一:向量空间模型(VSM)
1.
向量空间模型
(VSM)
:是
最常用的相似度计算
模型
。
2.
基本思想
:
把每个特征词给看成一个维度,而词的权重看成其值(有向),即向量,这样每条媒资的特征词及其权重就构成了一个
n
维空间
图。两
个媒资的相似度就是两个空间图的接近度
。
相似度
可用向量之间的夹角或距离来表示
。
3.
计算
结果
:在
[0
,
1]
范围内,余弦值越大,两个文本的相似度就越大
。
4.
余弦
定理计算公式
如下
:
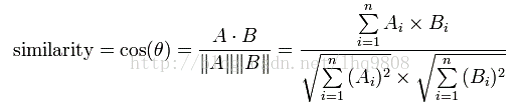
二:计算模型
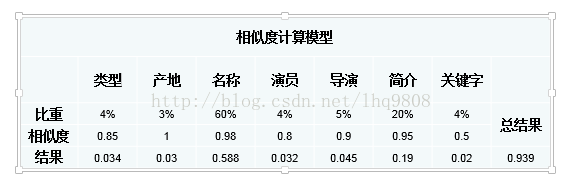
1.
计算
各项元数据的相似度值;
2.
根据各项元数据在整体计算中的重要性,决定其所占的权重比例值;
3.
各项的元数据相似度值
*
各项所占的权重比例值,再进行累加,得出最终的相似度结果
值
;
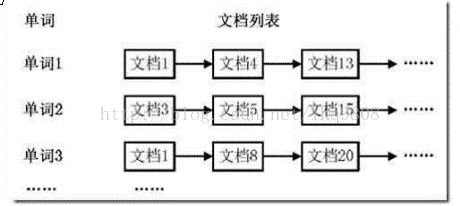
三:倒排索引
倒排索引
:
是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词或词组在一个文档或一组文件中的存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(
InvertedIndex
)。
最后
以上就是粗暴菠萝最近收集整理的关于影片内容相似度计算关键点的全部内容,更多相关影片内容相似度计算关键点内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复