点击上方 月小水长 并 设为星标,第一时间接收干货推送
这是 月小水长 的第 45 篇原创干货
话题爬虫 WeiboTopicScrapy.py 开源以来,收到最多的反馈就是:为什么我爬了那么久,我的 topic 文件总是没有 csv 文件生成?

其实程序一运行起来,没有在控制台打印出每一页微博的具体信息,就可以断定你的操作方式出了问题,不必等上十几二十分钟。
我总结了话题爬虫所有可能的错误及解决办法,在此统一说明。
cookie 复制错了
话题爬虫是针对 weibo.cn 的,你需要在 weibo.cn 站的 login 页复制 cookie。
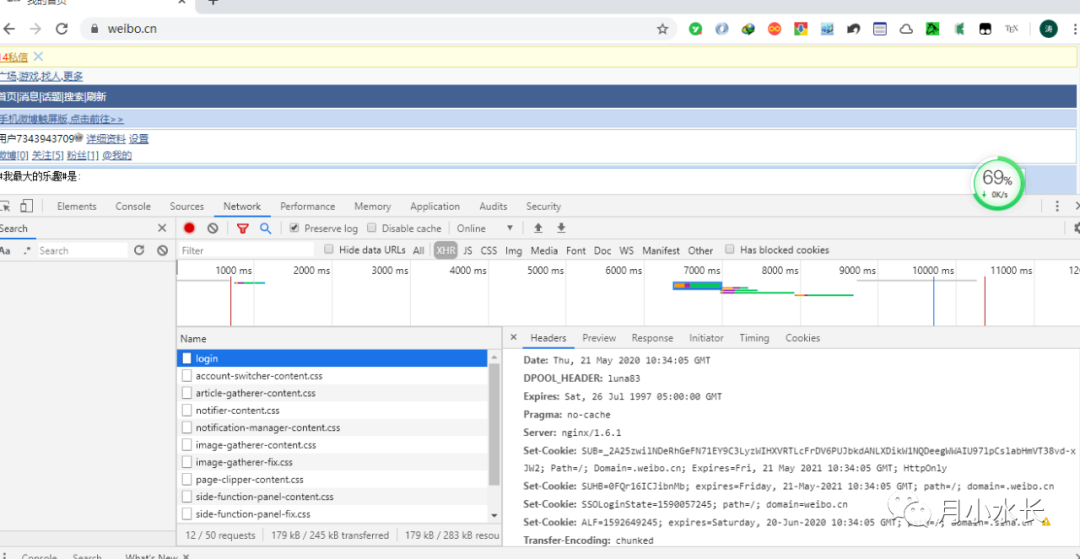
cookie 应该是包含 SUB 这个关键字段的,如果你复制了 m 站 cookie 或者没填 cookie 或者乱填 cookie,那么会出现以下错误:
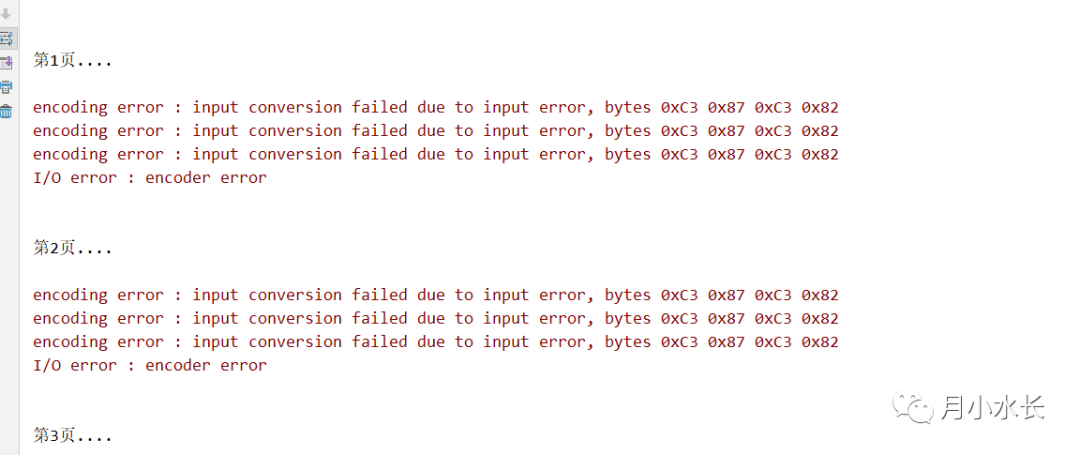
cookie 过期了
这个错误最明显的特征就是,我明明以前成功运行过的,今天运行却出现了下面这样的问题:

此时只需要重新去 weibo.cn 复制 cookie 就行。
cookie 没有过期还是出现了和 cookie 过期一样的空白
这个错误和 cookie 过期的差异在于,通常是在页码很大,比如 100 以上的情况,这个时候,有两个原因:
- 本次话题搜索的结果全部下载下来了,直接关掉程序就行。
- 一次搜索最多只能 100+ 页,如果把时间段切分成最小单位,即逐天搜索,如果总结果有几千页,我们可以修改 413 行处的代码:for page in range(1, pageNum): ,比如第一次 130 空白了,下次运行前,把这个 1 改成 130。
修改了一点小 Bug
当 filter=0 即抓取所有微博时,保存的 csv 文件表头和表格内容会错位,现已修复并推送 Github。最后
以上就是兴奋洋葱最近收集整理的关于爬虫cookie过期_为什么你的话题爬虫 topic 文件夹总是空的的全部内容,更多相关爬虫cookie过期_为什么你的话题爬虫内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复