说明:爬取了b站8月综合得分前100的视频,做一个数据小练习
1导入模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False2导入数据
data = pd.read_csv(r"D:/data_set/data_set/my_data_learing/bilibili_augest_top100.csv",encoding="utf-8")
data.head()
3数据处理
# 数据描述
data.shape![]()
data.dtypes
问题1:将播放量和弹幕量的格式改为浮点型数据,需要去掉单位
data["播放量"] = data['播放量'].str.replace('万','').astype(float)
data["弹幕量"] = data['弹幕量'].str.replace('万','').astype(float)此时,两个属性的值都是float格式。
问题2:弹幕量属性中,有部分数据的单位不是万,找出这部分数据然后除以10000
data["弹幕量"] = data["弹幕量"].apply(lambda x: x/10000 if x>50 else x)
问题3:修改columns名称
data.rename(columns={"播放量":"播放量(万)","弹幕量":"弹幕量(万)"},inplace=True)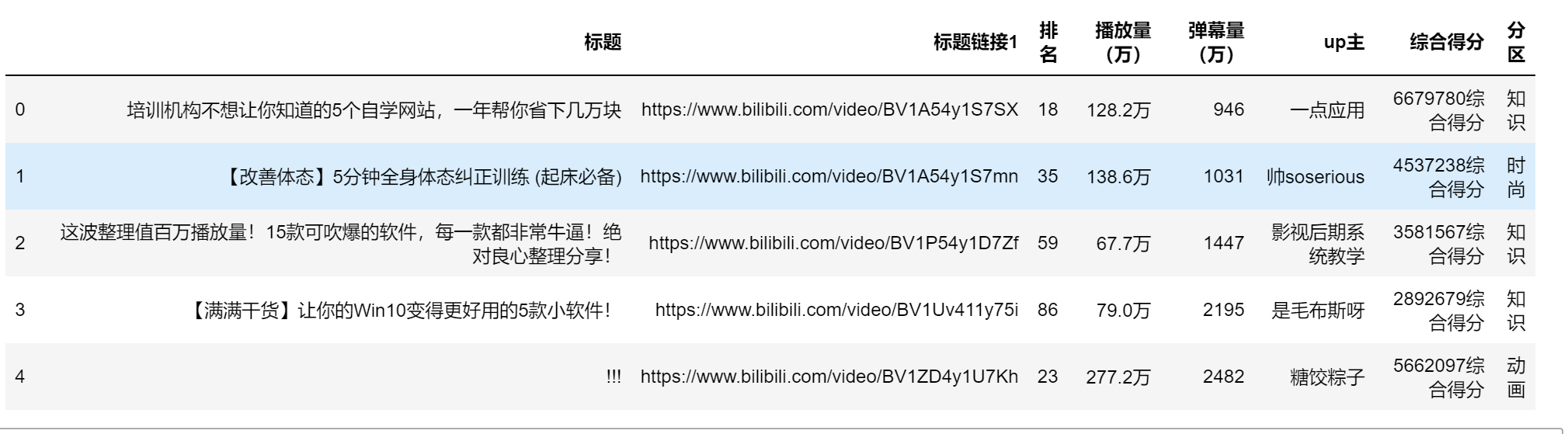
4数据可视化
# 查看分组后各分区对应数目
data_class = data.groupby("分区").size()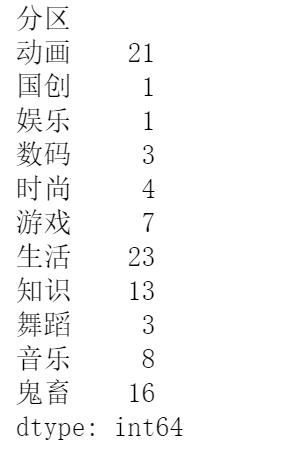
问题3:各分区数量
fig, axes = plt.subplots(1,1)
data_class.plot(kind='bar')
x = np.arange(data_class.shape[0])
for x,y in zip(x,data_class.values):
plt.text(x,y+0.05, "{:.0f}".format(y),ha="center")
plt.ylabel("数量")
plt.title('各分区数量')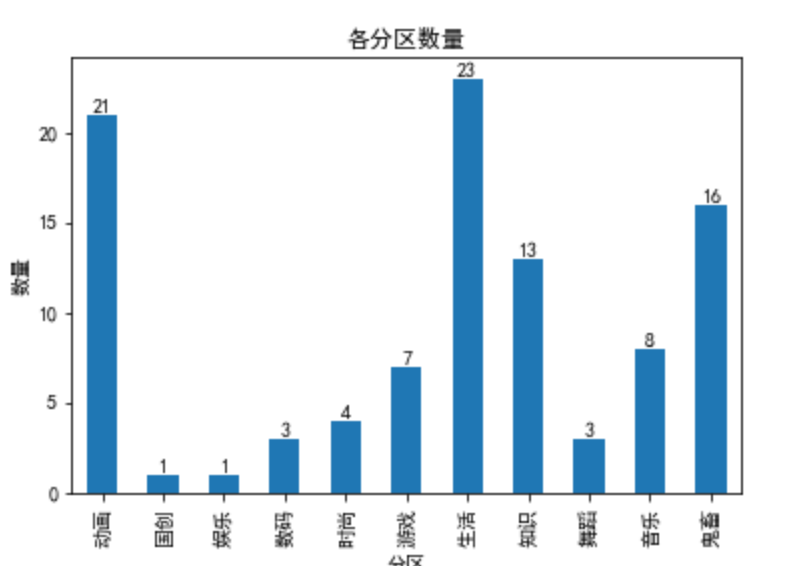
结论:由此图可以看出排在前三的有生活类、动画类和鬼畜类视频,这个结果很bilibili。
问题4:弹幕量与播放量对比
data_class_playnum = data.groupby('分区')[['播放量','弹幕量']].sum()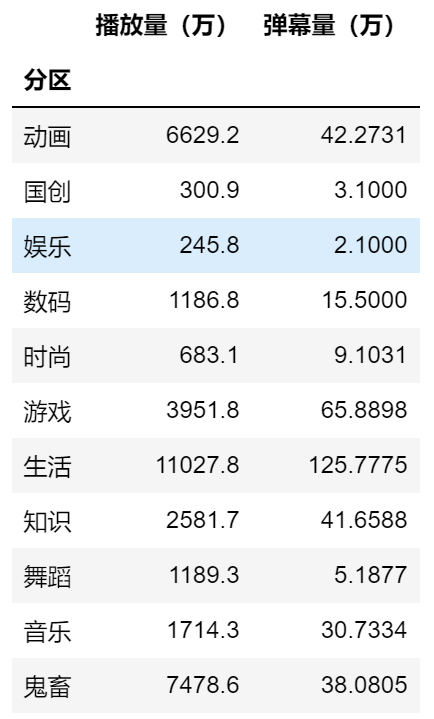
fig, axes = plt.subplots(figsize=(10,5),sharey=False)
axes.bar(data_class_playnum.index,data_class_playnum['播放量(万)'])
ax2 = axes.twinx()
ax2.plot(data_class_playnum.index,data_class_playnum['弹幕量(万)'],color='red')
axes.set_title("各分区播放量与弹幕量对比")
axes.set_ylabel("播放量(万)")
ax2.set_ylabel("弹幕量(万)")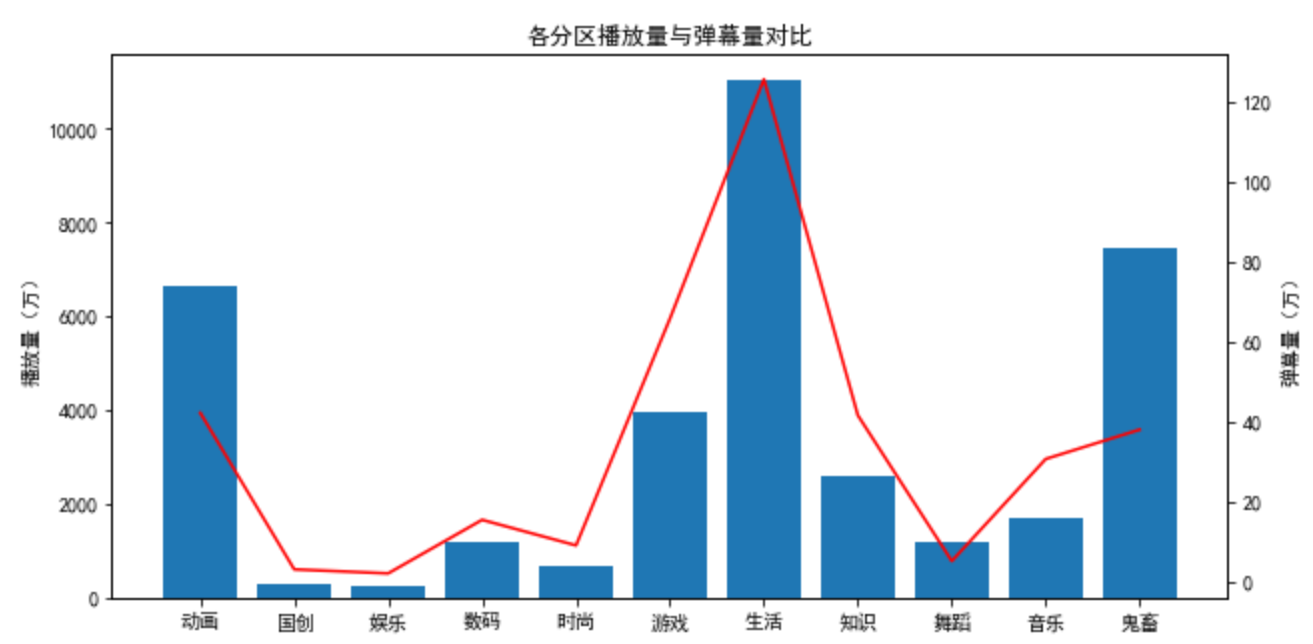
结论:生活类视频的播放量和弹幕量都非常高,而动画类和鬼畜类视频的弹幕差不多,知识类和游戏类视频播放量虽然不如前三名,但这两者的弹幕量相较而言比较突出(弹幕播放比)
最后
以上就是甜美长颈鹿最近收集整理的关于数据分析练习1导入模块2导入数据3数据处理 4数据可视化的全部内容,更多相关数据分析练习1导入模块2导入数据3数据处理 4数据可视化内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。







![[NCTF2019]True XML cookbook 什么是DTO?](https://www.shuijiaxian.com/files_image/reation/bcimg27.png)
发表评论 取消回复