文本分类主要流程
获取数据集
- 使用爬虫从网上获取。
- 下载某些网站整理好的数据集。
- 公司内部数据资源。
数据预处理
数据预处理是按照需求将数据整理出不同的分类,分类预测的源头是经过预处理的数据,所以数据预处理非常重要,会影响到后期文本分类的好坏。
预处理主要分为以下几个步骤:
- 将数据集按类别做好不同分类
- 将分类好的数据集分为训练集和测试集
- 去除数据集中的空字段或对空字段添加标识
- 对文本进行分词
1. 加载自己需要的分词词典和停用词(使后期模型更加简单、准确)
2. 去除无用的字符符号
3. 进行分词
特征提取
对于文本分类的特征提取目前主要有Bag of Words(词袋法)、TfIdf、Word2Vec、Doc2Vec。
词袋法介绍
对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。没有考虑到单词的顺序,忽略了单词的语义信息。
TfIdf算法介绍
除了考量某词汇在文本出现的频率,还关注包含这个词汇的所有文本的数量,能够削减高频没有意义的词汇出现带来的影响,挖掘更有意义的特征,相对词袋法来说,文本条目越多,Tfidf的效果会越显著。缺点也是没有考虑到单词的顺序。
Word2Vec算法介绍
Word2Vec的优点就是考虑了一个句子中词与词之间的关系,关于两个词的关系亲疏,word2vec从两个角度去考虑。第一,如果两个词意思比较相近,那么他们的向量夹角或者距离(比如欧几里得距离)是比较小的,举个例子,"king"用(0,1)表示,"queen"用(0,1.1)表示,那么他们的距离就是0.01,这就意味着两者是有很大关联的。第二,如果两个词意思比较接近,那么他们也有更大的可能出现在同一个句子中,甚至两个词可以相互替换句子的意思也不会改变。
word2vec是一个众所周知的概念,用于将单词转换成用户向量来表示。
关于word2vec有很多关于word2vec的好教程,比如这个和还有这个,但是如果描述doc2vec时不涉word2vec的话会忽视很多东西,所以在这里我会给word2vec做个简介。
一般来说,当你想用单词构建一些模型时,只需对单词进行标记或做独热编码,这是一种合理的方法。然而,当使用这种编码时,词语的意义将会失去。例如,如果我们将“巴黎”编码为id_4,将“法国”编码为id_6,将“权力”编码为id_8,则“法国”将与“巴黎”具有“法国”和“权利”相同的关系。但事实上我们更希望在词义上“法国”和“巴黎”比“法国”和“权力”更接近。
word2vec,在本文中于2013年提出,旨在为您提供:每个单词的向量化表示,能够捕获上述关系。这是机器学习中更广泛概念的一部分 - 特征向量。
这种表示形式包含了单词之间的不同关系,如同义词,反义词或类比,如下所示:
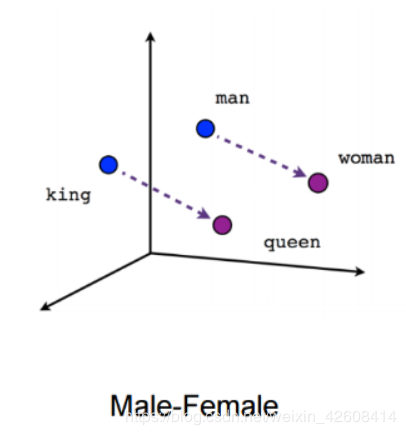
国外与王后就像于男人与女人,
word2vec有2种算法:连续词袋模型(CBOW)和Skip-Gram模型。
连续词袋模型(CBOW)
连续词袋模型会在当前单词的周围创建一个滑动窗口,从“上下文” 也就是用它周围的单词预测当前词。 每个单词都表示为一个特征向量。 经过训练以后后,这些向量就成为单词向量。
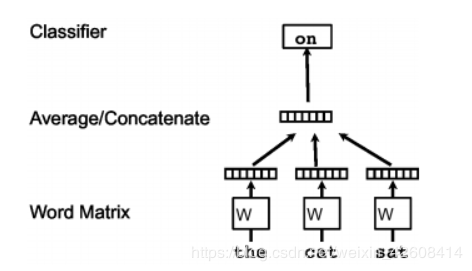
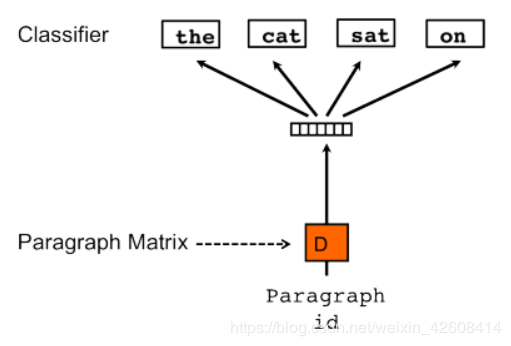
用周围的(上下文)单词“the”“cat”“sat”来预测当前的单词“on”
Skip gram
第二种算法(在同一篇论文中描述,并且在这里很好地解释)实际上与CBOW相反:我们不是每次都预测一个单词,而是使用1个单词来预测周围的单词。 Skip gram比CBOW慢得多,但是对于不经常使用的单词,它被认为更准确。
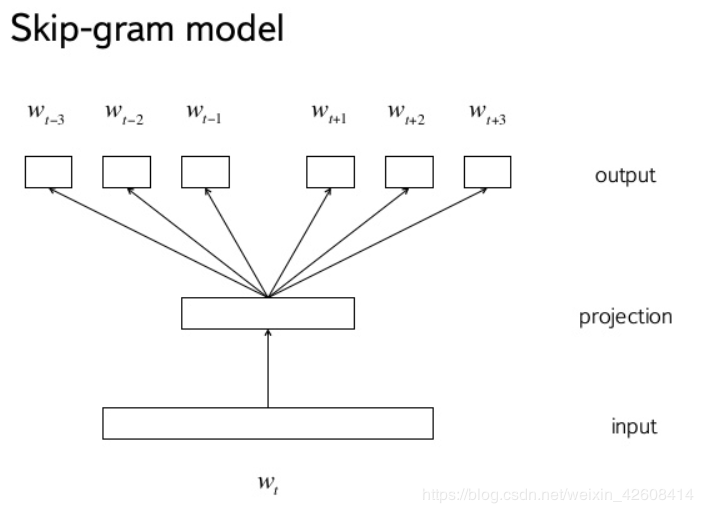
用一个词来预测它周围的词
Doc2Vec算法介绍
在了解word2vec之后,将更容易理解doc2vec的工作原理。
如上所述,doc2vec的目标是创建文档的向量化表示,而不管其长度如何。 但与单词不同的是,文档并没有单词之间的逻辑结构,因此必须找到另一种方法。Mikilov和Le使用的概念很简单但很聪明:他们使用了word2vec模型,并添加了另一个向量(下面的段落ID),如下所示:
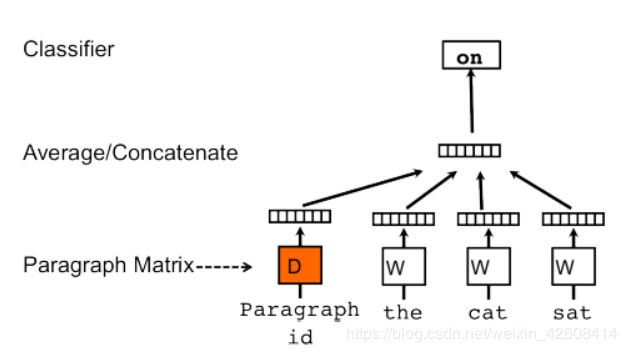
如果您对上面的草图感到熟悉,那是因为它是CBOW模型的一个小扩展。 它不是仅是使用一些单词来预测下一个单词,我们还添加了另一个特征向量,即文档Id。
因此,当训练单词向量W时,也训练文档向量D,并且在训练结束时,它包含了文档的向量化表示。
上面的模型称为段落向量的分布式记忆的版本(PV-DM)。 它充当记忆器,它能记住当前上下文中缺少的内容 - 或者段落的主题。 虽然单词向量表示单词的概念,但文档向量旨在表示文档的概念。
该算法实际上更快(与word2vec相反)并且消耗更少的内存,因为不需要保存词向量。
在论文中,作者建议使用两种算法的组合,尽管PV-DM模型是优越的,并且通常会自己达到最优的结果。
doc2vec模型的使用方式:对于训练,它需要一组文档。 为每个单词生成词向量W,并为每个文档生成文档向量D. 该模型还训练softmax隐藏层的权重。 在推理阶段,可以呈现新文档,并且固定所有权重以计算文档向量。
文本的特征提取特别重要,体现这个系统做的好坏,分类的准确性,文本的特征需要自己构建,常用的可以用n-gram模型,ti-idf模型。但是这些模型共同的特点就是太稀疏了。一般情况下需要降维,比如SVD,其实很多模型也可以用来进行特征选择比如决策树,L1正则也可以用来进行特征选择,具体原理这里就不讲了。是不是很复杂,其实已有一个强大的工具帮我们做好了 sklearn,超级好用。
获取分类器
至此数据应该还算是比较干净了,可以开始做下一步工作。对样本数据进行分类。
文本分类常用算法
逻辑回归
算法简介:
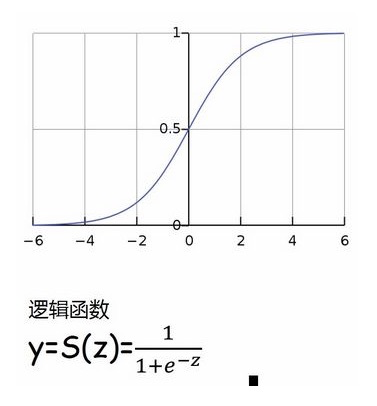
逻辑回归与线性回归不同,虽然名为回归,但逻辑回归主要是用来解决分类任务的。线性回归输出特征向量Y和输入样本矩阵X之间的线性关系系数θ,满足Y=θX,所以Y是连续的。逻辑回归通过sigmoid函数对Y又做了一次函数转换,即g(Y),如果g(Y)的值在某个实数区间是类别A,在另一个实数区间是类别B,那么我们就得到了一个分类模型。
优点:
- 实现简单,广泛的应用于工业问题上。
- 分类时计算量非常小,速度很快,存储资源低。
- 便利的观测样本概率分数。
- 对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决该问题。
- 计算代价不高,易于理解和实现。
缺点:
- 当特征空间很大时,逻辑回归的性能不是很好。
- 容易欠拟合,一般准确度不太高。
- 不能很好地处理大量多类特征或变量。
- 只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分。
- 对于非线性特征,需要进行转换。
朴素贝叶斯
算法简介:
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
朴素贝叶斯的核心算法贝叶斯公式:
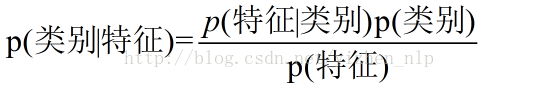
最终求得p(类别|特征),相当于完成了任务。
优点:
- 朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。
- 对小规模的数据表现很好,能处理多分类任务,适合增量式训练,尤其是数据量超出内存时,可以一批批的去增量训练。
- NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单,常用于文本分类。
- 分类过程中时空开销小
缺点:
- 理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的(可以考虑用聚类算法先将相关性较大的属性聚类),这给NBC模型的正确分类带来了一定影响。在属性个数比较多或者属性之间相关性较大时,NBC模型的分类效率比不上决策树模型。而在属性相关性较小时,NBC模型的性能最为良好。
- 需要知道先验概率。
- 由于是通过先验概率和数据来决定后验的概率从而决定分类,所以分类决策存在错误率 。
- 对输入数据的表达形式很敏感。
随机森林
算法简介:
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
优点:
- 训练可以高度并行化,对于大数据时代的大样本训练速度有优势。
- 由于可以随机选择决策树节点划分特征,这样在样本特征维度很高的时候,仍然能高效的训练模型。
- 在训练后,可以给出各个特征对于输出的重要性。
- 由于采用了随机采样,训练出的模型的方差小,泛化能力强。
- 相对于Boosting系列的Adaboost和GBDT, RF实现比较简单。
- 对部分特征缺失不敏感。
- 对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化。
- 在创建随机森林的时候,对generlization error使用的是无偏估计。
- 训练过程中,能够检测到feature间的互相影响。
缺点:
- 在某些噪音比较大的样本集上,RF模型容易陷入过拟合。
- 取值划分比较多的特征容易对RF的决策产生更大的影响,从而影响拟合的模型的效果。
Adaboosting
算法简介:
Adaboosting是集成算法中的一种,其中的A是adaptive的意思,所以AdaBoosting表示自适应增强算法。Adaboosting算法可以将弱分类器通过数次迭代增强为强分类器。Adaboosting算法在每一步弱分类器收敛后,会将错误的分类权重加大,错误率越高,对应得到的当前弱分类器权重越小,最后按照权重将每一个弱分类器组合起来就是Adaboosting的结果。
优点:
- adaboost是一种有很高精度的分类器。
- 可以使用各种方法构建子分类器,Adaboost算法提供的是框架。
- 当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单。
- 简单,不用做特征筛选。
- 不用担心overfitting。
缺点:
- 对outlier比较敏感
SVM(支持向量机)
算法简介:
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
优点:
- 可以解决小样本情况下的机器学习问题。
- 可以提高泛化性能。
- 可以解决高维问题。
- 可以解决非线性问题。
- 可以避免神经网络结构选择和局部极小点问题。
缺点:
- 对缺失数据敏感。
- 对非线性问题没有通用解决方案,必须谨慎选择Kernelfunction来处理。
- 内存消耗大,难以解释。
- 运行和调差略烦人。
最后
以上就是壮观背包最近收集整理的关于使用机器学习做文本分类知识点总结文本分类主要流程文本分类常用算法的全部内容,更多相关使用机器学习做文本分类知识点总结文本分类主要流程文本分类常用算法内容请搜索靠谱客的其他文章。








发表评论 取消回复