5.1 方差和偏差
方差:预测结果的方差
偏差:预测结果和真实值之间的差距
需要低方差、低偏差的模型
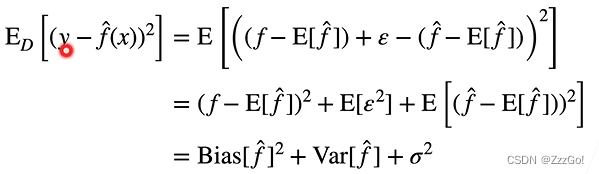
第一项为偏差,第二项为方差
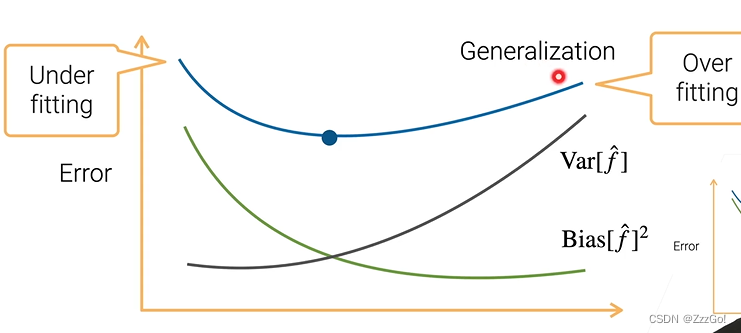
减小泛化误差
- 减小偏差:设计更加复杂的模型,例如增加神经网络的层数、隐藏单元,Boosting、Stacking
- 减小方差:更简单的模型,使用L1L2正则项,Bagging、Stacking
- 减小噪音σ平方:提升数据质量
Boosting、Stacking、Bagging属于集成学习Ensemble learning
5.2 Bagging-Bootstrap AGGregatING
Bagging并行训练n个base learner,然后通过平均learner的输出(回归问题)或者多数投票(分类)进行决策。每个learner在经过Bootstrap采样的数据上进行训练。
Bootstrap采样:假设有m个训练样本,有放回地从数据中随机采样m个样本。那么大概有1-1/e≈63%的样本会被采样到,剩下的部分(未被采样到的数据out-of-bag)用于验证。

Bagging降低方差,当base learner不那么稳定的时候(例如决策树),bagging对于降低方差的效果更好。
5.3 Boosting
把多个弱模型组合在一起得到更强的模型,减小偏差
Boosting按顺序学习n个弱模型,在第i步中,训练弱模型h_i,评估它的误差;根据误差的情况重新采样数据,多关注预测不正确的样本。
经典算法:AdaBoost、Gradient Boosting
Gradient Boosting:H_t(x)表示时刻t的模型,H_1(x)=0。在时刻t=1,2,3,…时,在残差数据{(xi, yi-H_t(xi))}i=1,…,m 上训练一个新模型ht,H_(t+1)(x)=H_t(x)+θht(x),学习率θ通过收缩正则化模型。如果选择MSE作为损失函数,残差部分就等于负梯度方向。
其他Boosting算法可以通过选择不同的函数空间(损失函数)很容易地换到Gradient Boosting的框架里
GBDT:使用小一点的决策树作为base learner,降低过拟合风险
顺序建树太慢了,可以使用加速算法,如XGBoost,lightGBM
5.4 Stacking(比较贵)
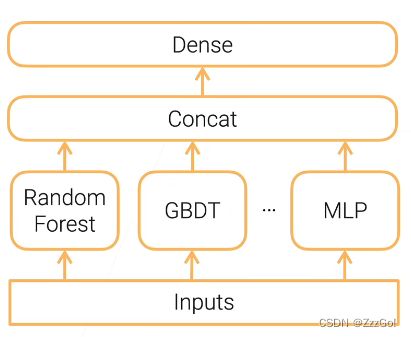
单层Stacking:把多个base learner组合在一起降低方差,在同样的数据集上训练不同的模型,把不同模型的输出concat起来,经过全连接层得到最终的结果。
跟bagging的区别:①不需要经过Bootstrap采样 ②学习的模型是不同类型的
多层Stacking:降低偏差,特别容易过拟合
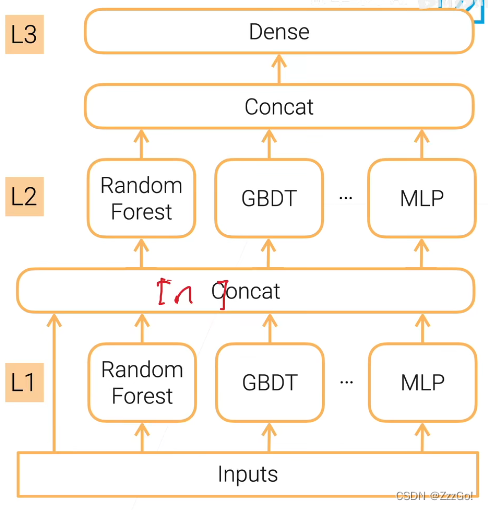
降低过拟合风险的方法:
- 划分训练数据集,不同层stacking采用不同的训练集
- 重复的k折bagging:假设有k个模型,把数据集分成k份,k-1份用于训练,1份用于验证。假设第i个模型是在第 i 块数据上做了验证,那么把第 i 个模型在第 i 块数据上的输出作为预测输出,把所有模型的预测并起来,进入到下一层进行训练。(进一步降低方差的方法:重复上述步骤n次,把n次的预测结果取平均,再进入到下一层进行训练)
| Reduce | Variance | Bias | Computation cost | Parallelization |
| Bagging | Y | n | n | |
| Boosting | Y | n | 1 | |
| Stacking | Y | n | n | |
| K-fold multi-level stacking | Y | Y | n*L*k | n*k |
最后
以上就是懦弱苗条最近收集整理的关于跟李沐学AI:实用机器学习 | 第五章5.1 方差和偏差5.2 Bagging-Bootstrap AGGregatING5.3 Boosting5.4 Stacking(比较贵)的全部内容,更多相关跟李沐学AI:实用机器学习内容请搜索靠谱客的其他文章。








发表评论 取消回复