载入数据
任务一:导入numpy和pandas
import numpy as np
import pandas as pd
任务二:载入数据
法一:
df = pd.read_csv('(t)train.csv')
df.head()

法二:
df = pd.read_csv('/Users/lenovo/Desktop/college/kaggle/data/泰坦尼克/(t)train.csv')
df.head()
输出结果与法一相同
思考:pd.read_csv()和pd.read_table()的不同
df = pd.read_table('(t)train.csv')
df.head()
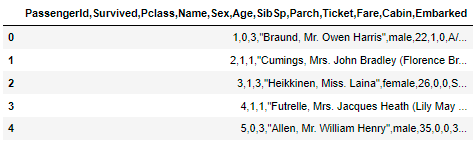
这是因为read_csv的默认分隔符为逗号,read_table的默认分隔符为制表符(“t”),若想要read_table 与read_csv的输出结果一样,可将代码改为以下形式:
df = pd.read_table('(t)train.csv',sep=',')
df.head()
任务三:每1000行为一个数据模块,逐块读取
什么是逐块读取?
逐块读取是将数据分成若干块,每一块有chunksize行
chunker=pd.read_csv('(t)train.csv',chunksize=1000)
chunker
任务四:将表头改成中文,索引改为乘客ID [对于某些英文资料,我们可以通过翻译来更直观的熟悉我们的数据]
df = pd.read_csv('train.csv', names=['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口'],index_col='乘客ID',header=0)
df.head()
初步观察
任务一:查看数据的基本信息
df.info()
def missing_value_summary(dataframe):
return dataframe.isna().sum() / dataframe.shape[0] * 100 ##查询缺失值的百分比
print(missing_value_summary(df))
任务二:观察表格前10行的数据和后15行的数据
df.head(10)
df.tail(15)
任务三:判断数据是否为空,为空的地方返回True,其余地方返回False
df.isnull()
保存数据
任务一:将你加载并做出改变的数据,在工作目录下保存为一个新文件train_chinese.csv
df.to_csv('train_chinese.csv')
查看DataFrame数据的每列的名称
df.columns

将[‘PassengerId’,‘Name’,‘Age’,‘Ticket’]这几个列元素隐藏,只观察其他几个列元素
df.drop(['PassengerId','Name','Age','Ticket'],axis=1).head(3)
drop与del函数的区别:
delete函数删除指定列,改变DataFrame的存储空间
drop函数在丢弃指定项时返回的是视图,并不会改变DataFrame本身的存储空间
筛选重要信息
我们以"Age"为筛选条件,显示年龄在10岁以下的乘客信息。
df[df['Age']<10]
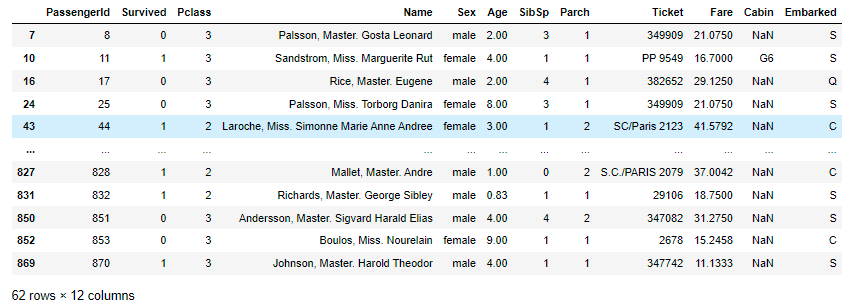
以"Age"为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage
midage = df[(df["Age"]>10)& (df["Age"]<50)]
midage.head(3)

pandas中的交集:年龄在10岁以上和50岁以下
(df[“Age”]>10)& (df[“Age”]<50)
pandas中的并集:年龄在10岁以上或50岁以下
(df[“Age”]>10) | (df[“Age”]<50)
将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来
midage = midage.reset_index(drop=True)
midage.head(3)

**reset_index 函数作用:**重置索引或其level,当数据帧具有多重索引时,此方法可以删除一个或多个level
midage.loc[[100],['Pclass','Sex']]

若先前不用reset_index函数,第100行的Pclass的值为3
使用loc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage.loc[[100,105,108],['Pclass','Name','Sex']]

使用iloc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来

对比iloc和loc的异同
区别:iloc是按照行索引所在的位置来选取数据,参数只能是整数。 而loc是按照索引名称来选取数据,参数类型依索引类型而定
参考:
[1]https://blog.csdn.net/dongfangzhixi/article/details/98080982
[2]https://blog.csdn.net/Asher117/article/details/86539966
[3]www.cnblogs.com/datasnail/archive/2018/10/08/9757081.html
最后
以上就是狂野大山最近收集整理的关于数据分析学习笔记(一)的全部内容,更多相关数据分析学习笔记(一)内容请搜索靠谱客的其他文章。








发表评论 取消回复