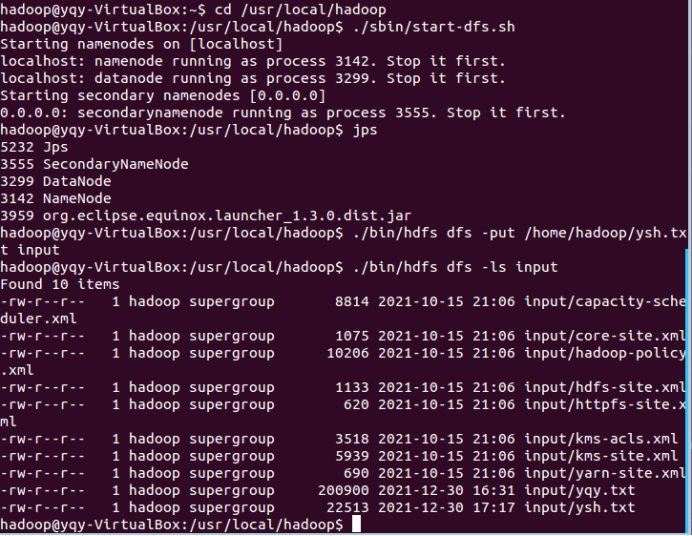
1.将实验的文本文件上传到HDFS中,并查看文件上传情况(请确保Hadoop为开启状态)
四、数据处理过程的描述
1.安装并打开eclipse

2.配置 Hadoop-Eclipse-Plugin
3.为项目添加需要用到的JAR包
4.在 Eclipse 中操作 HDFS 中的文件
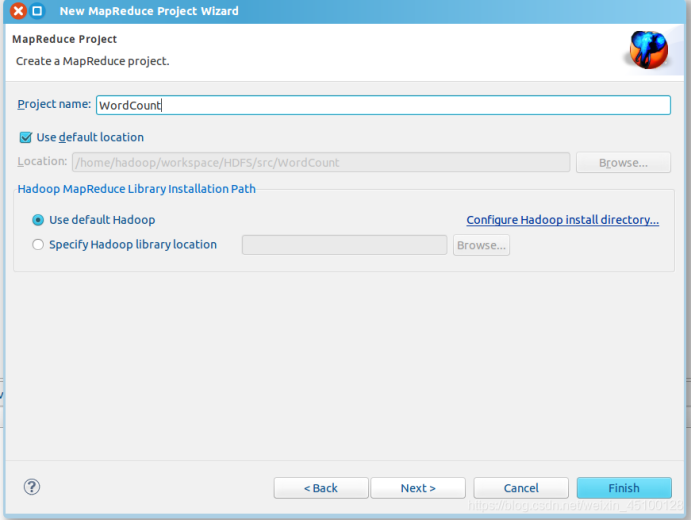
5.在 Eclipse 中创建 MapReduce项目:首先,点击File菜单,选择New—Project,然后选择Map/Reduce Project,点击Next,最后,填写项目名称,此处用本实验WordCount作为项目名。填写完后点击Finish即可。
6.编写 Java 应用程序并翻译
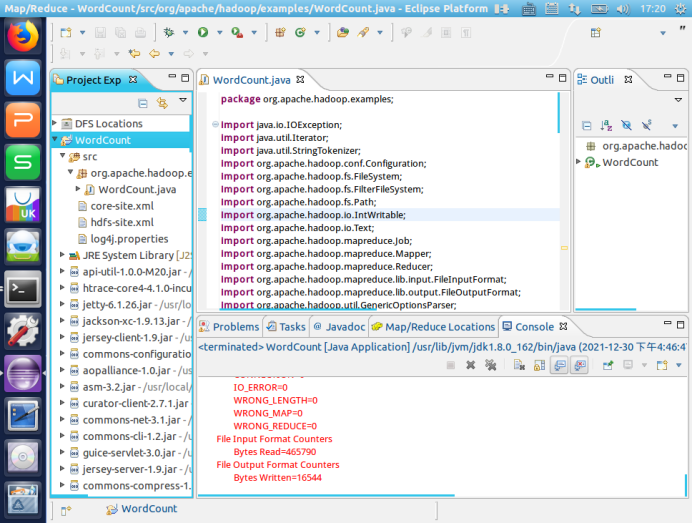
7.把 Java 应用程序打包生成 JAR 包,部署到 Hadoop 平台上运行。把词频统计程序放在“/usr/local/hadoop/myapp”目录下
8.在 Eclipse 工作界面左侧的“Package Explorer”面板中,在工程名称“WordCount” 上点击鼠标右键,选择“Export”
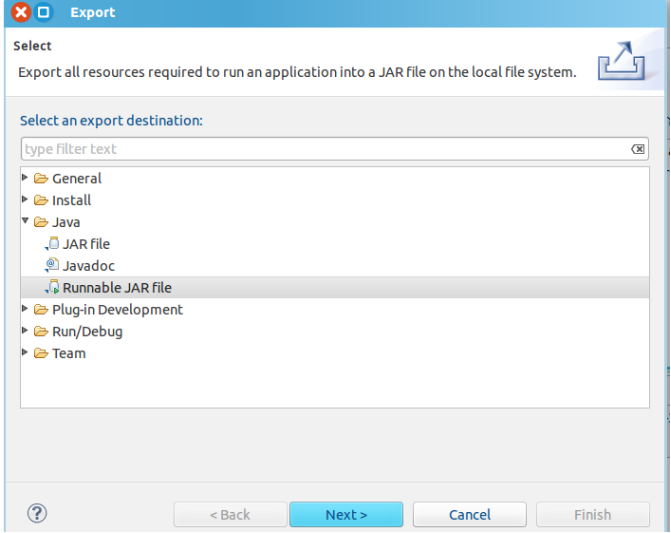
9.在该界面中,选择“Runnable JAR file”,然后,点击“Next>”按钮
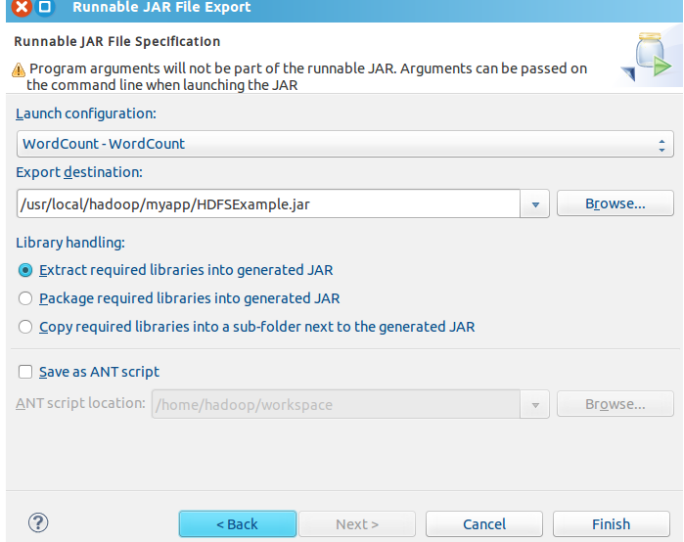
五、处理结果的下载及命令行展示
1.使用 hadoop jar 命令运行程序

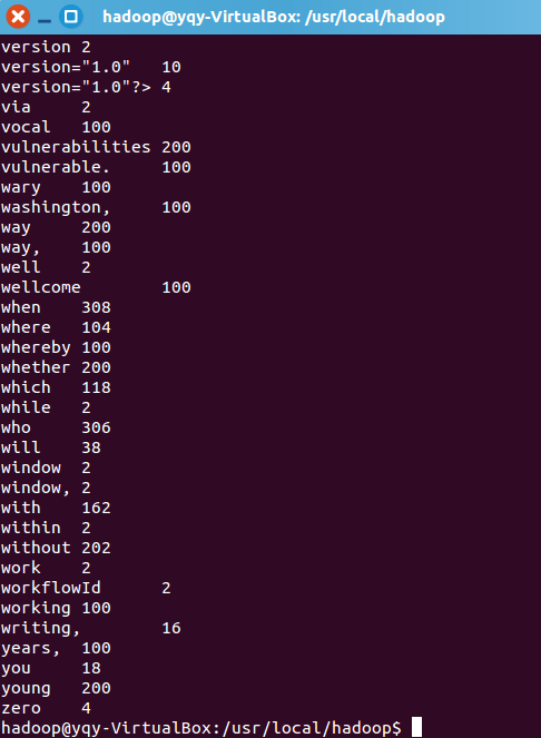
2.查看 output 文件夹是否有运行成功后生成的文件以及查看运行后生成的 output/part-r-00000 这个文件

3.将 output 文件夹下载至本地
![]()
4.查看 part-r-00000 文件
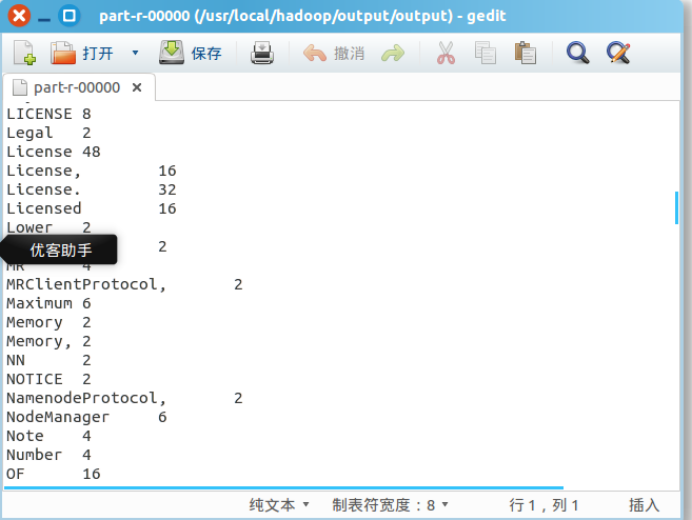
最后
以上就是闪闪巨人最近收集整理的关于调用MapReduce对文件中各个单词出现的次数进行统计。的全部内容,更多相关调用MapReduce对文件中各个单词出现内容请搜索靠谱客的其他文章。








发表评论 取消回复