1.情境描述:用于电影分类,一个电影可以属于好几类。 按类型统计片子数。
2.实现步骤:读文件->统计分类->全0数组(行,列)->赋值为1->各列求和
3.知识点: 3.1嵌套 [ [ ],[ ],[ ],[ ] ] 读值
3.2 全0数组 创建N*M数组
3.3对应项赋值为1
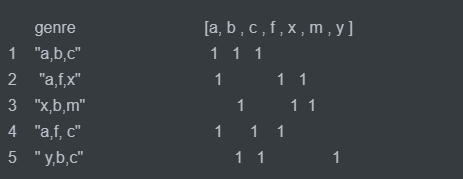
知识点: 1.list 嵌套 [ [ ],[ ],[ ],[ ] ] 读值
l= [[a,b,c]
[a,f,x]
[x,b,m]
[a,f,c]
[y,b,c]]
list(set([i for j in temp_list for i in j ]))
2. 全0数组 创建N*M数组
1.创建一个4*3的数组
np.array(np.arange(12)).reshape(4, 3)
"""
输出
[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]
"""
2.创建一个4*3的全零数组
zeros(shape, dtype=float, order='C')
np.zeros((4, 3))
"""
输出
[ 0. 0. 0.]
[ 0. 0. 0.]
[ 0. 0. 0.]
[ 0. 0. 0.]
"""
3.对应项赋值为1
#zeros_df.loc[0,["SCI-FI","musical"]]=1
for i in range(df.shape[0]):
zeros_df.loc[i,temp_list[i]]=1
流程代码:
"""
1.得到所有的分类 genre_list=[]
temp_genre_list=df["Genre"].str.split(",").tolist()
或者 tolist() to_dict() 类型数据
genre_list=[]
for i in temp_genre_list:
genre_list.extend(i)
genre_list=list(set(genre_list)) ->去重
2.构造一个全0数组
zeros_genre=pd.DataFrame(np.zeros(shape=(df.shape[0],len(genre_list)),dtype=int),colums=genre_list)
3.出现分类的地方设为1
for i in range(df.shape[0]):
genres=df["Genre"][i]
zeros_genre.loc[i,genres.split(",")]=1
"""
def fun():
#1.读取文件
filePath="./data/movie.csv"
df=pd.read_csv(filePath)
#2.统计分类的列表
temp_list=df["Genre"].str.split(",").tolist()
genre_list=list(set([i for j in temp_list for i in j ]))
#3.构造全为0的数组 行条数 列 种类
zeros_df=pd.DataFrame(np.zeros((df.shape(0),len(genre_list))),columns=genre_list)
#4.赋值为1 zeros_df.loc[0,["SCI-FI","musical"]]=1
for i in range(df.shape[0]):
zeros_df.loc[i,temp_list[i]]=1
#5.统计每个分类的电影的数量和
genre_count=zeros_df.sum(axis=0)
print(genre_count)
#6.排序
genre_count=genre_count.sort_value()
最后
以上就是文艺黑裤最近收集整理的关于python计算各类型电影的评分_python(15)-pandas-多类型统计-电影分类问题的全部内容,更多相关python计算各类型电影内容请搜索靠谱客的其他文章。








发表评论 取消回复