OutputFormat的使用场景:
为了实现控制最终文件的输出路径和输出格式,可以自定义OutputFormat。
例如:要在一个MapReducer程序中根据数据的不同输出结果到不同目录,这类灵活的输出要求可以通过自定义OutputFormat来实现。
自定义OutputFormat大致步骤:
(1)自定义一个类继承FileOutputFormat;
(2)改写RecordWriter,具体改写输出数据的write()方法。
测试数据:
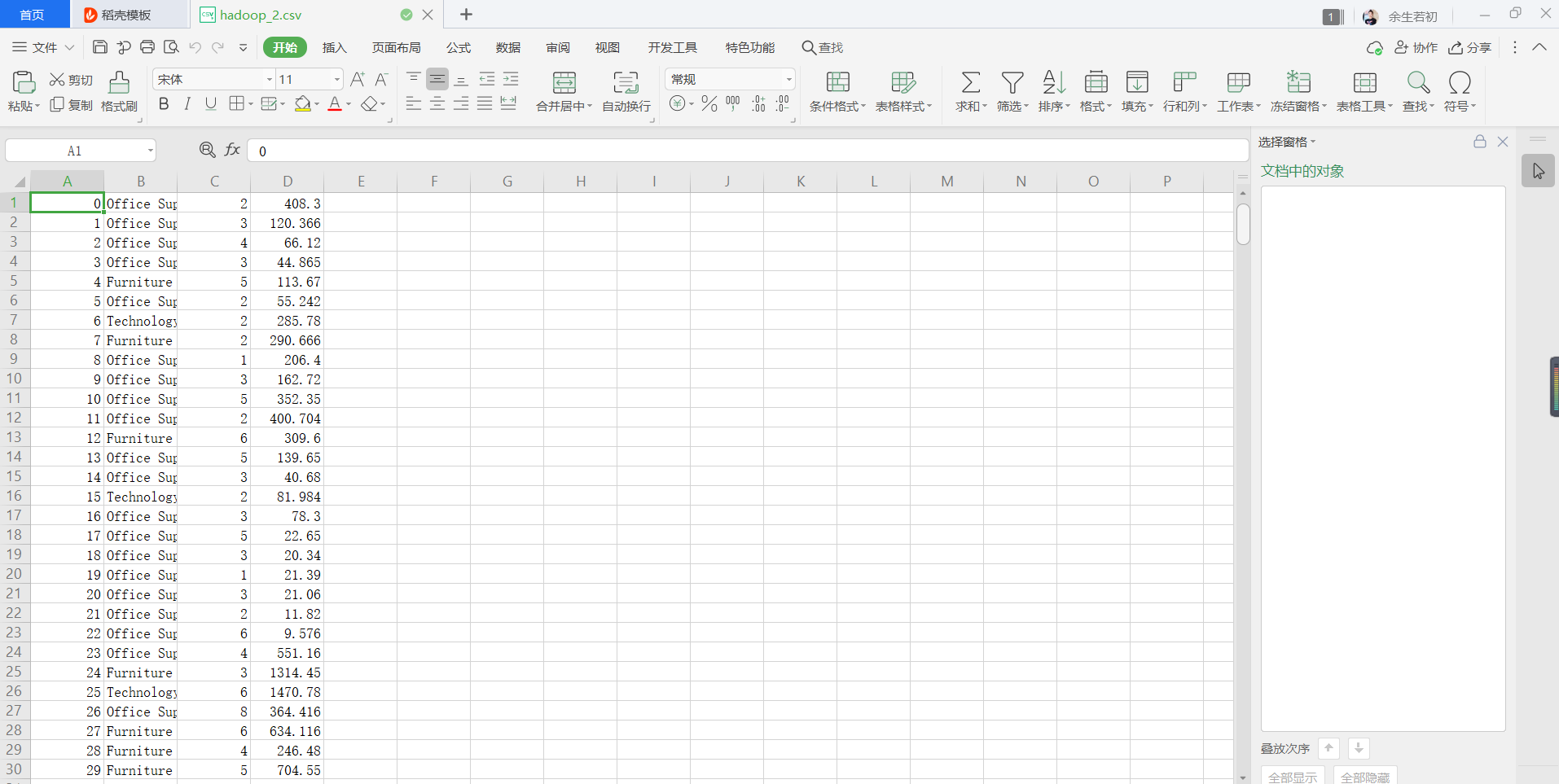
1). 实体类:
package com.root.outputformat;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FilterBean implements WritableComparable<FilterBean> {
private String Commodity; //种类
private Double price; //商品价格
//空参构造
public FilterBean() {
super();
}
public FilterBean(String commodity, Double price) {
Commodity = commodity;
this.price = price;
}
public int compareTo(FilterBean filterBean) {
int result = Commodity.compareTo(filterBean.getCommodity()); //按照Ascill表进行比较
//种类进行升序排序
if (result > 0) {
result = 1;
} else if (result < 0) {
result = -1;
} else {
//销售额进行降序排序
if (price > filterBean.getPrice()) {
result = -1;
} else if (price < filterBean.getPrice()) {
result = 1;
} else {
result = 0;
}
}
return result;
}
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(Commodity);
dataOutput.writeDouble(price);
}
public void readFields(DataInput dataInput) throws IOException {
Commodity = dataInput.readUTF();
price = dataInput.readDouble();
}
public String getCommodity() {
return Commodity;
}
public void setCommodity(String commodity) {
Commodity = commodity;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
@Override
public String toString() {
return Commodity + "t"+ price + "rn";
}
}
2)Map程序:
package com.root.outputformat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FilterMap extends Mapper<LongWritable, Text, FilterBean, NullWritable> {
FilterBean filterbean = new FilterBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 0 Office Supplies 2 408.3
//1.获取一行
String line = value.toString();
//2.切割
String[] fields = line.split(",");
//3.封装
String Commodity = fields[1];
Double price = Double.parseDouble(fields[3]);
filterbean.setCommodity(Commodity);
filterbean.setPrice(price);
//4.写出
context.write(filterbean, NullWritable.get());
}
}
3)reduce程序
package com.root.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FilterReduce extends Reducer<FilterBean, NullWritable, FilterBean, NullWritable> {
@Override
protected void reduce(FilterBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
for (NullWritable value : values) {
context.write(key,NullWritable.get());
}
}
}
4).自定义outputformat需要继承FileOutputFormat,重写getRecordWriter方法
package com.root.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FilterOutputFormat extends FileOutputFormat<FilterBean, NullWritable> {
public RecordWriter<FilterBean, NullWritable> getRecordWriter(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
return new FRecorWriter(taskAttemptContext);
}
}
5).实现RecordWriter抽象类.
package com.root.outputformat;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
public class FRecorWriter extends RecordWriter<FilterBean, NullWritable> {
FileSystem fs;
FSDataOutputStream fosOffice, fosFurniture, fosTechnology, fosOther;
public FRecorWriter(TaskAttemptContext taskAttemptContext) {
try {
//1. 获取文件系统
fs = FileSystem.get(taskAttemptContext.getConfiguration());
//2.创建输出到Office Supplies.txt的输出流
fosOffice = fs.create(new Path("F:\scala\Workerhdfs\output10\ffice Supplies.txt"));
//3.创建输出到Furniture.txt的输出流
fosFurniture = fs.create(new Path("F:\scala\Workerhdfs\output10\Furniture.txt"));
//4.创建输出到Technology.txt的输出流
fosTechnology = fs.create(new Path("F:\scala\Workerhdfs\output10\Technology.txt"));
//5.创建输出到Other.txt的输出流
fosOther = fs.create(new Path("F:\scala\Workerhdfs\output10\Other.txt"));
} catch (IOException e) {
e.printStackTrace();
}
}
public void write(FilterBean filterBean, NullWritable nullWritable) throws IOException, InterruptedException {
String line = filterBean.toString();
if (line.contains("Office Supplies")) {
fosOffice.write(line.getBytes());
} else if (line.contains("Furniture")) {
fosFurniture.write(line.getBytes());
} else if (line.contains("Technology")) {
fosTechnology.write(line.getBytes());
} else {
fosOther.write(line.getBytes());
}
}
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
IOUtils.closeStream(fosOffice);
IOUtils.closeStream(fosFurniture);
IOUtils.closeStream(fosTechnology);
IOUtils.closeStream(fosOther);
}
}
根据操作系统选择合适的输出路径,我的测试环境是windows系统我都把文件写入这个目录下F:scalaWorkerhdfsoutput10,jar包运行到linux系统需要更换路径
6)二次排序(辅助排序):
package com.root.outputformat;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class FilterGroupComparator extends WritableComparator {
protected FilterGroupComparator(){
super(FilterBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
//只要种类相同,就认为是相同的key
FilterBean aBean = (FilterBean) a;
FilterBean bBean = (FilterBean) b;
int result = aBean.getCommodity().compareTo(bBean.getCommodity());
if (result > 0) {
result = 1;
} else if (result < 0) {
result = -1;
} else {
result = 0;
}
return result;
}
}
这一块看不懂可以看我之前二次排序的案例(小编也是无聊,才将二次排序融入到自定义outputformat案例中)
7).主程序:
package com.root.outputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FilterDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"F:\scala\Workerhdfs\input5","F:\scala\Workerhdfs\output10"};
//1.获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.设置jar路径
job.setJarByClass(FilterDriver.class);
//3.关联mapper和reducer
job.setMapperClass(FilterMap.class);
job.setReducerClass(FilterReduce.class);
//4 设置mapper输出的key和value类型
job.setMapOutputKeyClass(FilterBean.class);
job.setMapOutputValueClass(NullWritable.class);
//5. 设置最终输出的key和value类型
job.setOutputKeyClass(FilterBean.class);
job.setOutputValueClass(NullWritable.class);
//设置 reduce端的分组
job.setGroupingComparatorClass(FilterGroupComparator.class);
//自定义的输出格式组件设置到job中
job.setOutputFormatClass(FilterOutputFormat.class);
//6.设置输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//7.提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
由于我的测试文件中第二列除了Furniture,Office Supplies,Technology字段没有其他的字段,Other.txt文件内容为空
效果如下:
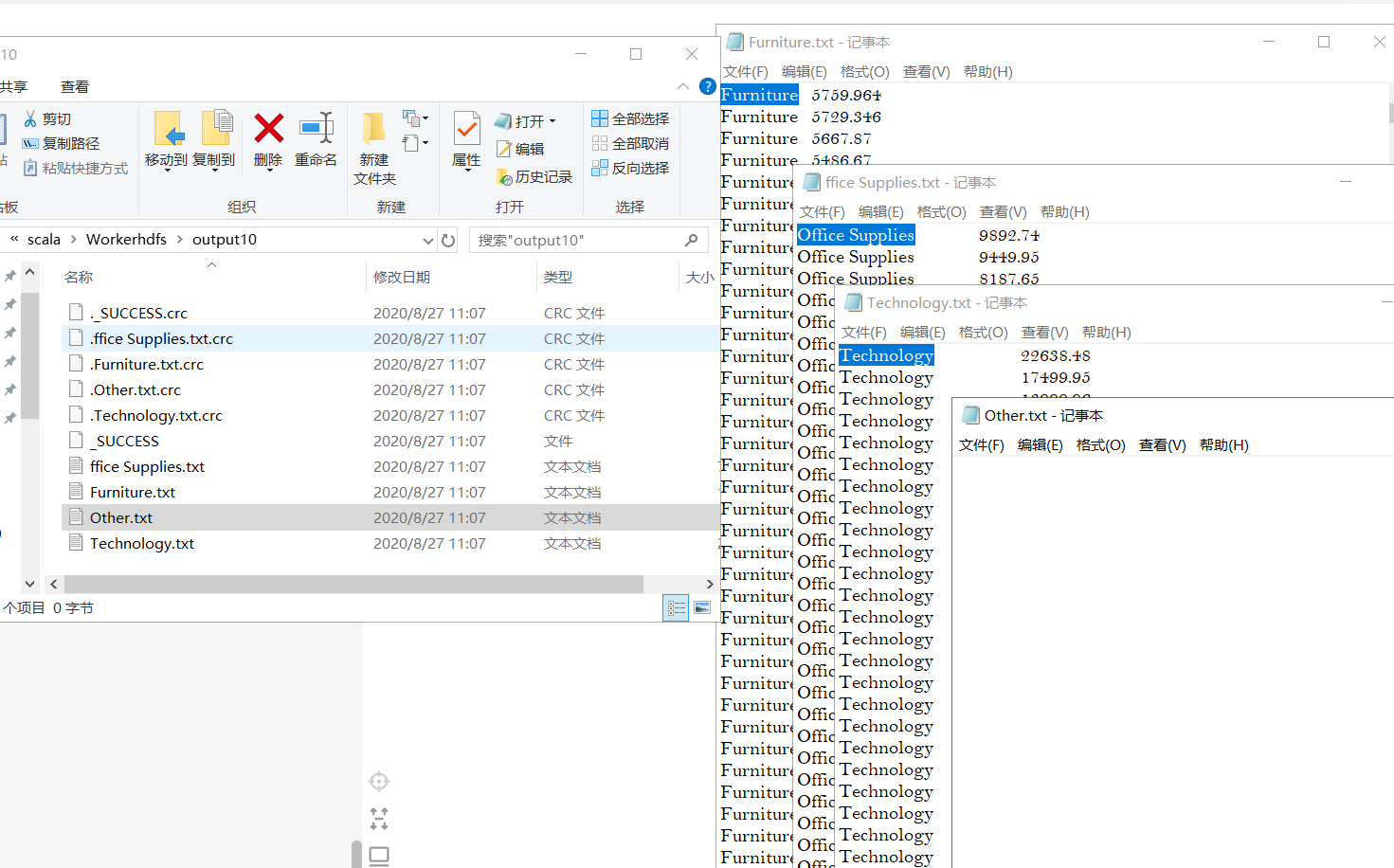
数据有点多,linux系统运行此脚本,查看每个文件的前五行(Other查看所有,反正它也是空)
打包在yarn上运行

查看文件内容前五行:

最后
以上就是魁梧发夹最近收集整理的关于Hadoop自定义outputformat输出文件格式的全部内容,更多相关Hadoop自定义outputformat输出文件格式内容请搜索靠谱客的其他文章。








发表评论 取消回复