查看源码:
git地址:https://github.com/champion-yang/dataAnalysis
题目要求以及完成情况:
-
1.从指定招聘网站爬取数据,提取有效数据,并保存为json格式文件。
完成情况:bossZhipin
利用scrapy框架将boss直聘的相关信息爬取下来,保存为bossData.json文件.代码查看bossZhipin文件夹 -
2.设置post请求参数并将信息返回给变量response
完成情况:postReq.py
使用了resquests,json包,将请求头,请求信息,请求地址传入到resquests请求中,注意请求方式 -
3.将提取出来的数据转化为json格式,并赋值变量
完成情况:dataToJson.py
使用了json,resquests,BeautifulSoup,爬取笔趣网小说狂神,拿到了每一章的标题和对应的链接,并转化为json格式,赋值给变量jsonObj -
4.用with函数创建json文件,通过json方法,写入json数据
完成情况:withFunBuildJson.py
使用3中拿到的json数据,通过encode()编码为二进制文件,写入build.json文件中
OK!直接上代码!
1.
使用了scrapy框架,这里给出爬虫的代码管道文件的代码
# -*- coding: utf-8 -*-
import scrapy
from bossZhipin.items import BosszhipinItem
class BossSpider(scrapy.Spider):
name = 'boss'
allowed_domains = ['zhipin.com']
offset = 1
url = 'https://www.zhipin.com/c101010100-p100109/?page='
start_urls = [ url + str(offset)]
url1 = 'https://www.zhipin.com'
def parse(self, response):
for each in response.xpath("//div[@class='job-primary']"):
item = BosszhipinItem()
item['company'] = each.xpath("./div[@class='info-company']/div/h3/a/text()").extract()[0]
item['company_link'] = self.url1 + each.xpath("./div[@class='info-company']/div/h3/a/@href").extract()[0]
item['position'] = each.xpath("./div[@class='info-primary']/h3/a/div[@class='job-title']/text()").extract()[0]
item['wages'] = each.xpath("./div[@class='info-primary']/h3/a/span[@class]/text()").extract()[0]
item['place'] = each.xpath("./div[@class='info-primary']/p/text()").extract()[0]
item['experience'] = each.xpath("./div[@class='info-primary']/p/text()").extract()[1]
yield scrapy.Request(item['company_link'],meta={'item':item},callback=self.get_company_info)
if self.offset < 10:
self.offset += 1
yield scrapy.Request(self.url + str(self.offset) , callback=self.parse)
def get_company_info(self,response):
item = response.meta['item']
company_link = item['company_link']
company_infos = response.xpath("//div[@id='main']/div[3]/div/div[2]/div/div[1]/div/text()").extract()
position_nums = response.xpath("//div[@id='main']/div[1]/div/div[1]/div[1]/span[1]/a/b/text()").extract()
for position_num,company_info in zip(position_nums,company_infos):
item['position_num'] = position_num
item['company_info'] = company_info
print(item['position_num'],item['company_info'])
yield item
import json
# dumps和
class BosszhipinPipeline(object):
def __init__(self):
self.filename = open('bossData.json','wb')
def process_item(self, item, spider):
# 将获取到的数据保存为json格式
text = json.dumps(dict(item),ensure_ascii=False) + 'n'
self.filename.write(text.encode('utf-8'))
return item
def close_spider(self,spider):
print('爬虫关闭')
self.filename.close()
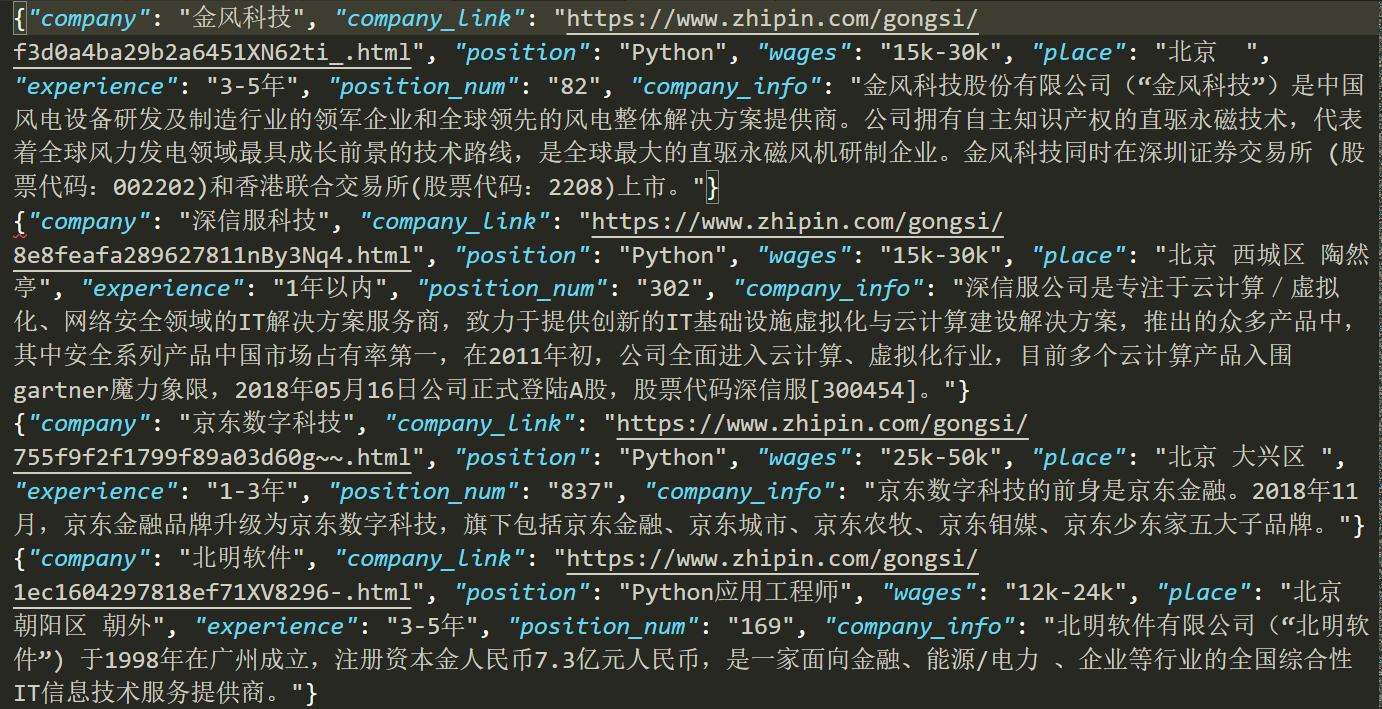
- post参数包括:请求地址,请求信息,请求头
import requests,json
url = "http://xsxxgk.huaibei.gov.cn/site/label/8888?IsAjax=1&dataType=html&_=0.27182235250895626"
data ={
"siteId":"4704161",
"pageSize":"15",
"pageIndex":"4",
"action":"list",
"isDate":"true",
"dateFormat":"yyyy-MM-dd",
"length":"46",
"organId":"33",
"type":"4",
"catId":"3827899",
"cId":"",
"result":"暂无相关信息",
"labelName":"publicInfoList",
"file":"/xsxxgk/publicInfoList-xs"
}
headers = {
"Accept":"text/html, */*; q=0.01","Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.9,en;q=0.8",
"Connection":"keep-alive",
"Content-Length":"253",
"Content-Type":"application/x-www-form-urlencoded; charset=UTF-8",
"Cookie":"SHIROJSESSIONID=f30feb26-6495-4287-a5a6-27bbd76bf960",
"Host":"xsxxgk.huaibei.gov.cn",
"Origin":"http",
"Referer":"http",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
response = requests.post(url=url,data =data,headers=headers)
# response = requests.post(url=url,data =json.dumps(data),headers=headers) # 注意請求的方式是json还是text
print(response.text)
3&4.
import json,os
import requests
from bs4 import BeautifulSoup
import time
# 获取所有的章节名和章节地址
if __name__ == '__main__':
# 拿到url地址
target = 'http://www.biquw.com/book/7627/'
req = requests.get(url=target)
# 拿到html文档
html = req.text
# 解析html文档信息
div_bf = BeautifulSoup(html) # 创建bf对象来存储html信息
div = div_bf.find_all('div',class_='book_list')
a_list = div_bf.select('div>ul>li>a')
titleList1 = []
titleList2 = []
for each in a_list:
# 拿到每一章的标题和连接
str1 = each.string
str2 = target+each.get('href')
titleList1.append(str1)
titleList2.append(str2)
d = dict(zip(titleList1,titleList2))
jsonObj = json.dumps(d).encode()
print(type(jsonObj))
with open('build.json','wb') as f:
f.write(jsonObj)
最后
以上就是贪玩大象最近收集整理的关于数据分析的小练习的全部内容,更多相关数据分析内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复