主要内容
- 人工智能中的可解释性
- LIME算法思想
- LIME的前置条件
- LIME的目的
- 对于模型输出的可解释性(LIME)
- 对于模型行为的可解释性(SP-LIME)
人工智能中的可解释性
如今,机器学习乃至深度学习技术发展得如火如荼,各领域都能见到它们得身影,但是,大部分的模型对于人类而言,是一个“黑盒”,我们无从知晓模型运行背后的原理。这在许多场景下都不是一件好事,当我们希望利用模型作出某个决策时,良好的可解释性能够给我们更大的信心相信模型提供的输出,不仅如此,我们还能依据模型的可解释性去判断模型是否合理,甚至是对其加以改进。因此可解释性是一个很有意思的话题。
LIME算法思想
本文中提出的LIME全名为 Local Interpretable Model-agnostic Explanations,其基本思想是通过一个代理模型在某个“黑盒”模型的局部产生解释,从而让用户理解模型在当前局部的行为。所谓局部,实质上指的就是数据集中的一条样本。正因为这个特点,该算法是与模型无关的。并且,通过多个局部行为的解释,算法能让用户对模型的全局行为产生insight。
LIME的前置条件
首先,我们希望使用一个代理模型在局部对模型进行解释,因此,代理模型本身需要具备可解释性,即我们只能使用例如决策树,线性模型等具备高度可解释性的模型。
其次,由于我们是对一条样本进行解释,因此样本本身的形式也应当具备可解释性,文中以文本数据以及图像数据做例子,在NLP领域,文本大多使用词嵌入技术,变成了一个高维向量,此时不具备可解释性,因此,我们需要将其转换为具备可解释性的形式,比如词袋模型,而图像数据若以普遍的4维张量**[Batch,height,width,channel]** 来表示,同样不具备可解释性,这里我们将其转换为super-pixels的形式。super-pixels大概思想是将小像素聚合为更大的单位,如下图所示:

LIME的目的
此处,文章中提出一个观点,即可解释性有两个方面的意义,一是对于模型的输出本身的可解释性,但这只是在一个局部对模型进行解释,对理解模型本身的全局行为是不够的,因此,又有第二个方面的意义,即对模型本身(可理解为全局)的解释,试想有许多在验证集上表现良好的模型泛化性能却不行,因此,该算法提出从准确度以外的视角去观察模型是很有意思的观点。
对于模型输出的可解释性(LIME)
首先,是对于模型输出的解释,此处先定义一些符号:
黑盒模型:
f
f
f
可解释模型:
g
∈
G
g in G
g∈G
这里
G
G
G指的是一族可解释模型,而
g
g
g是其中一个,而在本文中,仅使用了线性回归这一可解释模型。
对于一个样例而言,其原本的表示记为
x
x
x,具备可解释性的形式记为
x
′
x'
x′,此时,一个样例的定义域为
{
0
,
1
}
{0,1}
{0,1},每一个维度都代表一个特征的存在与否,例如词袋模型表示某个单词是否存在,而图片则表示某个超像素是否存在。
对于可解释模型而言,我们还需要定义其复杂度,显然越简单的模型,其可解释性越高,在这,定义一个模型的复杂度为
Ω
(
g
)
Omega(g)
Ω(g),例如,决策树的复杂度由树的深度衡量,而线性模型则由其非零权重的个数来衡量。
在模型的局部,算法会产生一个扰动数据集,并用可解释模型来拟合,这些扰动数据采样自样本,做法是随机挑选样本中的非零特征构成扰动数据,即每一个扰动数据集中的数据都与原样本有一定相似之处。这个做法也是比较符合直觉的,用可解释模型拟合数据之间有相似特征的样本,从而观察黑盒模型做了什么。具体到线性模型来说,此时每一个扰动样本
z
′
z'
z′为可解释形式,我们需要将其转换为黑盒模型可接受的形式
z
z
z,并且每一个样本的标签就是黑盒模型对其的预测
f
(
z
)
f(z)
f(z)。
除此之外,还需要定义一个扰动样本与原样本之间相似程度的度量
π
x
(
z
)
pi_x(z)
πx(z)
综上,再定义一个衡量局部解释保真度的函数:
l
(
f
,
g
,
π
x
)
mathcal l(f,g,pi_x)
l(f,g,πx)
最后,将局部的保真度以及可解释模型本身的复杂度综合考量,最终,优化目标为:
ξ
(
x
)
=
a
r
g
m
i
n
g
∈
G
l
(
f
,
g
,
π
x
)
+
Ω
(
g
)
xi(x);=;underset{gin G}{argmin}mathcal l(f,g,pi_x);+;Omega(g)
ξ(x)=g∈Gargminl(f,g,πx)+Ω(g)
算法流程:

算法核心即根据上文中的
π
x
pi_x
πx对样本周围进行采样,从而形成一个扰动数据集
Z
Z
Z,在该数据集上,进行线性模型的拟合。而图中的K-Lasso是一种特征选择的算法,从而能够使用部分而不是全部特征进行拟合。最终我们得到一个稀疏的线性模型。这个模型的权重即为我们所要的解释。
对于模型行为的可解释性(SP-LIME)
在局部,我们仅对一个样例上,模型的行为进行了解释,但是这无法从整体上看出模型的行为,因此,我们需要多一些样本来帮助我们观察模型的行为。但是,选择合适的样例对于用户来说是一个门槛较高的事情,因此文中提出了SP(submodular-pick)LIME算法,自动地搜索合适的样例。
在该算法中,首先需要定义一个由各个样本的LIME所构成的“解释”矩阵
W
W
W
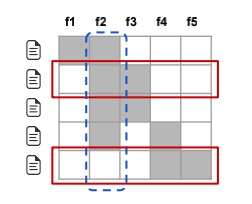
图中,每一行代表一个样本的解释,每一列代表一个特征,即解释中的一个权重。而算法挑选样例主要从两方面来考虑,首先是特征的多样性,即挑选出来的样例应该具有丰富的特征,二是特征的重要性,即挑选出来的特征应该在模型的决策过程有相当的话语权。
以上图举例,若该算法能够充分考虑多样性,则第二个样例与第三个样例仅有一个会被挑选出来,因为它们的解释非常相似,无法为解释模型行为提供更多信息。
对于重要性,对每个特征,定义重要性衡量函数
I
(
x
j
)
I(x_j)
I(xj),文中以文本数据举例,则该函数简单定义为
∑
i
∈
N
w
i
j
sqrt {sum_{iin N} w_{ij}}
i∈N∑wij即将特征对应的所有权重求和并开平方。
具体算法流程如下:

其中,Eq.4的式子为:
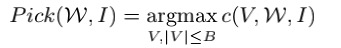
c
c
c的定义为:
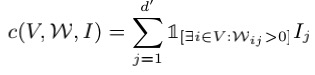
该式子含义为:给定样本集合
V
V
V重要性衡量函数
I
I
I以及“解释”矩阵
W
W
W计算其总体的重要性,式子中间的指示函数就体现了算法中的多样性,即只要在解释矩阵中有一个属性在一个样例上权重大于0,那么总体重要性就会将其考虑进去。而
P
i
c
k
Pick
Pick函数中的
B
B
B代表的是用户能容忍的最大样例个数。
这样,最大化总体重要性,就得到了一系列的优质样本,帮助用户理解模型。而SP-LIME也在实验中确实比RP-LIME(Random Pick)发挥了更好的作用。
最后
以上就是落后板栗最近收集整理的关于LIME-论文阅读笔记人工智能中的可解释性LIME算法思想LIME的前置条件LIME的目的的全部内容,更多相关LIME-论文阅读笔记人工智能中内容请搜索靠谱客的其他文章。








发表评论 取消回复