1、推导反向传播算法



2、Relu激活函数的优缺点?
优点包括:
1、解决了梯度消失、爆炸的问题
2、计算方便,计算速度快,求导方便
3、加速网络训练
缺点包括:
1、由于负数部分恒为0,会导致一些神经元无法激活
2、输出不是以0为中心
3、Sigmoid函数与Softmax函数
从函数定义上来看,sigmoid激活函数的定义域能够取任何范围的实数,而返回的输出值在0到1的范围内。sigmoid函数也被称为S型函数。
f
(
x
)
=
1
1
+
e
−
x
f(x)=frac{1}{1+e^{-x}}
f(x)=1+e−x1
Sigmoid函数作用
Sigmoid函数用于逻辑回归模型中的二进制分类。
在创建人造神经元时,Sigmoid函数用作激活函数。
在统计学中,S形函数图像是常见的累积分布函数
softmax函数
Softmax的主要优点是输出概率的范围,范围为0到1,所有概率的和将等于1。如果将softmax函数用于多分类模型,它会返回每个类别的概率,并且目标类别的概率值会很大
f
(
x
)
=
e
x
i
∑
i
e
x
i
f(x)=frac{e^{x_{i}}}{sum_{i}e^{x_{i}}}
f(x)=∑iexiexi
Softmax作用
用于多重分类逻辑回归模型。
在构建神经网络中,在不同的层使用softmax函数。
4、梯度消失爆炸如何产生?怎么解决?
由于反向传播过程中,前面网络权重的偏导数的计算是逐渐从后往前累乘的,如果使用 sigmoid/tanh激活函数的话,由于导数小于一,因此累乘会逐渐变小,导致梯度消失,前面的网络层权重更新变慢;如果权重 w本身比较大,累乘会导致前面网络的参数偏导数变大,产生数值上溢。
解决方法
1、使用ReLU等激活函数,梯度只会为0或者1,每层的网络都可以得到相同的更新速度;
2、采用LSTM;
3、进行梯度裁剪(clip), 如果梯度值大于某个阈值,我们就进行梯度裁剪,限制在一个范围内;
4、使用正则化,这样会限制参数 w 的大小,从而防止梯度爆炸;
5、设计网络层数更少的网络进行模型训练;
6、batch normalization;
5、如何处理神经网络中的过拟合问题?
L2正则化
L2正则化可以解决模型训练中的过拟合现象,它也被称为权重衰减。在回归模型中,这也被称为岭回归。L2 正则化公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和。损失函数:
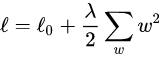
其中
L
0
L_0
L0表示没有正则化时的损失函数。对它求w的偏导:
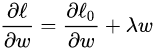
对w进行更新:
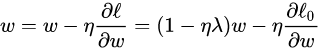
我们知道,没有正则化的参数更新为
w
=
w
−
η
∂
ℓ
0
∂
w
w = w - etafrac{partial{ell_0}}{partial{w}}
w=w−η∂w∂ℓ0,而L2正则化使用了一个乘性因子
(
1
−
η
λ
)
(1-{eta lambda})
(1−ηλ)去调整权重,因此权重会不断衰减,并且在权重较大时衰减地快,权重较小时衰减得慢。
L2正则化能够限制参数的大小。那么,为什么参数大小被限制了,这个模型就是一个简单的模型,就能够防止过拟合了呢?通过正则化学习,高次项前的系数 会变得很小,最后的曲线类似一条直线,这就是让模型变成了一个简单的模型。
总结:L2正则化通过权重衰减,保证了模型的简单,提高了泛化能力。
L1正则化—模型变得稀疏
L1 正则化公式直接在原来的损失函数基础上加上权重参数的绝对值:
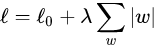
其中
L
0
L_0
L0表示没有正则化时的损失函数。对它求w的偏导:
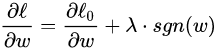
sgn(w)表示w的符号。对w进行更新:
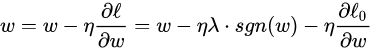
可以看出,L1正则化是通过加上或减去一个常量
η
λ
etalambda
ηλ,让w向0靠近;对比L2正则化,它使用了一个乘性因子
(
1
−
η
λ
)
(1-etalambda)
(1−ηλ) 去调整权重,使权重不断衰减。因此可以得出:当|w|很大时,L2对权重的衰减速度比L1大得多,当|w|很小时,L1对权重的缩小比L2快得多。
这也就解释了为什么L1正则能让模型变得稀疏L1对于小权重减小地很快,对大权重减小较慢,因此最终模型的权重主要集中在那些高重要度的特征上,对于不重要的特征,权重会很快趋近于0。所以最终权重w会变得稀疏。
Dropout
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
具体怎么让某些神经元以一定的概率停止工作(就是被删除掉)?
利用伯努利概率函数生成0或1的数让它的激活函数值以概率p变为0,从而实现概率控制节点不参与训练。
Dropout作用:1、取平均值,相当于训练多个模型,然后集成。2、减少神经元之间复杂的共适应关系:因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况
Dropout的缺点就在于训练时间是没有dropout网络的2-3倍。数据量小的时候效果不好。
Data Argumentation
过拟合的原因是学习样本太少,导致无法训练出能够泛化到新数据的模型。如果拥有无限的数据,那么模型能够观察到数据分布的所有内容,这样就永远不会过拟合
Early stop
6、Bert模型
第一,是这个模型非常的深,12层,并不宽(wide),中间层只有1024,而之前的Transformer模型中间层有2048。这似乎又印证了计算机图像处理的一个观点——深而窄 比 浅而宽 的模型更好。
第二,引入了MLM(Masked Language Model)
7、非平衡数据集的处理方法有哪些?
1、采用更好的评价指标,例如F1、AUC曲线等,而不是Recall、Precision;
2、进行过采样,随机重复少类别的样本来增加它的数量;
3、进行欠采样,随机对多类别样本降采样;
4、通过在已有数据上添加噪声来生成新的数据;
5、修改损失函数,添加新的惩罚项,使得小样本的类别被判断错误的损失增大,迫使模型重视小样本的数据;
最后
以上就是留胡子猎豹最近收集整理的关于深度学习基础知识总结(一)的全部内容,更多相关深度学习基础知识总结(一)内容请搜索靠谱客的其他文章。








发表评论 取消回复